掌握Spark执行机制:从提交到Task执行详解
92 浏览量
更新于2024-08-30
收藏 823KB PDF 举报
Spark学习笔记深入探讨了Spark的工作执行机制,这是一种高效的大数据处理框架。首先,理解Spark执行机制的核心在于其作业调度过程。当用户提交一个Spark应用程序(application)时,这个过程包括以下几个关键步骤:
1. **RDD Action算子触发**:用户对RDD(弹性分布式数据集)的Action操作(如collect、count等)会触发一个job的提交,此时,应用程序的逻辑被转换成一个RDD Directed Acyclic Graph (DAG)。这个DAG表示了数据流和计算顺序。
2. **Job生成和Stage划分**:DAGScheduler将RDD DAG进一步转换为Stage DAG,每个Stage是一组具有相同输入的Task集合。这种划分有助于减少跨Stage的shuffle操作,提高性能。
3. **TaskScheduler与Executor**:每个Stage的Task会被TaskScheduler分配到Executor(执行器)上执行。Executor是运行用户代码的实体,它包含一个线程池来执行Tasks,并且负责数据的本地缓存。
4. **应用执行模式**:Spark支持多种执行模式,如Local(单机模式)、Standalone集群、YARN或Mesos,取决于Driver Program是在集群中的哪个节点运行,这决定了是Client模式还是Cluster模式。
5. **Driver与Executor交互**:在Driver模式下,Driver进程在客户端启动,负责应用程序的初始化和监控。它与Master进行通信,Master则指挥Worker启动Executor。Executor通过Executor-Runner线程与Driver保持连接,接收Task并执行它们。
6. **任务提交与执行流程**:在客户端Driver模式下,流程涉及用户启动客户端、Driver的初始化、DAGScheduler组件的启动,以及Driver向Master注册。Master会协调资源,安排Worker启动Executor并执行Tasks。
Spark的工作机制围绕着RDD的分布式存储和计算展开,通过Stage和Task的划分实现了高效的并行处理,同时考虑了各种不同的应用程序执行模式。理解和掌握这些原理是学习Spark编程和优化性能的关键。
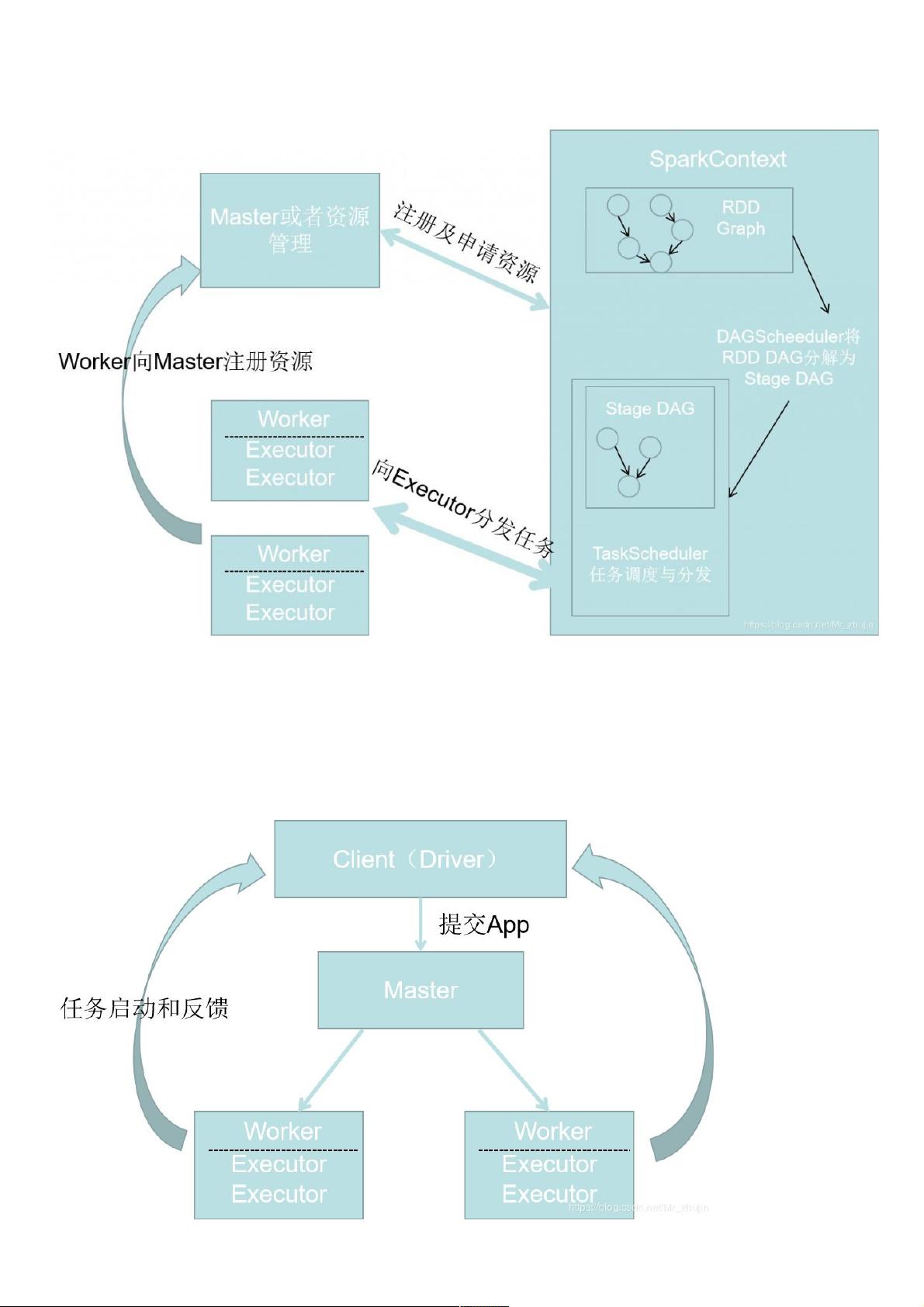
Spark学习笔记学习笔记—Spark工作机制工作机制
一一.Spark执行机制执行机制
1.执行机制总览执行机制总览
Spark应用提交后经历一系列转变,最后成为task在各个节点上执行。
RDD的Action算子触发job的提交,提交到Spark的Job生成RDD DAG,由DAGScheduler转换为Stage DAG,每个Stage中产生相应的Task集合,TaskScheduler将任务分发到
Executor执行。每个任务对应的数据块,使用用户定义的函数进行处理。
2.Spark应用的概念应用的概念
Spark应用(application)是用户提交的应用程序,执行模式有Local,Standalone,YARN,Mesos。根据Application的Driver Program是否在集群中运行又分为Cluster模式和Client模
式。包含的组件如下:
Application:用户自定的Spark程序,提交后Spark为App分配资源将程序转换并执行。
Driver Program:运行Application的main()函数并创建SparkContext.
RDD Graph:当RDD遇到Action算子,将之前所有算子形成一个有向无环图DAG,在Spark中转换为Job并提交到集群中处理,一个App可以包含多个Job.
Job:一个RDD Graph触发的作业,在SparkContext中通过runJob方法提交。
Stage:每个Job会根据RDD的宽依赖关系被切分为很多Stage,每个Stage包含一组相同的Task,这一组Task也叫做TaskSet。
Task:一个分区对应一个Task,Task执行RDD中对应Stage中包含的算子。Task被封装好后放入Executor的线程池中执行。
3.应用的提交与执行方式应用的提交与执行方式
应用的提交方式分为以下两种:
Driver进程运行在客户端;主节点指定某个Worker节点启动Driver,负责整个应用的监控。
(1).Driver运行在客户端运行在客户端
流程描述如下:
1.用户启动客户端后,客户端运行程序,启动Driver。在Driver中启动或者实例化DAGScheduler等组件。客户端的Driver向Master注册。
2. Worker向Master注册,Master命令Worker启动Executor。Worker通过创建Executor-Runner线程,在ExecutorRunner线程内部启动ExecutorBackend进程。
下载后可阅读完整内容,剩余6页未读,立即下载
2022-08-07 上传
2017-08-04 上传
2021-05-26 上传
2021-05-26 上传
2017-11-09 上传
2021-01-20 上传
2017-11-09 上传
2020-08-25 上传

weixin_38691006
- 粉丝: 3
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
