优化HNSW与IVF-HNSW:近似最近邻搜索算法新进展
版权申诉
201 浏览量
更新于2024-07-04
收藏 1.14MB PDF 举报
"近似最近邻搜索算法研究与应用"
近似最近邻(Approximate Nearest Neighbor, ANN)搜索算法是一种在大数据集上寻找最相似对象的高效技术,广泛应用于搜索与推荐系统、图像识别、自然语言处理等领域。刘凤山同学在导师申富饶教授的指导下,针对这一算法进行了深入研究和优化。
首先,HNSW(Hierarchical Navigable Small World)是目前在ANN领域中表现优异的基于图的算法。它通过构建多层的图结构,使得搜索效率大大提高。然而,HNSW在处理动态数据时存在两个主要问题:一是当搜索起点的邻居被标记为删除后,可能导致搜索停止,返回零个结果;二是内存占用过大,特别是对于高维向量和图结构的存储需求。
为了解决HNSW的删除操作问题,刘凤山提出了一种改进策略。当节点被删除时,不仅需要标记删除,还需要找出所有指向被删除节点的边,并将这些边的起点也进行适当处理。具体来说,可以将被删除节点的坐标设置为无穷远,确保搜索不会被错误地终止。同时,受影响较大的节点可能需要重新插入,以维护图结构的完整性和搜索性能。这种优化策略通过全局搜索和节点重新插入,确保了即使在有节点删除的情况下也能返回正确的近似最近邻结果。
针对HNSW的内存开销问题,刘凤山进一步提出了对IVF-HNSW(Inverted File HNSW)的优化。IVF-HNSW结合了倒排索引(Inverted File)和HNSW,旨在减少内存消耗。它的基本思路是先对数据集进行聚类,将数据分配到不同的桶中,然后只在少量选定的桶内进行HNSW搜索。同时,为了进一步降低存储需求,通常会对数据进行量化压缩。在搜索过程中,首先在聚类中心的HNSW索引中找到最近的几个聚类中心,然后仅搜索这些中心对应的桶,直至达到预设的访问上限或搜索完所有桶。
此外,IVF-HNSW还引入了矢量量化技术,即将高维向量分解为多个子向量,并对每个子空间学习到的K个代表点进行编码。这样,数据可以通过选取最近的代表点进行压缩,既降低了存储需求,又在一定程度上保持了相似性。
刘凤山的研究针对HNSW算法在实际应用中遇到的问题,提出了有效的解决方案,包括改进删除操作和优化内存管理,以提高近似最近邻搜索的准确性和效率。这些优化措施对于处理大规模高维数据集的实时搜索需求具有重要意义,可广泛应用于需要快速相似性查找的各种场景。
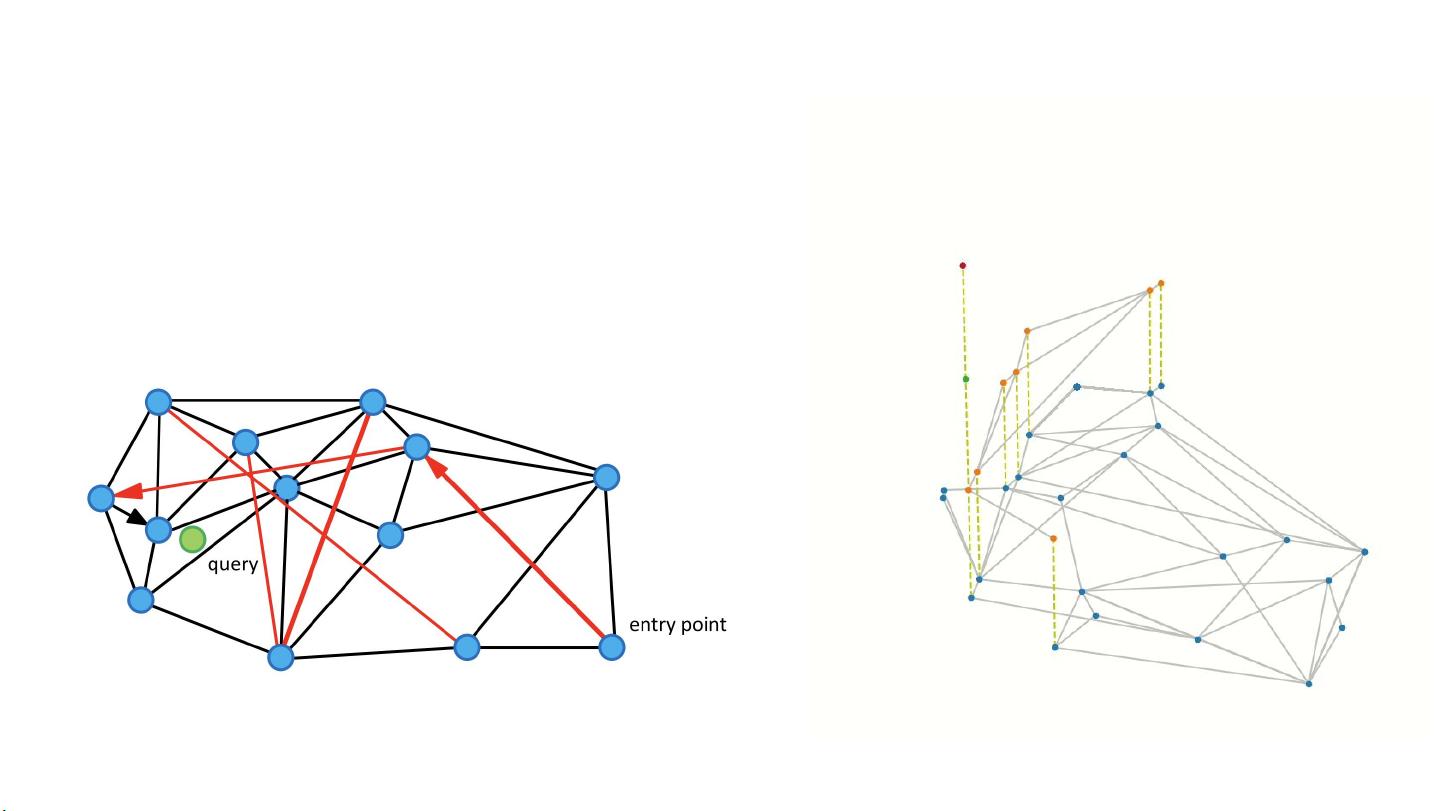
HNSW
基于图的算法,目前最好的算法之
一。
https://github.com/NJU-RINC/hnsw-visulize
剩余19页未读,继续阅读
2256 浏览量
2022-08-04 上传
590 浏览量
2024-08-18 上传
412 浏览量
点击了解资源详情
点击了解资源详情
153 浏览量
点击了解资源详情

wwwarewow
- 粉丝: 4673
- 资源: 2532
 我的内容管理
展开
我的内容管理
展开







