MapReduce入门:大数据处理的关键技术
版权申诉
164 浏览量
更新于2024-07-05
收藏 1.26MB PDF 举报
"MapReduce 大数据 入门 学习"
MapReduce是一种分布式计算框架,由Google在2004年提出,主要用于处理和生成大规模数据集。它将复杂的、大规模的数据处理任务拆分成可并行执行的子任务,使得在多台计算机(节点)上并行处理成为可能,极大地提升了大数据分析的效率。MapReduce的核心思想是“分而治之”(Divide and Conquer)。
Map阶段是将原始数据集分解成多个小块,并对每个小块应用一个映射函数(Map Function),这个函数通常用于过滤和转换输入数据,将其转化为键值对(Key-Value Pair)的形式。映射函数的结果被临时存储,通常在本地节点上。
Reduce阶段则负责聚合Map阶段产生的键值对,对相同的键进行归并处理,执行一个化简函数(Reduce Function)。这个过程汇总了所有相关键的所有值,并产生最终的输出结果。Reduce阶段确保了数据的整合和总结,输出的是最终的分析结果。
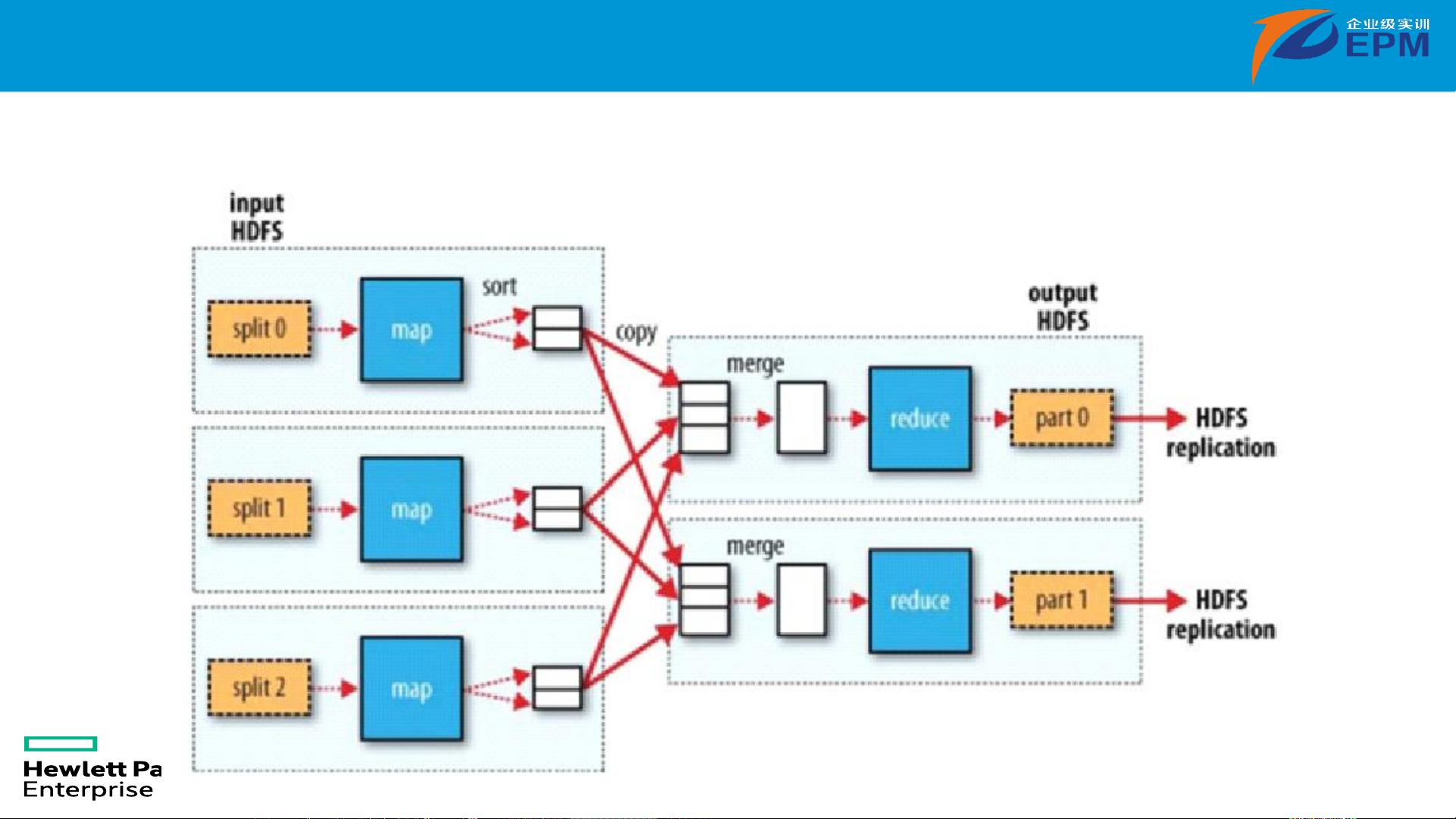
MapReduce运行流程如下:
1. 数据切片:输入数据被分割成若干小块,分配给各个Mapper。
2. 映射(Mapping):Mapper接收到数据块,执行映射函数,生成中间键值对。
3. 溢出和排序:Mapper将中间键值对暂存到磁盘,并进行排序,准备传输给Reducer。
4. 混洗(Shuffle):数据根据键进行分区和排序,确保相同键的值被发送到同一个Reducer。
5. 归约(Reducing):Reducer接收来自Mapper的键值对,执行化简函数,生成最终结果。
6. 输出:Reducer的结果写入到输出文件,完成整个MapReduce任务。
MapReduce实例:例如,统计一段文本中单词出现频率。Map阶段,Mapper读取文本行,分割单词,形成<单词, 1>的键值对;Reduce阶段,Reducer接收所有同一单词的计数,累加它们,给出每个单词的总频次。
MapReduce编程模型:开发者需要实现Map和Reduce两个接口,Map接口定义如何处理单个输入记录,Reduce接口定义如何聚合Map的输出。此外,还有可选的Combiner(本地化Reduce)和Partitioner(控制数据分发)组件,可以提高效率和并行度。
MapReduce内部逻辑还包括容错机制,如工作节点(Mapper/Reducer)故障时,其任务会自动重试,保证计算的正确性。此外,数据复制策略(通常是3副本)保证了数据的高可用性。
在大数据时代,MapReduce是处理PB级别数据的有效工具,广泛应用于搜索引擎索引构建、日志分析、机器学习等领域。尽管随着Spark、Flink等新一代计算框架的崛起,MapReduce的实时处理能力相对较弱,但它依然是理解分布式计算和大数据处理的重要基础。

输入(格式化k,v)数据集map映射成一个中间数据集(k,v)reduce
相同的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算。
MapReduce语义(原语)
剩余42页未读,继续阅读
2022-03-09 上传
2022-06-21 上传
2021-06-24 上传
2013-09-17 上传
180 浏览量
2024-03-05 上传
2018-09-06 上传
2024-03-04 上传
2024-03-05 上传

cxqlcx
- 粉丝: 0
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
