MongoDB副本集深度解析:内部机制与故障转移
183 浏览量
更新于2024-08-28
收藏 226KB PDF 举报
本文主要探讨了MongoDB副本集的内部机制,特别是其高可用性和故障转移功能。重点讲解了副本集的选举机制,包括Bully算法的原理以及选举过程。
在MongoDB副本集中,主节点的选举是一个关键过程,确保在主节点失效时能快速、有效地切换到新的主节点以保持服务的连续性。Bully算法在此中扮演了重要角色,它允许集群中的任何节点在原主节点失效后有机会成为新的主节点。这种算法的核心是通过节点间的通信和比较,依据某种属性(如节点ID或最新事务ID)来决定哪个节点应该成为新的主节点。
副本集通常建议设置为奇数个节点,这是因为当存在偶数节点时,选举过程中可能因为票数相等而出现僵局,导致无法选出新主,从而影响服务的可用性。奇数节点能确保在正常情况下总有一方票数过半,从而避免这种情况。
MongoDB的副本集同步策略是通过复制日志实现的,主节点将写操作记录在复制日志中,从节点则不断地从主节点拉取这些日志并应用到自己的数据中。如果同步不及时,可能会导致从节点的数据落后于主节点,形成数据滞后。在极端情况下,如果同步长时间滞后,可能导致从节点与主节点之间出现数据不一致,影响数据的完整性。
故障转移是自动触发的,当主节点检测到自身无法服务或者大多数副本集成员认为主节点失联时,就会开始选举过程。频繁的故障转移确实可能增加系统的负载,因为每次选举都需要进行大量的网络通信和计算。然而,这通常是避免不了的,因为快速恢复服务比保持短暂的不可用状态更为重要。
选举过程大致如下:每个节点首先检查自己是否有资格成为候选人,然后向其他节点发送声明,包含自身的“优先级”(如ID或事务ID)。收到声明的节点比较自身和其他节点的优先级,投票给优先级更高的节点。一旦一个节点获得超过半数的选票,它就被确认为新的主节点,并开始接收和处理客户端请求。
MongoDB的副本集设计和Bully算法确保了高可用性,即使在单个节点故障的情况下也能快速恢复服务。理解这些内部机制对于维护稳定、可靠的MongoDB集群至关重要。
搭建高可用搭建高可用mongodb集群(三)集群(三)——深入副本集内部机制深入副本集内部机制
该系列文章的第一部分介绍了副本集的配置,这个部分将深入研究一下副本集的内部机制。还是带着副本集的问题来看吧!
副本集故障转移,主节点是如何选举的?能否手动干涉下架某一台主节点。
官方说副本集数量最好是奇数,为什么?
MongDB副本集是如何同步的?如果同步不及时会出现什么情况?会不会出现不一致性?
MongDB的故障转移会不会无故自动发生?什么条件会触发?频繁触发可能会带来系统负载加重?
Bully算法算法
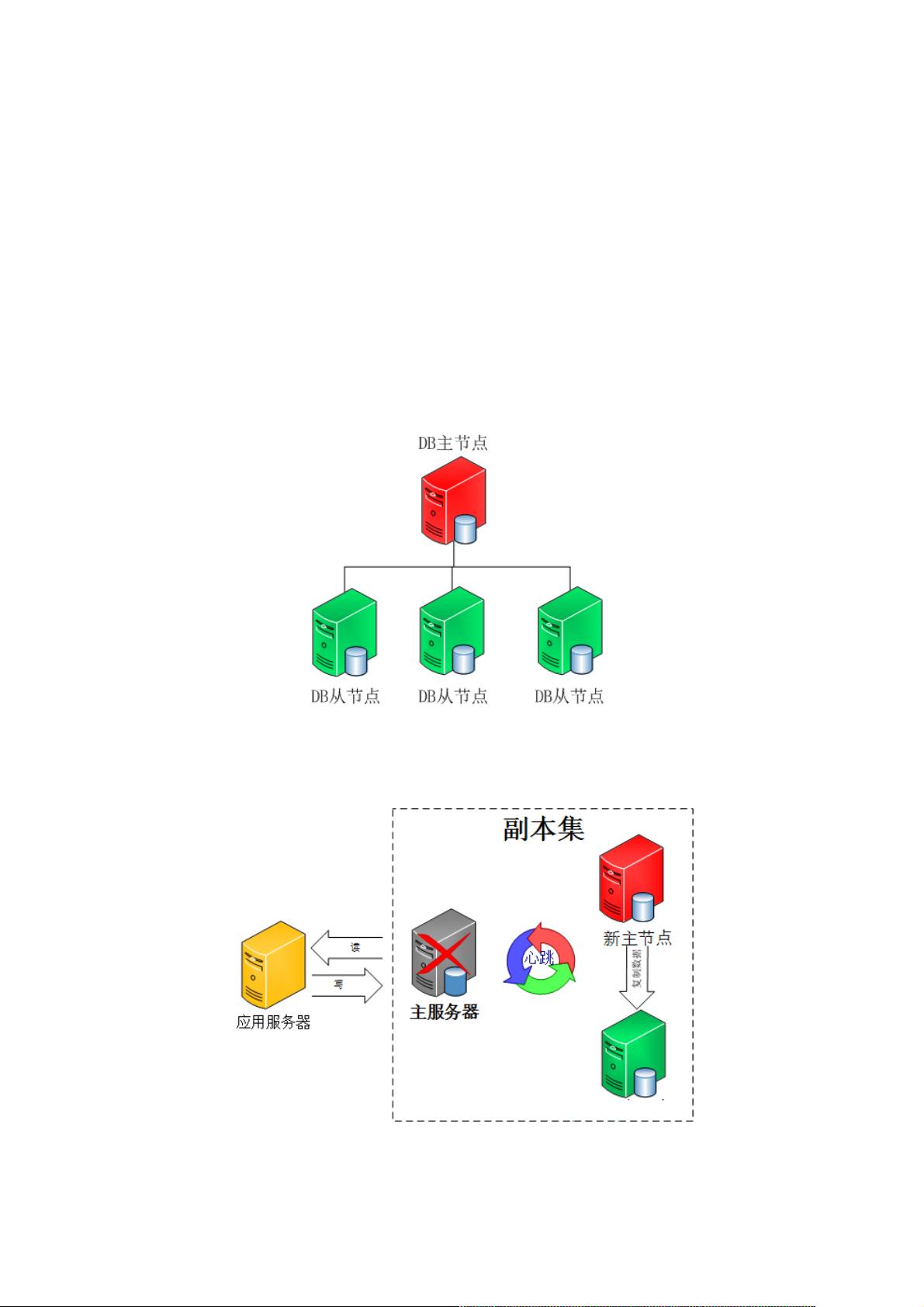
MongDB副本集故障转移功能得益于它的选举机制。选举机制采用了Bully算法,可以很方便从分布式节点中选出主节点。一
个分布式集群架构中一般都有一个所谓的主节点,可以有很多用途,比如缓存机器节点元数据,作为集群的访问入口等等。主
节点有就有吧,我们干嘛要什么Bully算法?要明白这个我们先看看这两种架构:
1.指定主节点的架构,这种架构一般都会申明一个节点为主节点,其他节点都是从节点,如我们常用的MySQL就是这样。但
是这样架构我们在第一节说了整个集群如果主节点挂掉了就得手工操作,上架一个新的主节点或者从从节点恢复数据,不太灵
活。
2.不指定主节点,集群中的任意节点都可以成为主节点。MongoDB也就是采用这种架构,一但主节点挂了其他从节点自动接
替变成主节点。如下图:
好了,问题就在这个地方,既然所有节点都是一样,一但主节点挂了,怎么确定下一个主节点?这就是Bully算法解决的问
题。
那什么是Bully算法,Bully算法是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知
其他节点。别的节点可以选择接受这个声称或是拒绝并进入主节点竞争。被其他所有节点接受的节点才能成为主节点。节点按
照一些属性来判断谁应该胜出。这个属性可以是一个静态ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)。
详情请参考?NoSQL数据库分布式算法的协调者竞选还有维基百科的解释。
下载后可阅读完整内容,剩余3页未读,立即下载
2018-09-12 上传
2021-02-26 上传
2022-08-04 上传
2018-11-21 上传
2019-09-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38717031
- 粉丝: 3
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
