Tip-Adapter:CLIP的无训练适配器,提升少样本分类效能
92 浏览量
更新于2024-06-19
收藏 2.13MB PDF 举报
"Tip-Adapter: 无需训练的CLIP适配器,用于少镜头分类"
本文介绍了一种名为Tip-Adapter的新方法,该方法针对CLIP(Contrastive Language-Image Pre-training)模型在少镜头分类任务中的应用进行了优化。CLIP是一种对比视觉语言预训练模型,它通过大量图像-文本对的学习,能在零样本情况下展现出优秀的下游任务性能。然而,尽管CLIP在某些场景下表现出色,但在数据量有限的少镜头分类任务中,其表现可能会受到影响。
为了提高CLIP在少镜头分类中的性能,现有的策略通常会采用微调自适应学习模块。这些方法虽然能显著提升性能,但同时也增加了训练时间和计算需求。Tip-Adapter则提出了一个创新的解决方案,它无需额外的训练过程,而是利用键值缓存模型从少量训练样本中构建适配器。这种方法通过特征检索来更新CLIP的先验知识,从而增强其对新类别和环境的适应性。
具体来说,Tip-Adapter使用一个缓存模型,该模型能够存储和检索特征,以此来调整CLIP的内部表示。通过这种方式,模型能够在不牺牲CLIP的零样本学习优势的前提下,对新任务进行有效的适应。实验结果显示,Tip-Adapter在ImageNet上的性能可以达到最先进的水平,而且只需微调缓存模型,就能比现有方法节省10倍的训练时间和计算资源。
此外,Tip-Adapter在11个不同的数据集上进行了广泛的少镜头分类实验,其性能和效率的平衡表现优异。表1展示了Tip-Adapter与Zero-shot CLIP和其他方法在ImageNet上的分类准确率和时间效率的比较。这些结果表明,Tip-Adapter在准确率提升的同时,保持了高效的推断速度,实现了准确率-效率的良好权衡。
Tip-Adapter为视觉语言学习提供了一个实用且高效的框架,尤其在面对数据稀疏的分类任务时,能有效提升模型的泛化能力和实用性。通过免训练的适配策略,该方法降低了对大量标注数据和计算资源的依赖,为未来的少镜头分类和相关领域的研究开辟了新的路径。
+v:mala2255获取更多论
文
)
火
车
火
车
∈∈
Tip-Adapter:CLIP 5的
-
- ℎ
少量知识检索
键 值
知识融入
缓存模型
最
新
消息
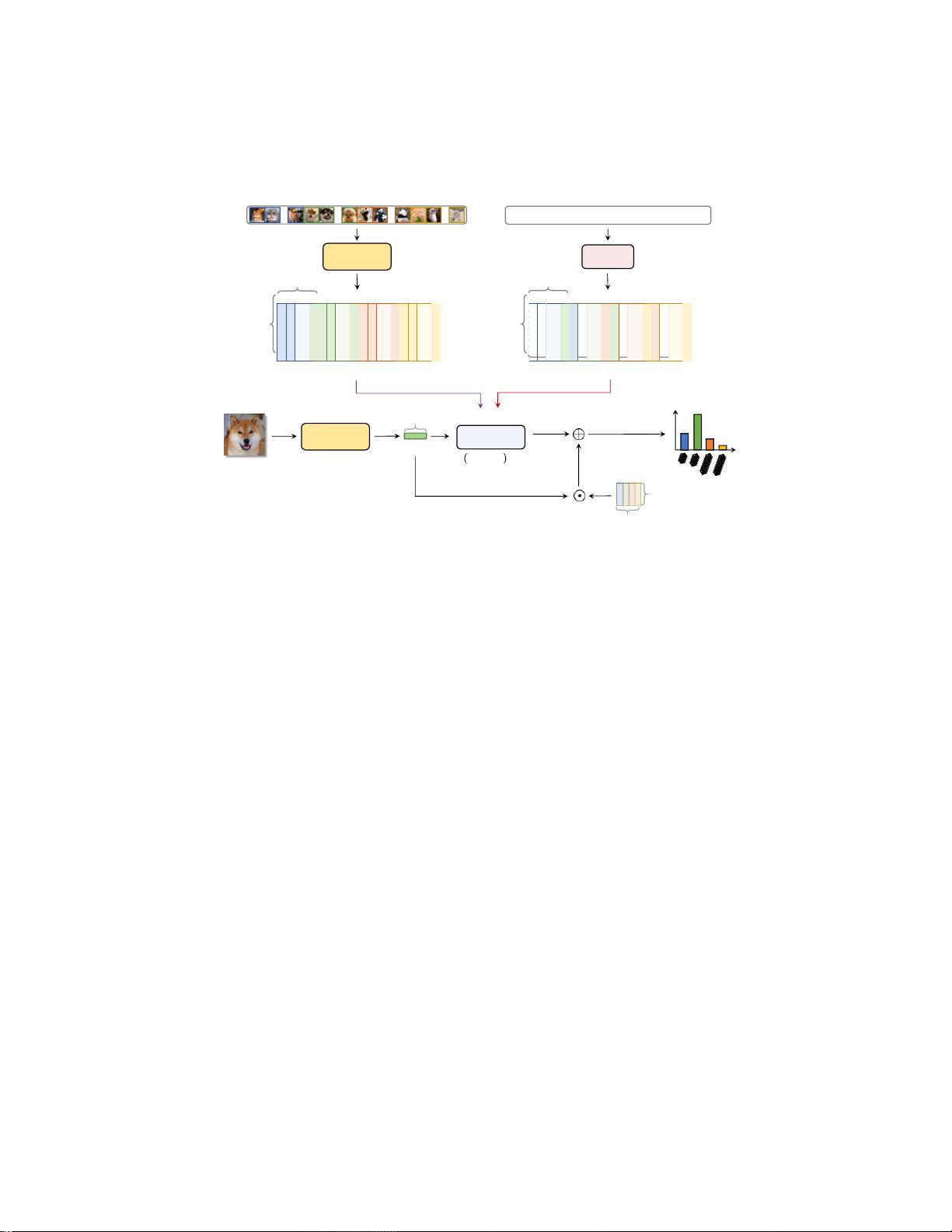
Fig. 1. Tip-Adapter
的流水线。
在给定
K
次
N
类训练集的情况下,我们构造
了 一个缓存模型来适应CLIP在下游任务上的应用. 它含有少量的子弹
视觉特征
F
T
由CLIP和它们的地面实况标签
L
T
编码
下
独热编码从缓存模型中检索后,将少镜头知识与CLIP的预训练知识相结合,
实现了免训练自适应。
缓存模型构建。
给定预训练的CLIP [48]模型和具有用于少数镜头分类的
K个镜头N类训练样本的新数据集,在N个
类别
中的每个类别中有K个注
释图像,表示为
I
K
,其标签为L
N
。我们的目标是创建一个键值缓存模
型作为功能适配器,它包含N
个
类中的少量知识。对于每个训练图像,
我们利用CLIP N维单热向量。对于所有NK训练样本,我们将其视觉
特征和相应的标签向量表示为
F
train
R
NK×C
和
L
train
R
NK×N
,
F
train
= VisualEncoder(
I
K
)
,
(1)
L
train
= OneHot(
L
N
)
。
(二更)
对于键值缓存,CLIP编码的表示
F
train
被视为键,而one-hot地面实况向
量
L
train
被用作它们的值。通过这种方式,键值缓存存储从少量训练
集中提取的所有新知识,用于更新编码在预训练CLIP中的先验知识。
剪辑 的
视觉编码器
剪辑 的
视觉编码器
反
不
确定
性
(
不
的知识
剩余21页未读,继续阅读
2008-01-02 上传
2010-05-18 上传
2011-08-03 上传
2023-06-01 上传
2023-03-25 上传
2023-03-31 上传
2024-10-31 上传
2023-03-09 上传
2023-05-27 上传
2023-07-08 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
