Python Selenium 实现QQ群成员提取与群主、管理员信息过滤
31 浏览量
更新于2024-08-31
收藏 235KB PDF 举报
本文主要展示了如何使用Python的Selenium库来加载并保存QQ群成员信息,同时排除群主和管理员的细节。通过实例代码,帮助读者理解自动化登录过程以及筛选群成员的步骤。
在Python中,Selenium是一个强大的Web自动化测试工具,它可以模拟用户与网页的交互。在这个示例中,我们利用Selenium来实现QQ群成员的抓取和存储,尤其关注如何跳过群主和管理员的信息。首先,我们需要了解网页的结构,以便定位到正确的元素进行操作。
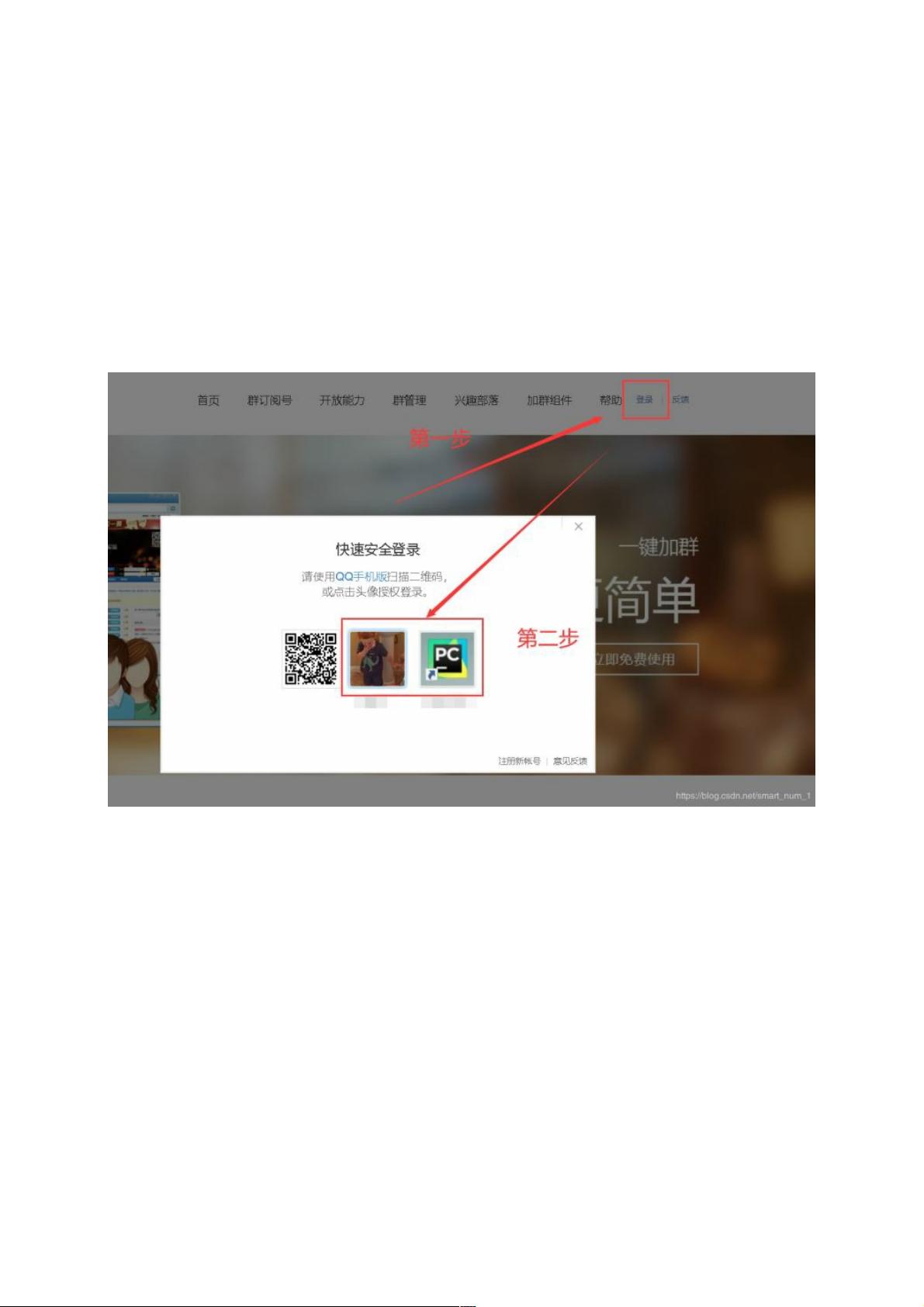
登录过程是整个程序的关键部分。代码中定义了一个`login`函数,它等待登录按钮出现并点击它,然后找到已经登录的QQ账号。通过`WebDriverWait`类,我们可以设置超时时间,确保元素存在后再执行下一步操作。例如,使用`EC.presence_of_element_located`方法查找指定XPath的元素。在这个例子中,XPath用于定位登录按钮和已登录账号的元素。
登录完成后,程序会进入QQ账号选择的子页面,通过获取登录框内嵌iframe的源URL,然后加载这个子页面。这样做的目的是因为登录界面通常在一个单独的iframe中,需要切换到这个iframe才能进行进一步的交互。
接下来,可能需要模拟填写账号密码并提交登录,这部分代码没有在摘要中给出,但通常会包括找到输入框和提交按钮,然后调用`send_keys`方法输入账号和密码,最后点击登录按钮。
登录成功后,就可以开始获取QQ群成员信息了。这部分代码未在摘要中详细描述,但通常需要定位到群成员列表,可能是一个`ul`或`table`元素,然后遍历每个成员项。对于每个成员,检查他们的角色(如群主或管理员),如果他们不是群主或管理员,则将他们的信息保存到数据结构(如列表或字典)中。信息可能包括昵称、QQ号等。
整个过程中,需要注意处理可能出现的验证码、滑动验证或其他安全机制。此外,频繁的操作可能会触发网站的反爬策略,因此在实际应用时,可以考虑添加延时或者使用代理IP以避免被封禁。
总结来说,这个示例展示了如何结合Selenium和Python实现QQ群成员的自动化抓取,同时规避特定角色的信息。通过学习这个示例,开发者可以了解到如何在Web自动化场景中进行页面元素的定位、事件触发以及数据提取,这对于进行类似的网页爬虫项目具有很高的参考价值。
Python selenium 加载并保存加载并保存QQ群成员群成员,去除其群主、管理员信去除其群主、管理员信
息的示例代码息的示例代码
主要介绍了Python selenium 加载并保存QQ群成员 去除其群主、管理员信息的示例代码,本文通过实例代码给大家介
绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧
一位伙计自己开了个游戏室,想在群里拉点人,就用所学知识帮帮忙,于是就有了这篇文章,今天小编特此通过实例代码给大家介绍
下Python selenium 加载并保存QQ群成员去除其群主、管理员信息的示例代码
模拟登陆页面模拟登陆页面
页面分析页面分析
思路:思路:
点击登陆按钮
选择要登陆的账号
代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def login(driver = None):
already_dic = {}
# 创建一个字典,保存电脑登陆的QQ
login_button = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//p[@class="user-info"]/a')))
login_button.click()
# 点击登录,获取电脑登陆的QQ
already_login_number = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//div[@id="loginWin"]/iframe')))
driver.get(url = already_login_number.get_attribute('src'))
# 此步骤目的,是因为登录框是一个子页面,在上一级页面中获得到的这个子页面
already_login_numbers = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//span[contains(@class,"nick")]')))
# 获取电脑登陆的QQ
print('在以下账号中选择所需账号')
for already_login_number in already_login_numbers:
already_dic[already_login_number.get_attribute('innerText')] = already_login_number
print(already_login_number.get_attribute('innerText'))
QQ_NeedToLogin = input('需要登陆: ')
下载后可阅读完整内容,剩余3页未读,立即下载
2020-05-27 上传
2020-09-16 上传
点击了解资源详情
2020-12-21 上传
2021-01-02 上传
2024-02-03 上传
2023-11-09 上传
2019-08-10 上传
点击了解资源详情

weixin_38730767
- 粉丝: 8
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
