Lucene深度解析:从 HelloWorld到内部机制
需积分: 50 32 浏览量
更新于2024-07-26
收藏 2.73MB PDF 举报
"Lucene是一个高性能、全文本搜索库,它为Java开发人员提供了高级文本分析和索引功能。本文档将深入探讨Lucene的核心概念、索引结构以及数据存储方式,帮助读者理解如何使用和优化Lucene进行信息检索。"
Lucene是Apache软件基金会的一个开源项目,提供了一个强大的全文检索引擎库,适用于各种Java应用程序。它支持多种搜索功能,如布尔逻辑、短语搜索、模糊搜索、评分排序等。Lucene的主要特性包括高效的索引构建和查询执行、对多种数据源的支持以及灵活的文本分析。
API组成包括多个关键组件,如`IndexWriter`用于创建和更新索引,`Analyzer`用于文本预处理,`QueryParser`用于构建查询,以及`Searcher`用于执行搜索并返回结果。要快速上手,可以尝试一个简单的"HelloWorld!"程序,其中涉及创建一个`Directory`对象,使用`IndexWriter`写入文档,然后使用`Searcher`查找这些文档。
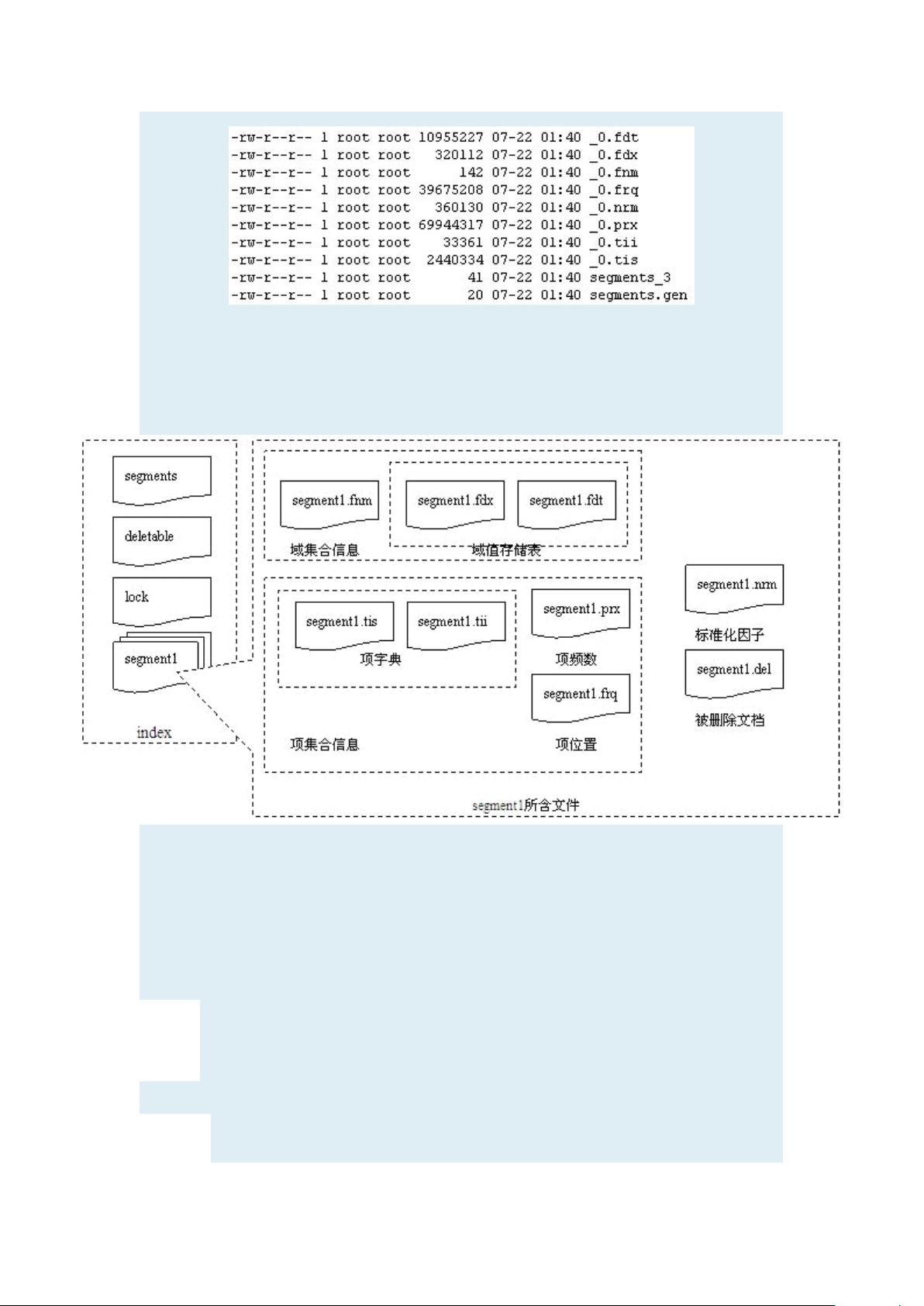
Lucene的索引数据结构基于倒排索引,这是一种高效的数据结构,用于快速查找包含特定词项的文档。索引由多个文件组成,包括`Segments`(段)、`Lock`(锁)、`Deletable`(可删除)和`Compound`(复合)文件等。每个段包含字段信息、字段数据、术语字典、频率数据、位置信息、规范化因子文件和可能的删除文档记录。这些文件协同工作,确保快速搜索和准确匹配。
索引的创建过程涉及`IndexWriter`类,它负责读取输入文档,应用分析器进行文本处理,然后将结果写入索引。`DocumentsWriter`类处理实际的索引段创建,而`SegmentMerger`则负责合并多个段以优化索引。
数据在Lucene中是通过`Directory`类存储的,它抽象了底层的存储机制,可以是文件系统(`FSDirectory`)、内存(`RAMDirectory`)或其他定制实现。`IndexInput`和`IndexOutput`接口分别用于读写操作,确保数据的一致性和可靠性。
在深入学习Lucene时,了解这些核心概念和内部工作原理对于开发高效、可靠的全文搜索功能至关重要。通过掌握索引构建、查询执行和数据存储的细节,开发者能够更好地利用Lucene提供的功能,同时解决可能出现的局限性问题,以优化搜索性能和用户体验。

档所返回的( returned )信息。这些是通过文档编号( document number )来做为 key 得 到
的。
3 Term
Term
Term
Term 字典( dictionary
dictionary
dictionary
dictionary ): 一个包含( contains )所有 terms 的字典,被使用在所有 文
档中所有被索引的 fields 中。它还包含了该 term 所在的文档的数目( the number of
documents which contains the term
),并且指向了(
pointer to
)
term 的频率( frequenc y
)
和接近度( proximity )的数据( data )。
4 Term
Term
Term
Term 频率数据( frequency
frequency
frequency
frequency data
data
data
data ): 对字典中的每一个 term 来说,所有包含该 ter m
( contains the term )的文档的编号( numbers of
all
documents ),以及该 term 出现在 该
文档中的频率( frequency )。
5 Term
Term
Term
Term 接近度数据( proximity
proximity
proximity
proximity data
data
data
data ): 对字典中的每一个 term 来说,该 term 出现 在
( occur )每一篇文档中的位置( positions )。
6 调整因子( normalization
normalization
normalization
normalization factors
factors
factors
factors ): 对每一篇文档的每一个 field 来说,为一个存储
的值 (
a value is stored
) 用来加入到 (
multiply into
) 命中该
field
的分数 (
score for hits on that
field )中。
7 Term
Term
Term
Term 向量( vectors
vectors
vectors
vectors ): 对每一篇文档的每一个 field 来说, term 向量(有时候被称 做
文档向量) 可以被存储。 一个
term 向量由 term 文本和 term
的频率 (
frequency
) 组成 (
c
onsists
of )。怎么添加 term 向量到你的索引中请参考 Field 类的构造方法( constructors )。
8 删除的文档( deleted
deleted
deleted
deleted documents
documents
documents
documents ): 一个可选的( optional )文件标示( indicating
)
哪一篇文档被删除。
关于这些项的详细信息在随后的章节( subsequent sections )中逐一介绍。
2.1.7
2.1.7
2.1.7
2.1.7 索引文件中定义的数据类型
数据类型
所占字节长度(字
节)
说明

剩余72页未读,继续阅读
2019-03-29 上传
2018-05-14 上传
2012-04-25 上传
2010-09-13 上传
2008-10-21 上传
2019-03-19 上传
2009-03-20 上传
2012-05-28 上传
2012-10-16 上传

Jacobgxb
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
