大数据技术入门:从Hadoop到Spark
需积分: 5 195 浏览量
更新于2024-06-21
收藏 39.14MB PDF 举报
"大数据入门指南 v1.0 (1).pdf"
本指南是针对大数据初学者的一份详尽教程,由作者heibaiying在2020年6月1日发布,并在GitHub上开源。内容涵盖了大数据领域的基础概念、关键技术以及实际操作,包括Hadoop、Hive、Spark和Storm等组件的讲解。
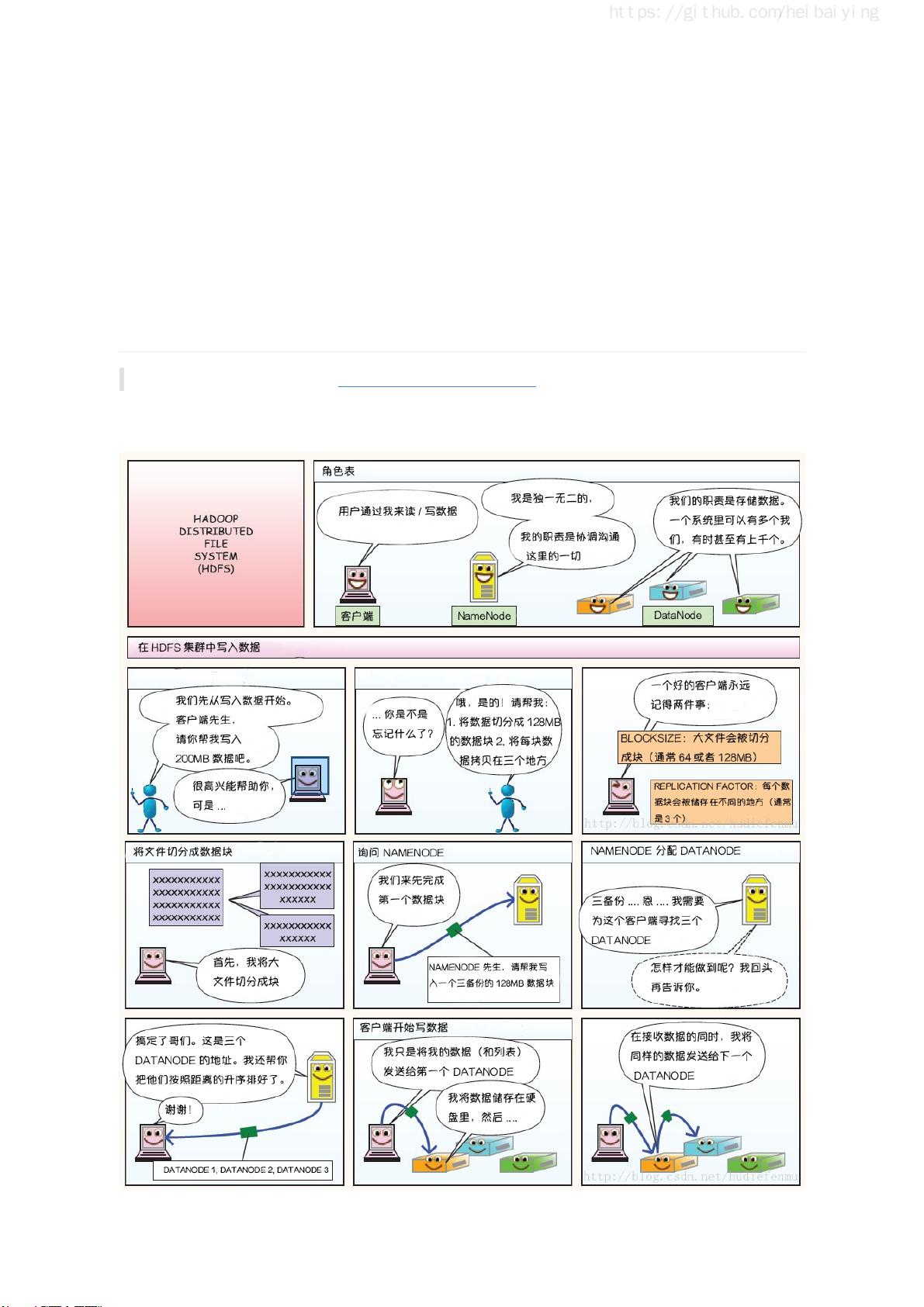
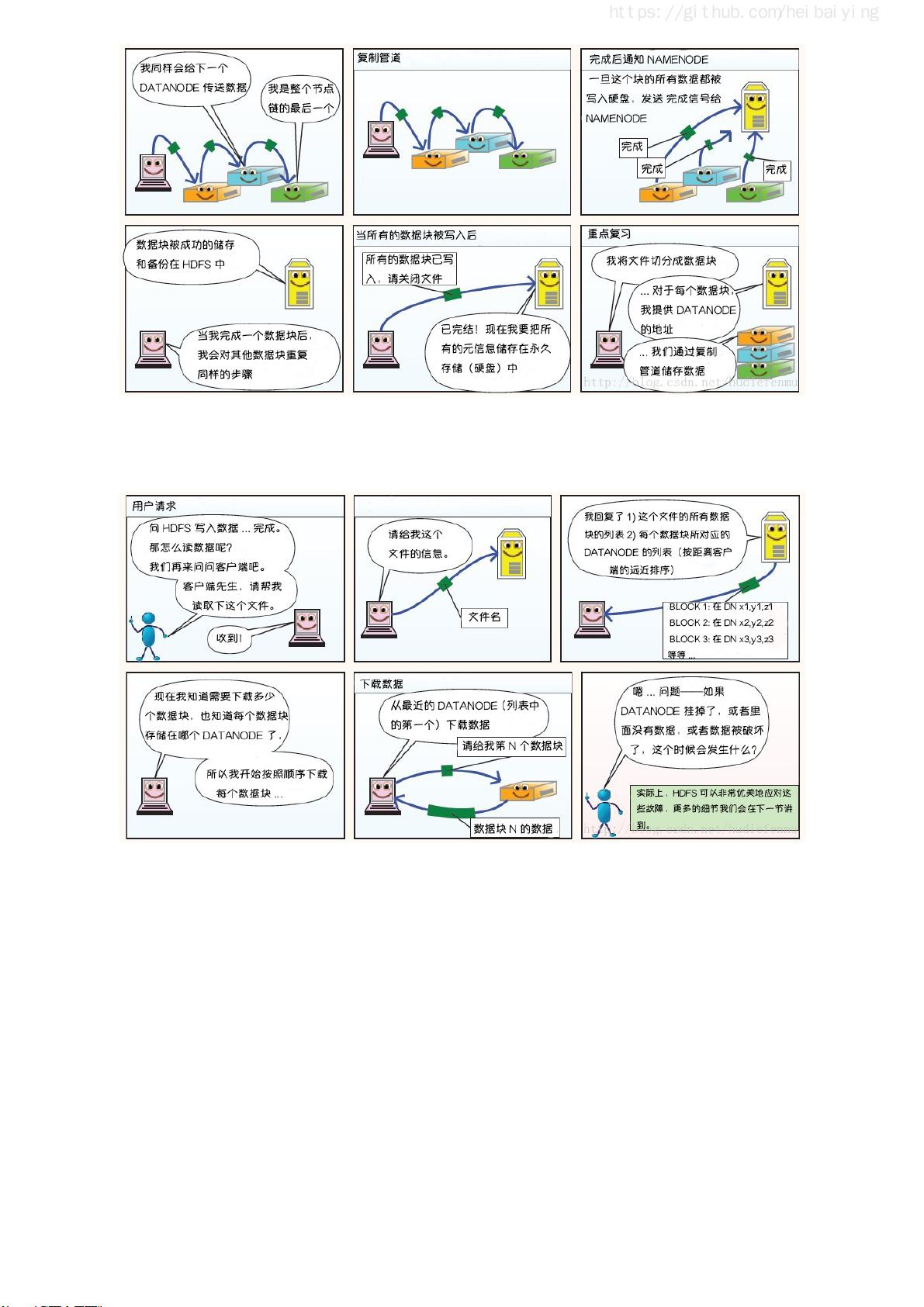
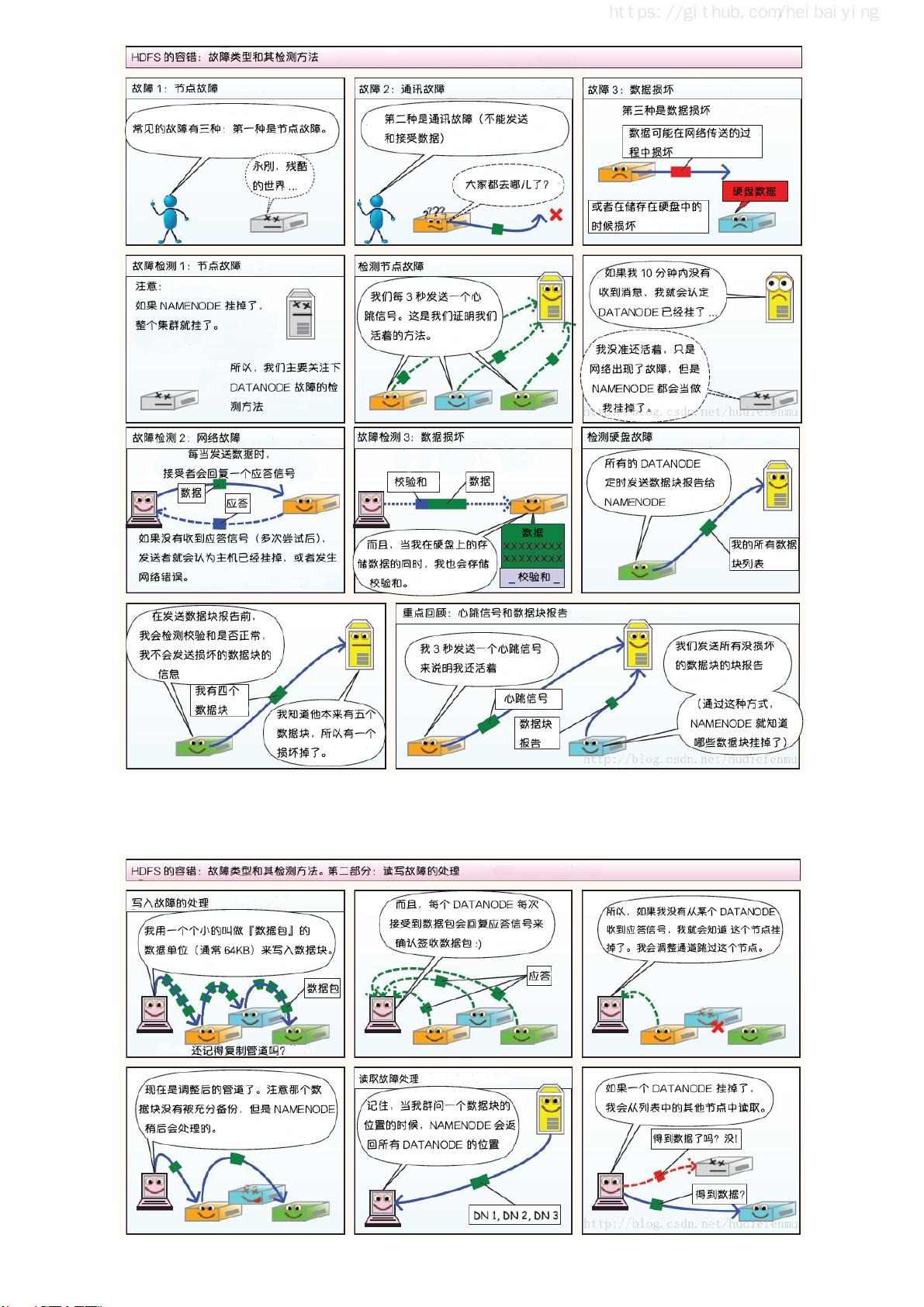
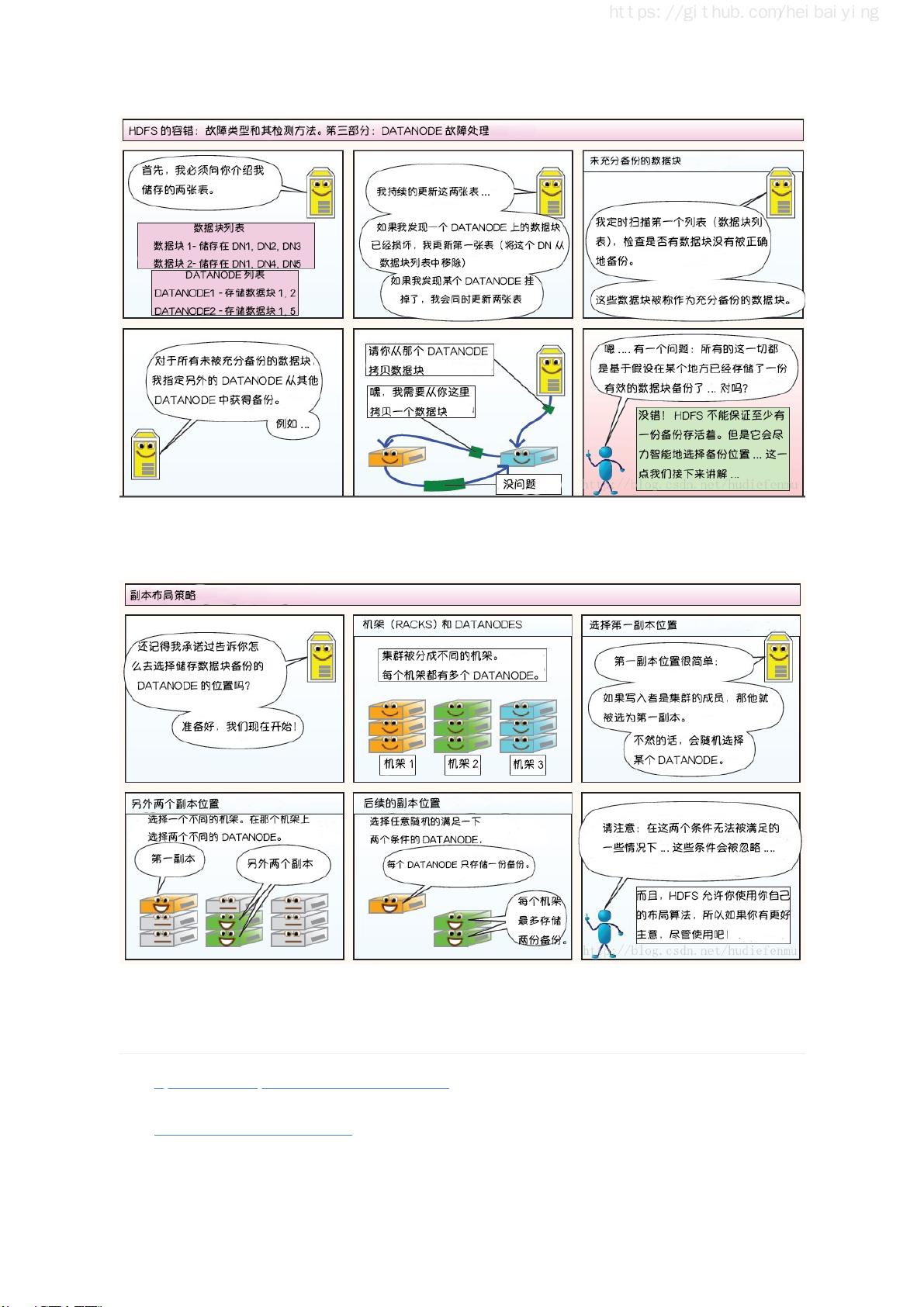
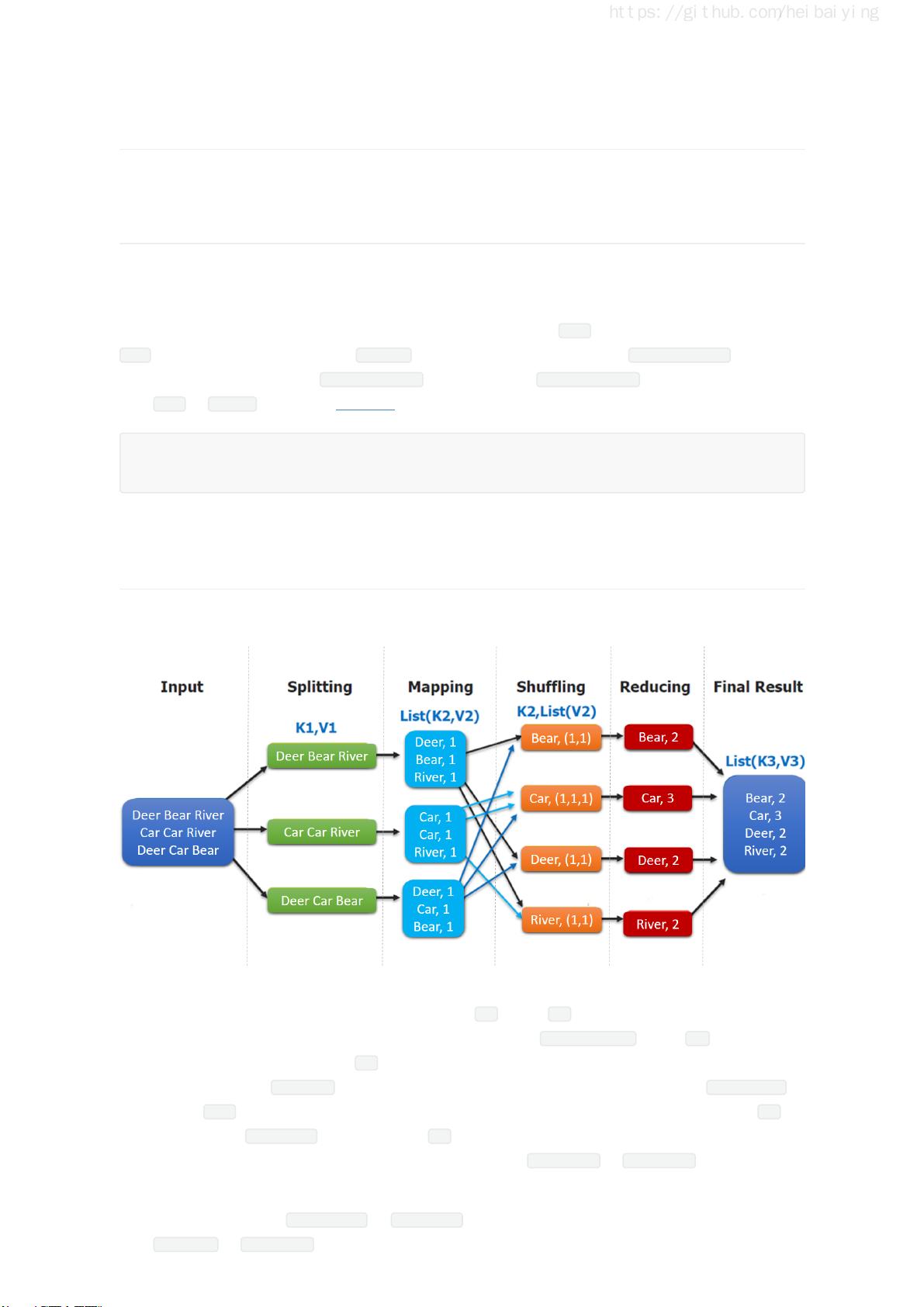
一、Hadoop部分介绍了分布式文件存储系统HDFS(Hadoop Distributed File System),它是Hadoop的核心组件,用于存储海量数据。MapReduce则是一个分布式计算框架,它将大任务分解为小任务并行处理,然后重新组合结果。YARN(Yet Another Resource Negotiator)作为Hadoop的资源管理器,负责调度集群资源。指南还提供了Hadoop的单机伪集群和集群环境的搭建方法,以及HDFS的Shell命令和Java API的使用。对于高可用性,书中讲解了如何利用Zookeeper搭建Hadoop高可用集群。
二、Hive部分详细阐述了Hive作为数据仓库工具的角色,包括其核心概念、安装部署过程,以及在Linux环境下的操作。Hive提供了CLI和Beeline两种命令行工具进行交互,支持多种DDL(Data Definition Language)和DML(Data Manipulation Language)操作,如创建表、分区、视图和索引。Hive的分区表和分桶表设计有助于提高数据查询效率。
三、Spark部分涵盖了SparkCore、SparkSQL和SparkStreaming三个主要模块。SparkCore是Spark的基础,讲解了Spark的基本概念、开发环境搭建,以及关键数据结构RDD(Resilient Distributed Datasets)。RDD的算子和运行模式进行了深入解析,还包括了Spark的累加器和广播变量。SparkSQL引入了DataFrame和DataSet,提供了一种更高级的接口,支持SQL查询,并对接了多种外部数据源。此外,指南还介绍了SparkSQL的聚合函数和JOIN操作。SparkStreaming部分介绍了实时流处理,包括基本操作、与Flume和Kafka的整合。
四、Storm部分讲解了实时计算框架Storm,介绍了流处理的基本概念,以及Storm的核心概念,如拓扑和工作原理。指南详细阐述了如何在单机和集群环境中搭建Storm,以及Storm的编程模型,帮助读者理解如何处理实时数据流。
这份入门指南为初学者提供了一个全面的大数据学习路径,通过理论与实践的结合,帮助读者快速掌握大数据处理的关键技术。
2020-10-24 上传
2014-04-22 上传
2022-08-08 上传
2007-06-07 上传
176 浏览量
2022-08-11 上传
2018-09-12 上传
点击了解资源详情
点击了解资源详情

死磕代码程序媛
- 粉丝: 136
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







