Python基础:探索Linux网络IO模型与阻塞/非阻塞的区别
40 浏览量
更新于2024-09-01
收藏 330KB PDF 举报
本文主要探讨了Python基础中的I/O模型,特别是针对Linux环境下的网络IO。I/O模型在计算机编程中扮演着关键角色,它定义了程序与外部设备(如磁盘、网络)之间的数据传输方式。在Python中,理解I/O模型有助于优化性能和避免常见的编程陷阱。
首先,作者澄清了几个常见的IO概念。在Linux环境中,通常区分四种主要的IO模型:
1. 阻塞IO (Blocking IO): 这是最传统的模型,当进程发起一个IO操作(如read或write)时,如果数据尚未准备好,它会暂停进程(阻塞)直到数据可用。这种模型简单直观,但可能导致性能瓶颈,因为进程在等待期间不能执行其他任务。
2. 非阻塞IO (Non-blocking IO): 在这种模式下,进程不会被阻塞,而是立即返回。如果数据尚未准备好,它会立即返回,通常伴随着一个错误状态。非阻塞IO需要程序员手动管理IO事件,例如使用epoll或select等机制来检查IO操作是否完成。
3. IO多路复用 (IO Multiplexing): 这种模型允许进程同时监控多个IO请求,当某个请求准备就绪时,通过事件通知机制唤醒进程。Epoll和kqueue是常见的多路复用API。这种方法提高了效率,尤其适用于大量小规模的并发连接。
4. 异步IO (Asynchronous IO): 这是基于回调或事件循环的模型,当数据准备好时,系统会自动通知进程进行处理,而无需轮询。Python的asyncio库就是实现异步IO的一个例子,它利用了底层的事件驱动模型,显著提升高并发场景下的性能。
文章重点介绍了阻塞IO的基本流程,强调了在数据准备和数据复制到进程这两个阶段的区别。了解这些阶段有助于理解如何在Python代码中更有效地管理IO操作,特别是在网络编程中,选择正确的IO模型对性能至关重要。
掌握Python中的I/O模型对于编写高效、可扩展的网络应用程序至关重要。理解阻塞、非阻塞、多路复用和异步IO之间的差异,以及它们在Linux环境中的应用,可以帮助开发者构建出更加灵活、性能优越的系统。同时,Python提供的异步编程工具,如asyncio,使得异步IO在现代编程中越发受到重视。
浅谈浅谈Python基础之基础之I/O模型模型
下面小编就为大家带来一篇浅谈Python基础之I/O模型。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
一、一、I/O模型模型
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是
磁盘、网络等,就需要IO接口。
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?
这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且
在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,先限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。
Stevens在文章中一共比较了五种在文章中一共比较了五种IO Model::
blocking IO(阻塞(阻塞IO))
nonblocking IO (非阻塞(非阻塞IO))
IO multiplexing ((IO多路复用)多路复用)
asynchronous IO (异步(异步IO))
signal driven IO (信号驱动(信号驱动IO))
由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作
发生时,它会经历两个阶段:
等待数据准备 (Waiting for the data to be ready)
将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
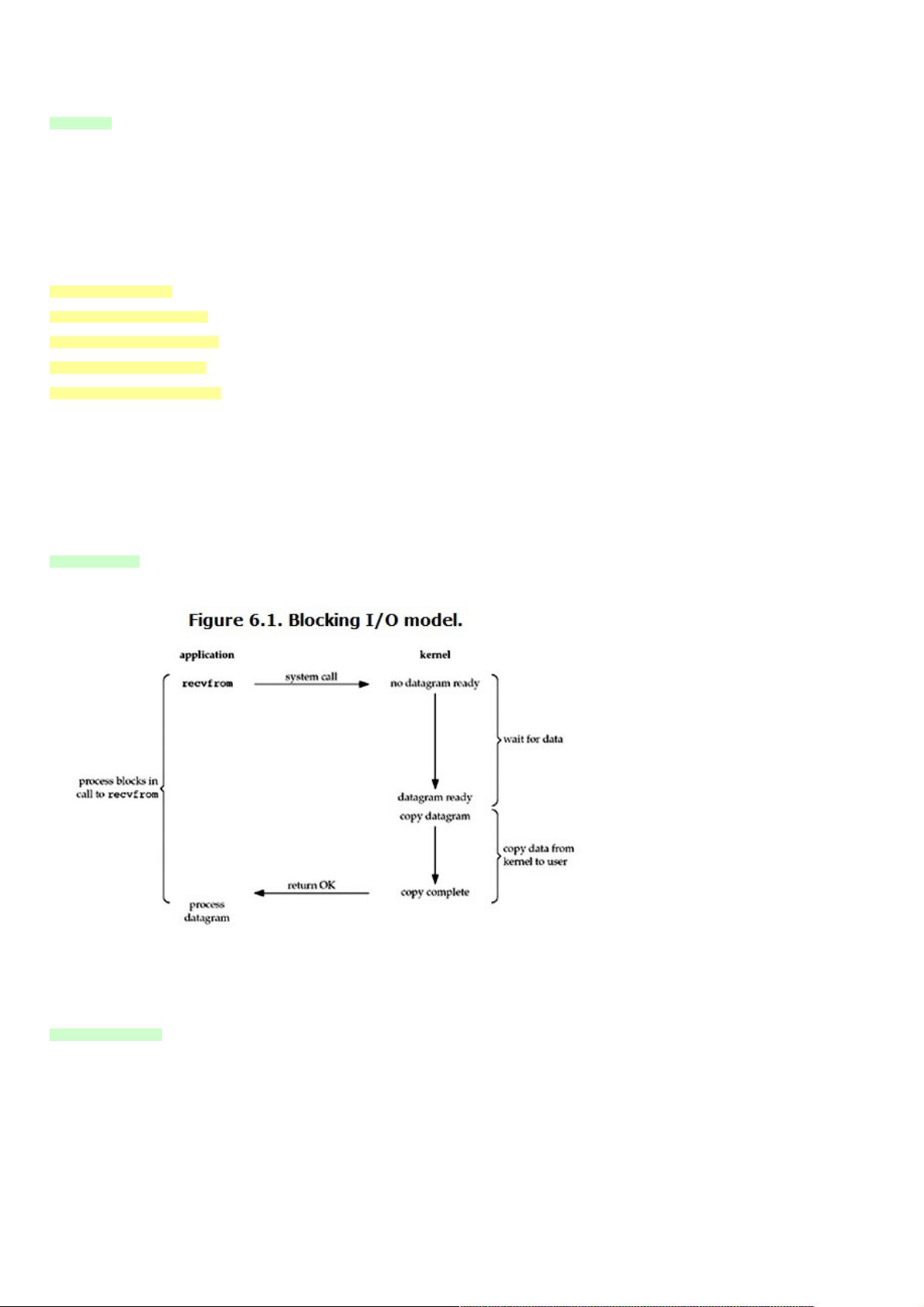
二、二、 blocking IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network IO来说,很多时候数据在一开始还没有到达(比如,还没有
收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从
kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,所以,blocking IO的特点就是在的特点就是在IO执行的两个阶段都被执行的两个阶段都被block了。了。
三、三、non-blocking IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
下载后可阅读完整内容,剩余4页未读,立即下载
2024-06-30 上传
2788 浏览量
1372 浏览量
878 浏览量
2798 浏览量
770 浏览量
1691 浏览量
1277 浏览量

weixin_38735887
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python3实现的一键自动更新hosts脚本教程
- Omron PLC Modbus-RTU读写操作示例教程
- 跨国公司在中国发展通用战略分析
- Minhas成功解决URI编码问题的Python方案
- PyTorch框架下CoordConv实验笔记本实现
- 江苏联通执行文化基本构架深度解析
- 深入理解JavaScript中的沙盒技术
- MAC系统plist文件编辑器:强大工具汉化苹果软件
- 掌握机器学习算法实现:源代码开源分享
- LokiJS与Bootstrap融合:实现高效客户端数据网格
- Android图片圆角剪裁与旋转缩放存储教程
- 深入解析ONVIF协议IPC客户端程序开发及示例代码
- 探索Elm与JavaScript混合开发:榆树港口聊天应用
- 企业文化凝聚力与价值创造指南
- CM0102更新包:中国及亚洲多地联赛游戏补丁
- C++数学工具库:MathTool深入解析
