Hadoop深度解析:分布式存储与分析的关键技术
需积分: 5 114 浏览量
更新于2024-07-16
收藏 2.75MB PDF 举报
Hadoop Notebook是一份全面介绍Hadoop技术的详细指南,它涵盖了Hadoop生态系统的核心组件:Hadoop Distributed File System (HDFS)、YARN、MapReduce以及相关的技术细节。这份文档旨在帮助读者理解Hadoop如何处理海量数据,并实现数据的可靠存储、高效分析和处理。
1. HDFS:HDFS是Hadoop的主要存储组件,设计用于处理大规模数据。它将大文件分割成64M(可配置)的Block,分散存储在集群的不同节点上,以提高数据访问速度和容错能力。每个Block默认复制三份,确保数据安全性和高可用性。文件操作包括写入(Write)、读取(Read),以及故障恢复策略,确保即使部分节点失效,数据仍能被完整访问。
2. YARN:Yet Another Resource Negotiator是Hadoop的资源调度器,负责任务的分配和管理。它包括Resource Manager(全局资源管理器)、Node Manager(节点资源管理器)、ApplicationMaster(应用程序主进程)、Container(可执行的容器)以及故障处理机制,支持在分布式环境中执行复杂的任务。
3. MapReduce:这是一种分布式计算模型,用于并行处理大量数据。它包括读取数据(Input)、Map阶段(将输入切分成小块进行处理)、Shuffle(数据重新排序和分发)、Reduce阶段(汇总和合并中间结果)以及编程模型的设计。MapReduce允许用户编写简单的函数来处理数据,无需关心底层细节。
4. 大数据特性:Hadoop针对大数据的特性,如大量性(volume)、快速性(velocity)、多样性(variety)和易变性(variability),提供解决方案。数据的分布式存储和分析使得系统能够处理超出单机处理能力的数据。同时,Hadoop强调数据的准确性和复杂性管理,通过有效的方法抽取、转换和加载数据以获取有价值的信息。
5. 关键技术:Hadoop Notebook详细讲解了Hadoop的关键技术,包括分布式存储、数据分片、任务调度、数据处理模型和性能优化。这些技术共同构成了Hadoop在处理大规模数据时的核心竞争力。
通过这份笔记,读者可以深入理解Hadoop的工作原理,掌握如何使用Hadoop生态系统中的工具进行数据处理和分析,从而应对日益增长的数据挑战。无论是初次接触Hadoop的开发者还是经验丰富的专业人士,这份资源都是提升大数据处理能力的重要参考资料。
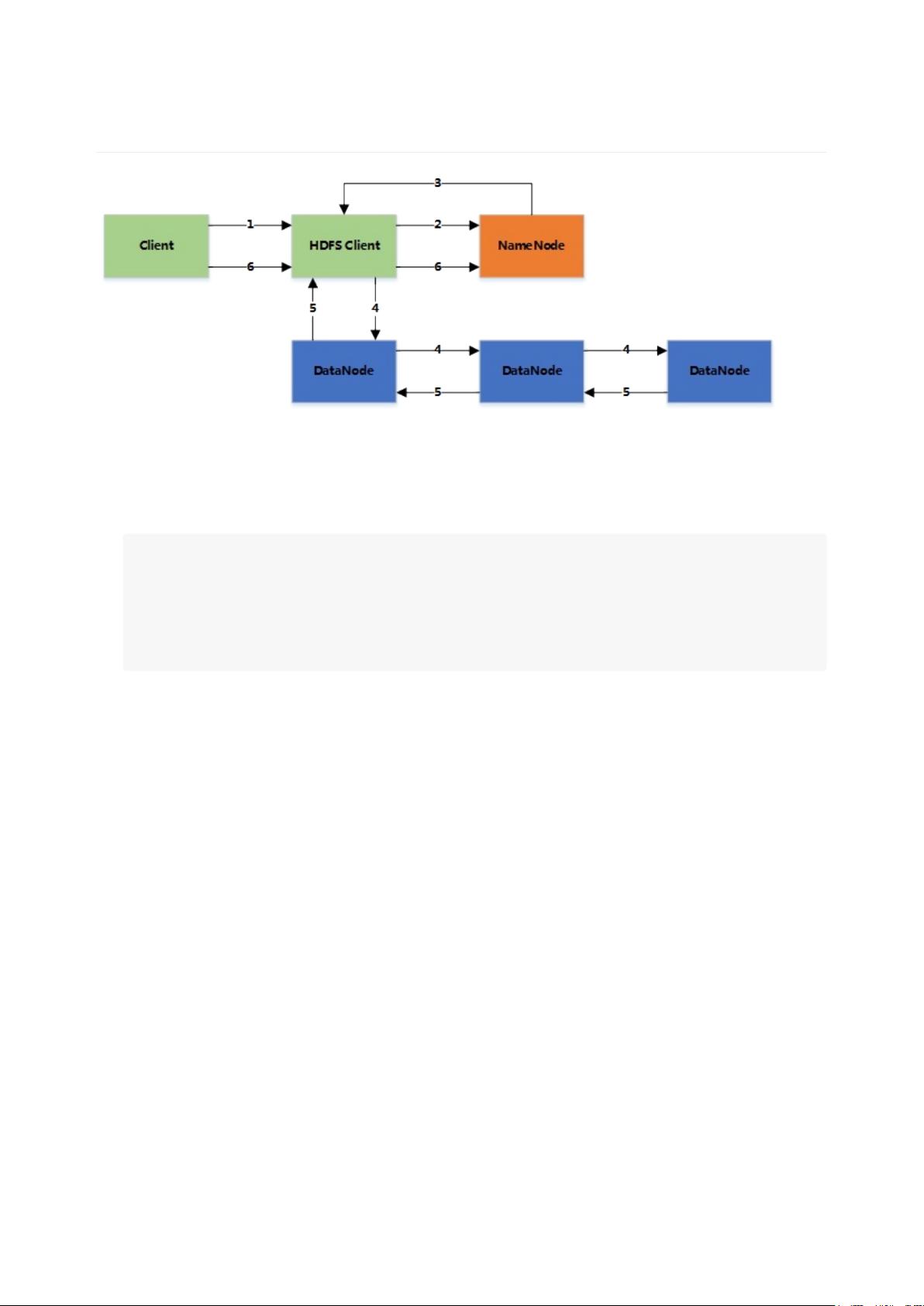
1. 客户端将文件写入本地磁盘的临时文件中
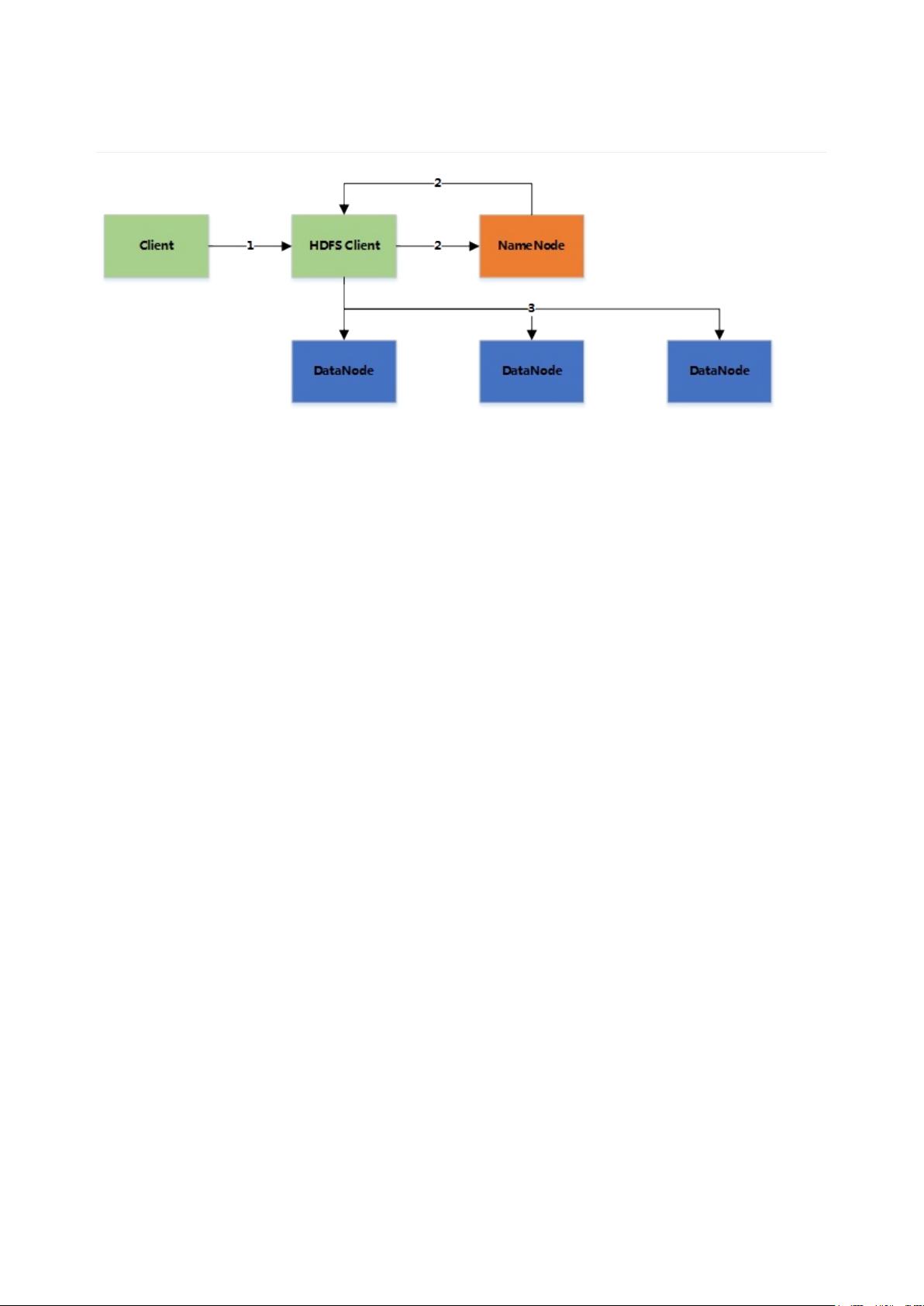
2. 当临时文件大小达到一个block大小时,HDFSclient通知NameNode,申请写入文件
3. NameNode在HDFS的文件系统中创建一个文件,并把该blockid和要写入的DataNode的列表返回给客户端
4. 客户端收到这些信息后,将临时文件写入DataNodes
4.1客户端将文件内容写入第一个DataNode(一般以4kb为单位进行传输)
4.2第一个DataNode接收后,将数据写入本地磁盘,同时也传输给第二个DataNode
4.3依此类推到最后一个DataNode,数据在DataNode之间是通过pipeline的方式进行复制的
4.4后面的DataNode接收完数据后,都会发送一个确认给前一个DataNode,最终第一个DataNode返回确认给客户端
4.5当客户端接收到整个block的确认后,会向NameNode发送一个最终的确认信息
4.6如果写入某个DataNode失败,数据会继续写入其他的DataNode。然后NameNode会找另外一个好的DataNode继续复制,以保证冗余性
4.7每个block都会有一个校验码,并存放到独立的文件中,以便读的时候来验证其完整性
5. 文件写完后(客户端关闭),NameNode提交文件(这时文件才可见,如果提交前,NameNode垮掉,那文件也就丢失
了。fsync:只保证数据的信息写到NameNode上,但并不保证数据已经被写到DataNode中)
Rackaware(机架感知)
通过配置文件指定机架名和DNS的对应关系
假设复制参数是3,在写入文件时,会在本地的机架保存一份数据,然后在另外一个机架内保存两份数据(同机架内的传输速
度快,从而提高性能)
整个HDFS的集群,最好是负载平衡的,这样才能尽量利用集群的优势
HDFS-写文件
HadoopNotebook
8写文件
剩余44页未读,继续阅读
2024-07-11 上传
2020-02-06 上传
2021-05-20 上传
2019-11-22 上传
2022-02-09 上传
2023-03-21 上传
2022-11-24 上传
2022-10-27 上传
2024-04-14 上传

宇直豪
- 粉丝: 110
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 血色素沉着病:混合了性别和基因型的血液样本具有铁血毒性
- 参考资料-基于soc单片机的ph值检测与控制.zip
- Copy Tab-crx插件
- pandas_flavor-0.1.2.tar.gz
- Tcldrop-开源
- zTail-开源
- 通往软件架构师的道路-Python开发
- Laboratorio7_CVDS
- 恶意软件收集:计算机的恶意软件,压力测试等的源代码
- whiteboard-angular-client:白板前端。 Whiteboard Web App的Angular客户端。 :books:
- pandas_flavor-0.1.1.tar.gz
- iTab - Awesome Tab Manager-crx插件
- aria2c-android-app:aria2c-android-app
- projecting
- x70talk-开源
- DPDraggableButton-Swift:拖动或点击按钮以触发手势事件
