Apache Flink 中文实战:维表关联解析
需积分: 40 160 浏览量
更新于2024-07-15
收藏 2.87MB PDF 举报
"Apache Flink 维表关联实战.pdf"
在Apache Flink的处理流程中,维表关联(Join)是一个核心且重要的操作,它允许我们结合来自不同数据源的信息,以便进行更复杂的分析和处理。这份文档深入探讨了Flink中的维表关联,包括Flink SQL和DataStream API的应用,以及各种类型的Join操作。
01 Join概念
在数据库理论中,Join是将两个或更多表的数据合并在一起的关键操作。这个过程基于这些表之间的共同字段,即它们的键或关联列。由于Join在业务处理中的广泛使用和其优化规则的复杂性,理解和掌握Join对于任何数据处理专家都至关重要。
02 Flink SQL Join
Flink SQL提供了一种声明式的接口,使得用户可以方便地执行Join操作。它可以支持多种类型的Join,包括:
- Cross Join:生成两个输入表的笛卡尔积,每个左表的记录都会与右表的每个记录匹配。
- Inner Join:只返回两个表中键匹配的记录。
- Left Outer Join:返回左表的所有记录,如果右表没有匹配的记录,则相应字段填充NULL。
- Right Outer Join:返回右表的所有记录,如果左表没有匹配的记录,则相应字段填充NULL。
- Full Outer Join:返回左右两表的所有记录,如果其中一方没有匹配的记录,相应字段则填充NULL。
03 Flink DataStream Join
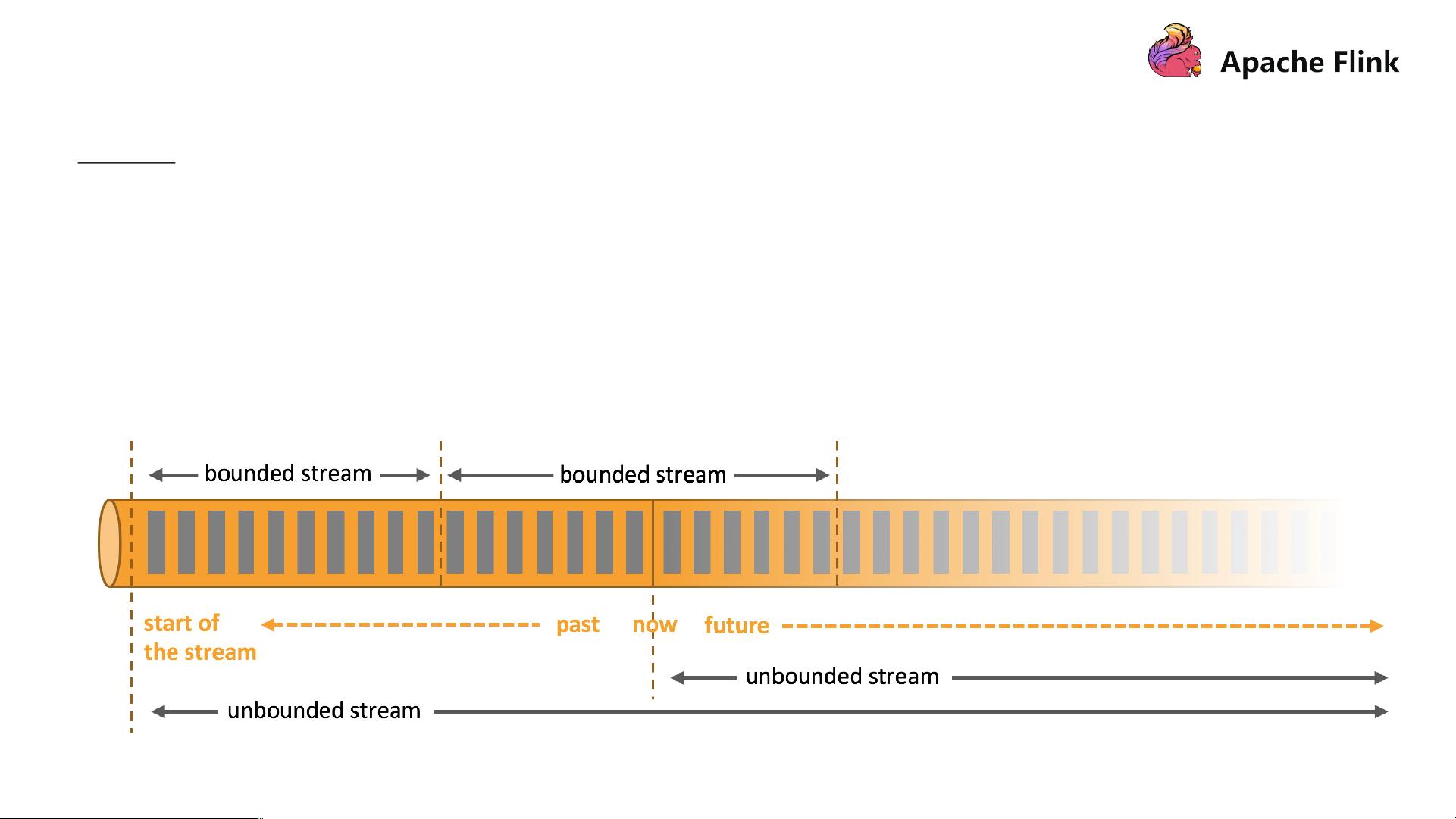
DataStream API是Flink处理实时流数据的主要接口,它同样支持Join操作。DataStream Join通常需要定义窗口来处理无限数据流。例如,Tumbling Windows、Sliding Windows等,可以在特定时间间隔内聚合数据,然后进行Join操作。
04 Flink案例实战演练
实战部分可能涵盖了如何在实际场景中使用Flink的Join功能,比如实时数据分析、用户行为分析等。这可能涉及到设置窗口、定义Join条件、处理延迟数据等方面。
常见的Join实现方法包括Nested Loop Join、Hash Join和Sort-Merge Join等。Nested Loop Join是最直观的方法,但效率较低,适合小规模数据。Hash Join和Sort-Merge Join则在大数据处理中更为常见,它们通过创建哈希表或对数据进行排序来提高Join的性能。
在Apache Flink中,为了优化性能,可能会采用Broadcast Join策略,尤其是在处理维表(通常较小)时,可以将维表广播到所有并行任务中,减少网络传输的开销。此外,Flink还支持Temporal Table Join,用于处理时态数据,例如历史版本的维表。
Apache Flink提供了丰富的Join机制,适应不同的数据处理需求,无论是SQL查询还是DataStream编程,都能有效地处理维表关联,从而在实时数据处理领域发挥重要作用。了解和掌握这些Join技术对于提升Flink应用的效率和灵活性具有重要意义。
Apache Flink 中学习站:ververica.cn
© Apache Flink Community China 严禁商业途
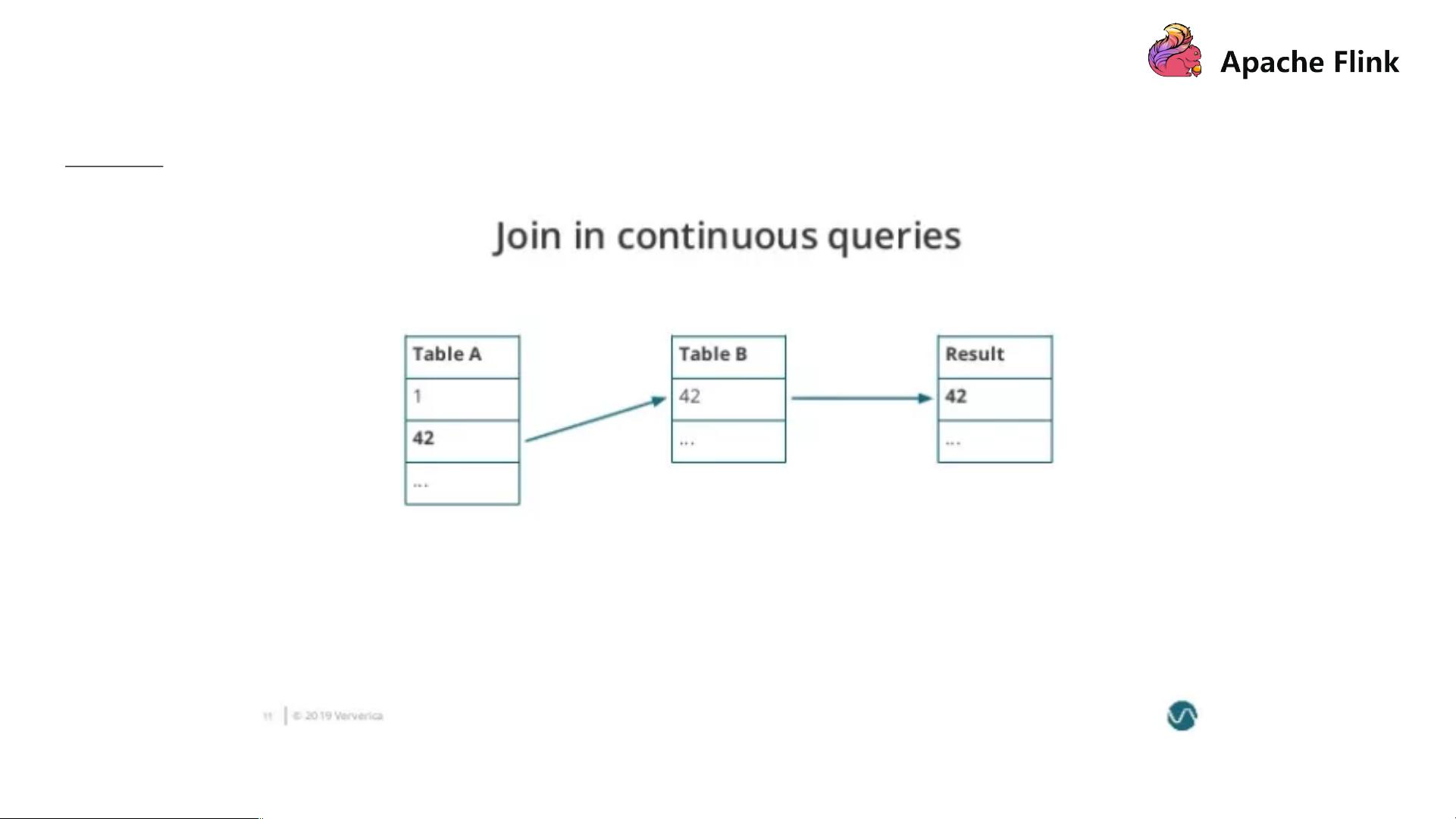
实时 Streaming SQL Join
面向无界数据集的 SQL,无法缓存历史所有数据,因此像 Sort-Merge Join 需要对数据进行排序是无法做到的,
Nested-loop Join 和 Hash Join 经过一定的改良则可以满足实时 SQL 的要求。
剩余42页未读,继续阅读
2020-07-27 上传
2021-12-30 上传
2021-01-29 上传
2024-11-05 上传
2019-11-05 上传
2019-12-25 上传









