G.729编码域DTW说话人识别技术研究
104 浏览量
更新于2024-08-30
收藏 327KB PDF 举报
"基于DTW的编码域说话人识别研究"
本文着重探讨了在VoIP(Voice over IP)环境下,利用动态时间规整(DTW,Dynamic Time Warping)算法进行编码域说话人识别的技术和优势。VoIP技术的普及使得通过网络传输语音成为日常生活和工作中常见的方式,但这也带来了新的挑战,即如何在大量压缩语音数据中高效、准确地识别说话人。
说话人识别是一种生物特征识别技术,其目标是通过分析和处理说话人的语音信号来确定说话人的身份。该技术可以分为两类:文本无关和文本相关。文本无关的识别系统允许说话人在没有任何特定语句限制的情况下自由发言,虽然建模难度较大,但使用更为灵活。相反,文本相关的识别系统要求说话人按照预设内容发音,这通常能提高识别的准确性。
在VoIP环境中,语音信号经过编码压缩处理,如G.729编码,这为说话人识别带来额外的复杂性。研究发现,相对于传统的高斯混合模型(GMM,Gaussian Mixture Model),DTW算法在处理编码域数据时能显著提升识别的正确率和运行效率。DTW是一种处理不同长度序列比较的有效方法,尤其适用于语音信号这种时间变化的非线性数据。
DTW算法的核心思想是通过调整两个序列的时间轴,找到它们之间的最佳匹配路径,即使得两个序列在匹配过程中失真最小。在说话人识别中,这个算法可以帮助识别系统在不同的语音速率和长度下找到相似的语音模式,从而提高识别的准确性。
针对G.729编码域数据的DTW说话人识别方法研究中,研究人员可能涉及到了特征参数的提取,例如梅尔频率倒谱系数(MFCC,Mel Frequency Cepstral Coefficients)、线性预测编码(LPC,Linear Predictive Coding)等。这些特征参数能够捕捉到语音信号的关键特性,用于区分不同的说话人。
除了DTW算法,文章还提到了其他的研究工作,如香港理工大学对G.729和G.723编码比特流以及残差的信息提取,以及分数补偿的方法,这些方法旨在从压缩语音数据中提取更多的识别信息。
基于DTW的编码域说话人识别研究是应对VoIP环境下说话人识别挑战的重要途径,通过优化算法和特征提取技术,能够在保证识别效率的同时提高识别的准确性和可靠性。这项技术对于安全通信、电话服务自动化、智能家居等领域有着广泛的应用前景。
基于基于DTW的编码域说话人识别研究的编码域说话人识别研究
摘要:相对解码重建后的语音进行说话人识别,从VoIP的语音流中直接提取语音特征参数进行说话人识别方法
具有便于实现的优点,针对G.729 编码域数据,研究基于DTW算法的快速说话人识别方法。 实验结果表明I在相
关的说话人识别中,DTW算法相比GMM在识别正确率和效率上有了很大提高。 说话人识别又被称为话者
识别,是指通过对说话人语音信号的分析处理,自动确认说话人是否在所记录的话者集合中,以及进一步确认
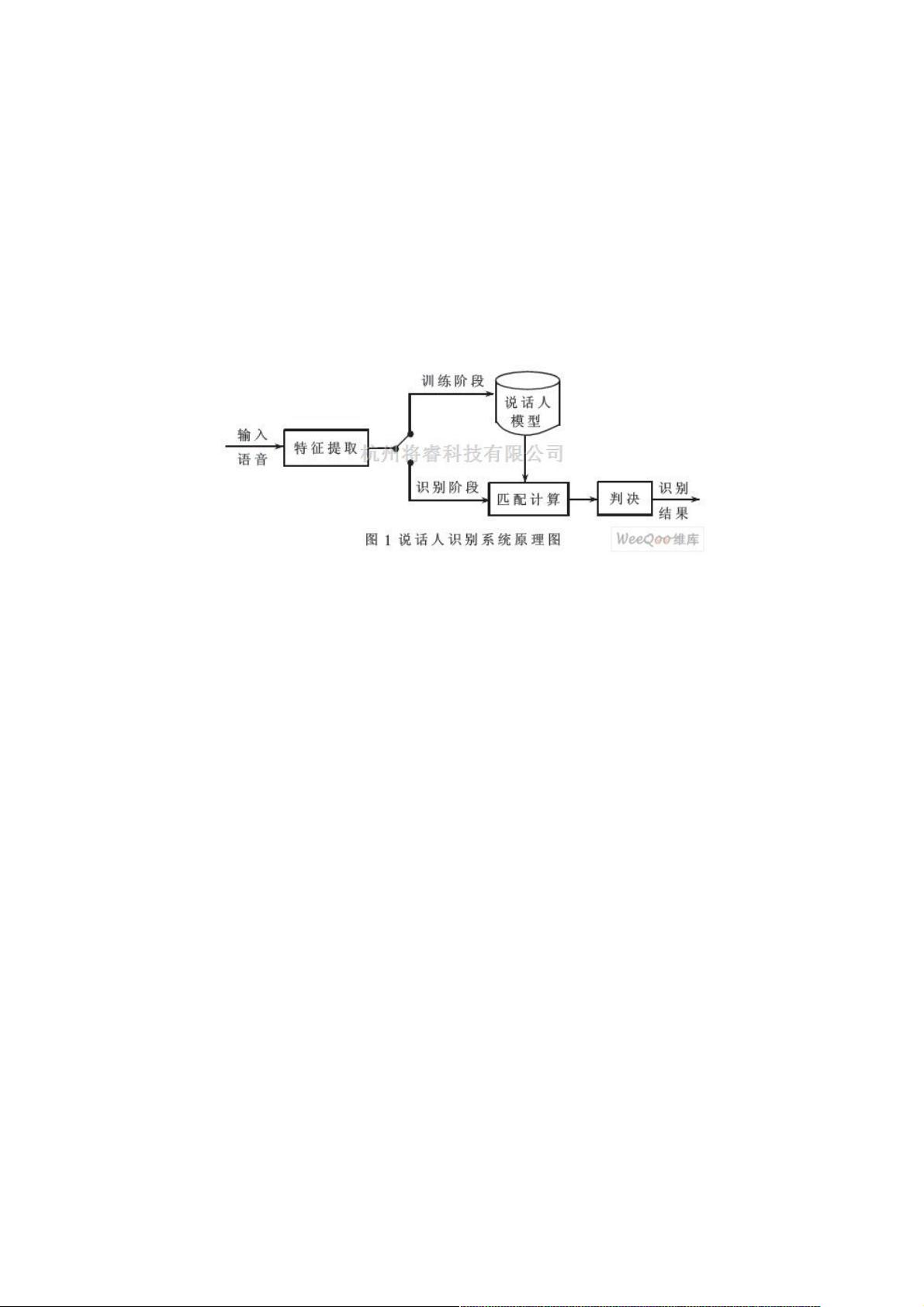
说话人的身份。说话人识别的基本原理如图1所示。 按照语音的内容,说话人识别可以分为文本无关的
(Text-Independent)和文本相关的(Text-Dependent)两种。文本无
摘要:相对解码重建后的语音进行说话人识别,从VoIP的语音流中直接提取语音特征参数进行说话人识别方法具有便于实
现的优点,针对G.729 编码域数据,研究基于DTW算法的快速说话人识别方法。 实验结果表明I在相关的说话人识别中,DTW
算法相比GMM在识别正确率和效率上有了很大提高。
说话人识别又被称为话者识别,是指通过对说话人语音信号的分析处理,自动确认说话人是否在所记录的话者集合中,以
及进一步确认说话人的身份。说话人识别的基本原理如图1所示。
按照语音的内容,说话人识别可以分为文本无关的(Text-Independent)和文本相关的(Text-Dependent)两种。文本无关的
识别系统不规定说话人的发音内容,模型建立相对困难,但用户使用方便。与文本有关的说话人识别系统要求用户按照规定的
内容发音,而识别时也必须按规定的内容发音,因此可以达到较好的识别效果。
随着网络技术的发展,通过Internet网络传递语音的*VoIP(Voice over IP)技术发展迅速,已经成为人们日常交流的重要手
段,越来越多的用户抛弃传统的通信方式,通过计算机网络等媒介进行语音交流。由于VoIP工作方式的特点,语音在传输中
经过了语音编译码处理,VoIP设备端口同时要处理多路、海量的压缩话音数据。所以VoIP说话人识别技术主要研究的是如何
高速、低复杂度地针对解码参数和压缩码流进行说话人识别。
现有的针对编码域说话人识别方法的研究主要集中在编码域语音特征参数的提取上,香港理工大学研究从G.729和G.723
编码比特流以及残差中提取信息,并采用了分数补偿的方法。中国科学技术大学主要研究了针对AMR语音编码的说话人识
别。西北工业大学在说话人确认中针对不同的语音编码差异进行了补偿算法研究,并且研究了直接在G.729编码的比特流中提
取参数的方法。说话人模型则主要采用在传统说话人识别中应用最广泛的GMM-UBM(Gaussian Mixture Model-Universal
Background Model)。GMM-UBM的应用效果和混元数目密切相关,在保证识别率的基础上,其处理速度无法满足VoIP环境下
高速说话人识别的需求。
本文研究VoIP语音流中G.729编码域的说话人实时识别,将DTW识别算法成功应用在G.729编码域的文本相关的说话人实
时识别。
1 G.729编码比特流中的特征提取编码比特流中的特征提取
1.1 G.729编码原理编码原理
ITU-T在1996年3月公布G.729编码,其编码速率为8 kb/s,采用了对结构代数码激励线性预测技术(CS-ACELP),编码
结果可以在8 kb/s的码率下得到合成音质不低于32 kb/s ADPCM的水平。 G.729的算法延时为15 ms。由于G.729编解码器具
有很高的语音质量和很低的延时,被广泛地应用在数据通信的各个领域,如VoIP和H.323网上多媒体通信系统等。
G.729的编码过程如下:输入8 kHz采样的数字语音信号先经过高通滤波预处理,每10 ms帧作一次线性预测分析,计算10
阶线性预测滤波器系数,然后把这些系数转换为线谱对(LSP)参数,采用两级矢量量化技术进行量化。自适应码本搜索时,
以原始语音与合成语音的误差知觉加权最小为测度进行搜索。固定码本采用代数码本机构。激励参数(自适应码本和固定码本
参数)每个子帧(5 ms,40个样点)确定一次。
1.2 特征参数提取特征参数提取
直接从G.729 编码流中按照量化算法解量化可以得到LSP参数。由于后段的说话人识别系统还需要激励参数,而在激励参
数的计算过程中经过了LSP的插值平滑,所以为了使特征矢量中声道和激励参数能准确地对应起来,要对解量化的LSP参数采
用插值平滑。
下载后可阅读完整内容,剩余4页未读,立即下载
2023-12-22 上传
2021-09-30 上传
2021-05-20 上传
2018-07-23 上传
2015-03-25 上传
2021-07-10 上传
2021-06-26 上传
2022-06-28 上传
2022-07-03 上传

weixin_38721398
- 粉丝: 4
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- JSP+SSM科研管理系统响应式网站设计案例
- 推荐一款超级好用的嵌入式串口调试工具
- PHP域名多维查询平台:高效精准的域名搜索工具
- Citypersons目标检测数据集:Yolo格式下载指南
- 掌握MySQL面试必备:程序员面试题解析集锦
- C++软件开发培训:核心技术资料深度解读
- SmartSoftHelp二维码工具:生成与解析条形码
- Android Spinner控件自定义字体大小的方法
- Ubuntu Server on Orangepi3 LTS 官方镜像发布
- CP2102 USB驱动程序的安装与更新指南
- ST-link固件升级指南:轻松更新程序步骤
- Java实现的质量管理系统Demo功能分析与操作
- Everything高效文件搜索工具:快速精确定位文件
- 基于B/S架构的酒店预订系统开发实践
- RF_Setting(E22-E90(SL)) V1.0中性版功能解析
- 高效转换M3U8到MP4:免费下载工具发布
