非负矩阵分解与谱聚类:PCA和机器学习教程
需积分: 0 154 浏览量
更新于2024-08-01
收藏 482KB PDF 举报
"PCA&Matrix Factorization for Learning, ICML2005 Tutorial, Chris Ding"
在机器学习领域,谱聚类(Spectral Clustering)和主成分分析(PCA)以及矩阵分解是重要的数据处理和分析工具。这篇由Chris Ding在ICML 2005上给出的教程详细探讨了这些概念及其相互关系。
谱聚类是一种非监督学习方法,主要用于将数据集分割成多个簇。它利用图论中的谱理论,通过计算数据点之间的相似性构建图,然后通过对图的拉普拉斯矩阵进行特征分解来找到簇的结构。在这个过程中,数据点被表示为图的顶点,相似度作为边的权重。谱聚类的优势在于它可以处理非凸形状的簇,并且对于噪声和异常值具有一定的鲁棒性。
主成分分析是一种降维技术,它通过线性变换将原始数据转换到一个新的坐标系中,新坐标系里的维度按方差大小排序,保留最重要的主成分,从而减少数据的复杂性。PCA的核心思想是找到数据最大方差的方向,这样可以尽可能多地保留数据的信息。
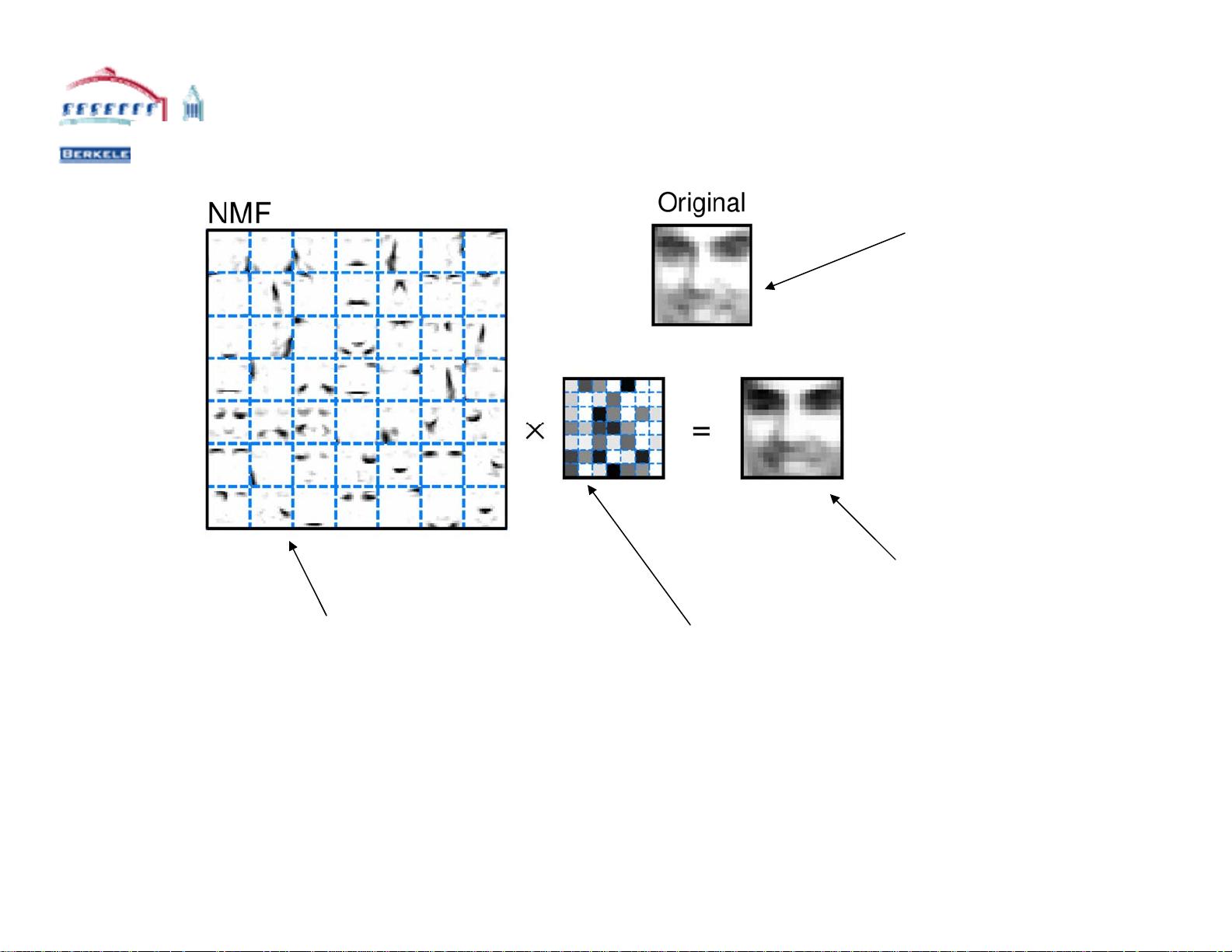
非负矩阵分解(Non-negative Matrix Factorization, NMF)是另一种矩阵分解方法,它将数据矩阵分解为两个非负矩阵的乘积。在NMF中,数据矩阵X近似分解为两个非负矩阵F和G的乘积,其中F代表基,G代表系数。NMF常用于图像、文档和网页等数据的分析,因为它能捕捉到数据的正向特性,比如在文档中,词频不可能为负。
NMF与K-means聚类和谱聚类之间存在联系。K-means是一种简单且广泛使用的聚类算法,寻找使得内部平方距离之和最小的划分。NMF可以通过寻找非负基来近似数据,这在某些情况下可以视为一种软聚类,而K-means是硬聚类。谱聚类则利用图谱理论,通过拉普拉斯矩阵的特征向量进行聚类,这与NMF的优化目标有一定的相似性。
Chris Ding的教程还提到了NMF的历史,包括早期的工作,如统计学家P. Paatero在1994年的研究以及Lee和Seung在1999年和2000年的贡献。他们提出的乘积更新算法是NMF算法发展的重要里程碑。
谱聚类、PCA和NMF是数据科学和机器学习中的基础工具,它们在数据分析、图像处理、文本挖掘等多个领域有广泛应用。理解并熟练掌握这些技术对于解决复杂的数据问题至关重要。
PCA & Matrix Factorization for Learning, ICML 2005 Tutorial, Chris Ding 104
),,,(
21 k
fffF L= ),,,(
21 k
gggG L=
T
FGX ≈
),,,(
21 n
xxxX L=
Parts-based perspective
剩余22页未读,继续阅读
328 浏览量
1663 浏览量
2074 浏览量
166 浏览量
2023-07-11 上传
2023-05-26 上传
295 浏览量
218 浏览量
2023-07-11 上传

njyyc
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 富文本编辑器图片获取与缩略图设置方法
- 亿图画图工具:便捷流程图设计软件
- C#实现移动二次曲面拟合法在DEM内插中的应用
- Symfony2中VreshTwilioBundle:Twilio官方SDK的扩展包装器
- Delphi调用.NET DLL的Win32交互技术解析
- C#基类库大全:全面解读.NET类库与示例
- 《计算机应用基础》第2版PPT教学资料介绍
- VehicleHelpAPI正式公开:发布问题获取使用权限
- MATLAB车牌自动检测与识别系统
- DunglasTorControlBundle:Symfony环境下TorControl的集成实现
- ReactBaiduMap:打造React生态的地图组件解决方案
- 卡巴斯基KEY工具:无限期循环激活解决方案
- 简易绿色版家用FTP服务器:安装免、直接配置
- Java Mini Game Collection解析与实战
- 继电器项目源码及使用说明
- WinRAR皮肤合集:满足不同风格需求
