
golang协程池设计详解协程池设计详解
主要介绍了golang协程池设计详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参
考学习价值,需要的朋友们下面随着小编来一起学习学习吧
Why Pool
go自从出生就身带“高并发”的标签,其并发编程就是由groutine实现的,因其消耗资源低,性能高效,开发成本低的特性而被
广泛应用到各种场景,例如服务端开发中使用的HTTP服务,在golang net/http包中,每一个被监听到的tcp链接都是由一个
groutine去完成处理其上下文的,由此使得其拥有极其优秀的并发量吞吐量
for {
// 监听tcp
rw, e := l.Accept()
if e != nil {
.......
}
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew) // before Serve can return
// 启动协程处理上下文
go c.serve(ctx)
}
虽然创建一个groutine占用的内存极小(大约2KB左右,线程通常2M左右),但是在实际生产环境无限制的开启协程显然是不科
学的,比如上图的逻辑,如果来几千万个请求就会开启几千万个groutine,当没有更多内存可用时,go的调度器就会阻塞groutine
最终导致内存溢出乃至严重的崩溃,所以本文将通过实现一个简单的协程池,以及剖析几个开源的协程池源码来探讨一下对
groutine的并发控制以及多路复用的设计和实现。
一个简单的协程池一个简单的协程池
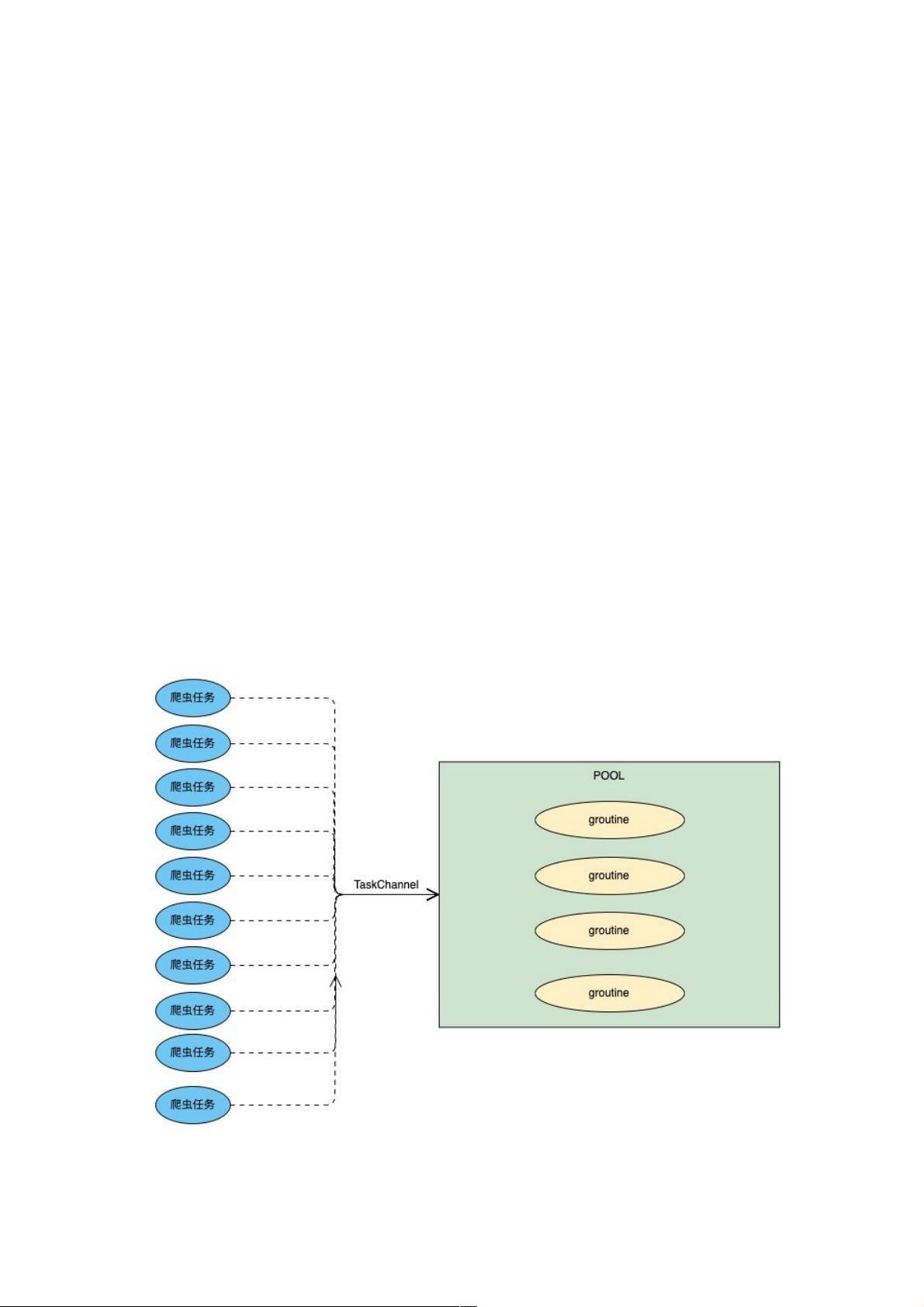
过年前做过一波小需求,是将主播管理系统中信息不完整的主播找出来然后再到其相对应的直播平台爬取完整信息并补全,当
时考虑到每一个主播的数据都要访问一次直播平台所以就用应对每一个主播开启一个groutine去抓取数据,虽然这个业务量还
远远远远达不到能造成groutine性能瓶颈的地步,但是心里总是不舒服,于是放假回来后将其优化成从协程池中控制groutine
数量再开启爬虫进行数据抓取。思路其实非常简单,用一个channel当做任务队列,初始化groutine池时确定好并发量,然后
以设置好的并发量开启groutine同时读取channel中的任务并执行, 模型如下图
实现
type SimplePool struct {
wg sync.WaitGroup
work chan func() //任务队列
}
下载后可阅读完整内容,剩余8页未读,立即下载

weixin_38693589
- 粉丝: 5
- 资源: 929
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


