Windows环境下Scrapy安装与项目结构详解
 已收录资源合集
已收录资源合集
需积分: 0 178 浏览量
更新于2024-08-04
收藏 115KB DOCX 举报
"本资源主要介绍了如何在Windows环境下安装Scrapy框架,并提供了遇到问题时的解决方案,以及如何新建Scrapy项目、配置项目结构、编写爬虫文件、设置数据存储和处理,以及并发设置的相关知识。"
Scrapy是一个强大的Python爬虫框架,用于高效地抓取网站内容并提取结构化数据。在Windows上安装Scrapy,首先需要确保你已经安装了Python 3.7。通过命令`pip install scrapy`来安装Scrapy。如果安装过程中出现错误提示需要vc14库,这可能是因为缺少Twisted库。你可以访问<https://www.lfd.uci.edu/~gohlke/pythonlibs/>,找到与你Python版本对应的Twisted包,下载后使用pip安装。
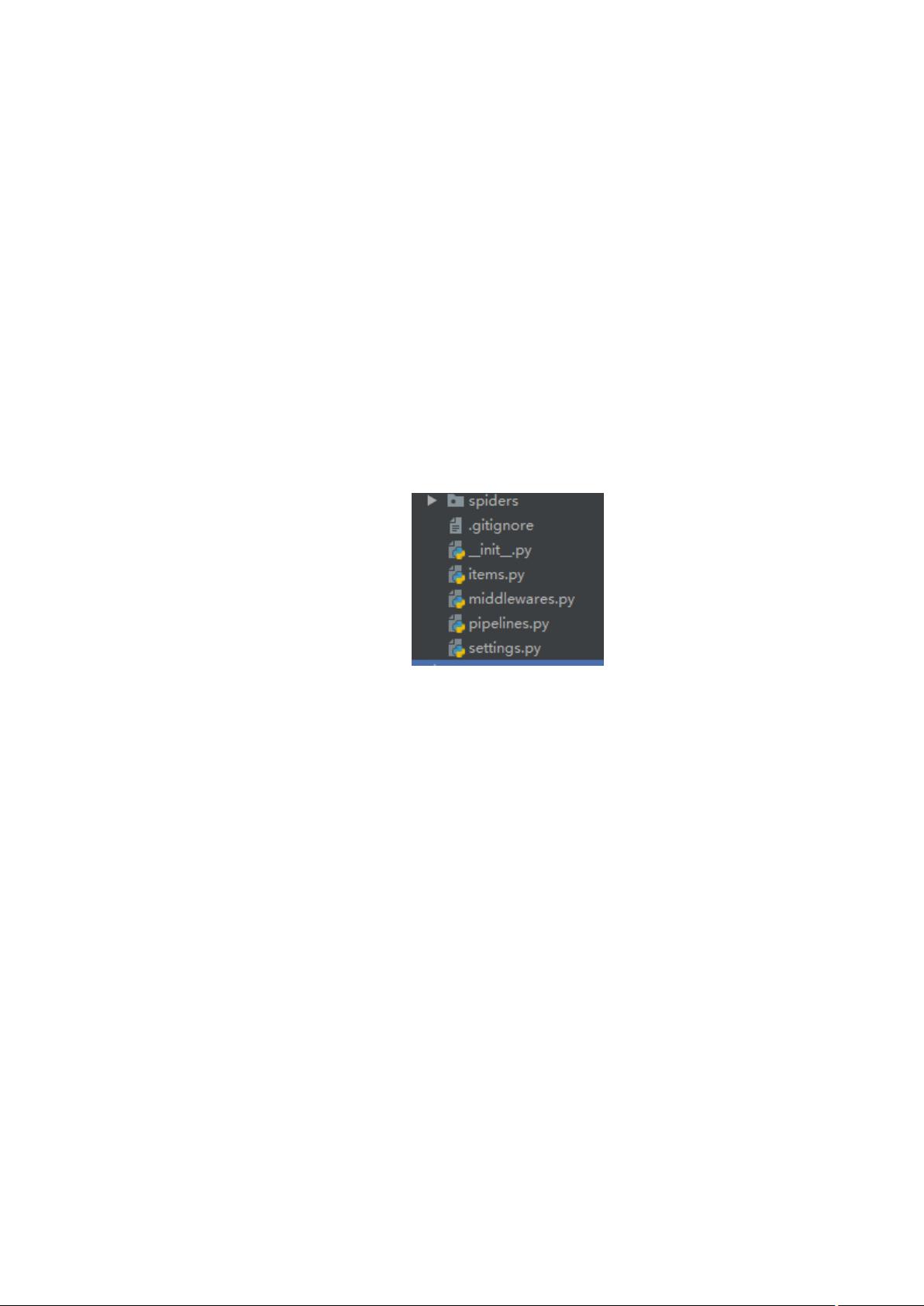
新建一个Scrapy项目,可以使用命令`scrapy startproject [project_name]`,例如`scrapystartproject sdk`。这个命令会创建一个项目结构,包括以下几个核心文件:
1. `spiders/`:存放爬虫代码的目录。
2. `items.py`:定义数据结构,用于存储爬取的数据。
3. `middleware.py`:添加自定义中间件,用于扩展Scrapy的功能,如IP代理、请求延迟等。
4. `pipelines.py`:处理爬取的数据,进行持久化存储或清洗等操作。
5. `settings.py`:设置爬虫的行为,如下载延迟、中间件、管道等。
在`spiders`目录下,创建一个爬虫文件,如`login.py`,编写接口测试用例。你可以设置`start_urls`只包含需要测试的接口,并重写`start_requests`方法构造请求参数。使用`scrapy.Request`发送POST请求,并指定回调函数`parse_page`。
在`items.py`中定义你需要抓取的数据模型。在`parse_page`回调函数中,解析网页内容,使用选择器(如XPath或CSS)提取数据。
`pipelines.py`是处理和存储数据的地方,你可以定义类来处理数据,如清洗、验证、存储到数据库等。在`settings.py`中设置`ITEM_PIPELINES`,将权重设置为300表示该管道优先级较高。
如果在运行爬虫时遇到`No module named win32api`的错误,可以通过`pip install pypiwin32`来安装缺失的模块。
对于并发设置,Scrapy提供了以下两个选项:
1. 设置`dont_filter=True`在请求中,防止Scrapy过滤掉重复的URL,这有助于并发请求同一接口。
2. 在`settings.py`中调整并发参数,如`CONCURRENT_REQUESTS`(每个域名的并发请求数)、`DOWNLOAD_DELAY`(下载延迟)和`CONCURRENT_REQUESTS_PER_DOMAIN`(每个域名的并发请求数限制),以优化爬虫性能。
以上就是Scrapy的安装、项目结构、爬虫编写、数据处理和并发设置的基本步骤。通过这些知识,你可以开始构建自己的网络爬虫项目。
1.Scrapy 安装:在 windows 环境 python3.7 上进
行安装,命令 pip install scrapy
2.如 果 安 装 失 败 提 示 需 要 vc14 的 库 , 检 查
twisted 是否安装成功,如果因为 twisted 问题可
以在 https://www.lfd.uci.edu/~gohlke/pythonlibs/
上下载对应 twisted 包进行 pip 安装
3.新建 scrapy 项目:scrapy startproject sdk
4.新建项目结构如图
5.spiders/是编写爬虫的地方
6.items.py 是数据存储模板,用于结构化数据
7.middleware.py 是添加中间件的地方
8.pipelines.py 做数据处理永久化存储
9.settings.py 爬虫设置
10. 在 spiders 目 录 下 新 建 一 个 爬 虫 文 件
login.py 编 写 接 口 测 试 用 例
下载后可阅读完整内容,剩余3页未读,立即下载
412 浏览量
1451 浏览量
2024-12-20 上传
2022-08-03 上传
897 浏览量
104 浏览量
131 浏览量
122 浏览量
125 浏览量

行走的瓶子Yolo
- 粉丝: 37
- 资源: 342
 我的内容管理
展开
我的内容管理
展开







