营养爬虫:理解《中国膳食指南》的个人需求计算与数据流程
需积分: 0 109 浏览量
更新于2024-08-05
收藏 695KB PDF 举报
在"爬虫需求文档1"中,主要关注的是如何根据个人的营养需求进行食物选择和管理。文档的核心知识点集中在以下几个方面:
1. 营养需求计算:文档引用了《中国⼈⺠膳⾷指南》作为标准,通过年龄、性别和体重等因素,确定个人每日所需的营养素推荐摄入量(RNI)和适宜摄入量(AI)。其中,对于乳喂养者,AI会相应增加20%。这里的计算通常涉及基础的能量需求(能量消耗率,PAL,即体活动水平),以及各种宏量营养素如蛋白质、脂肪的建议摄取量。
2. 数据源与数据库设计:文档提及的数据流程涉及到一个云数据库,名为"HealthyLife",存储在IP地址122.51.38.230的端口3306上,使用用户名"xiangli"和密码"123456"进行访问。数据库中存在多个表格,如"nutrition_energy",用于存储营养素推荐摄入量的信息,包括但不限于能量、蛋白质、脂肪率等,以及其他微量元素如钙、磷、铁等的含量。
3. 食物成分查询:提供两个链接,一个是详细的食物质地成分数据库,<https://fq.chinafcd.org/>,可以查询到各种食物的具体营养元素信息;另一个是菜谱资源,<https://www.shipuxiu.com/zuofadaquan/861852/>,列出食物名称和用量,便于按照营养需求规划膳食。
4. 爬虫需求概述:文档中提到的爬虫主要用于收集和整合这些营养信息,以便于自动化处理和分析。它关注的主要数据抓取点包括营养素需求表、食物成分表和菜谱数据。爬虫的目标是确保数据的准确性和实时性,以便用户可以根据个人需求获取个性化的营养指导。
5. 数据表结构:文档还详细列出了几个关键数据表的结构,包括年龄、性别、PAL、各类营养素等字段,这些数据将作为爬虫抓取和解析的基础。
这个爬虫需求文档的核心目标是利用技术手段自动化处理营养信息,为用户提供个性化和科学的膳食建议,以支持健康生活。通过连接不同的数据源,爬虫将整合并分析用户的个人特征和营养需求,生成定制化的饮食计划。
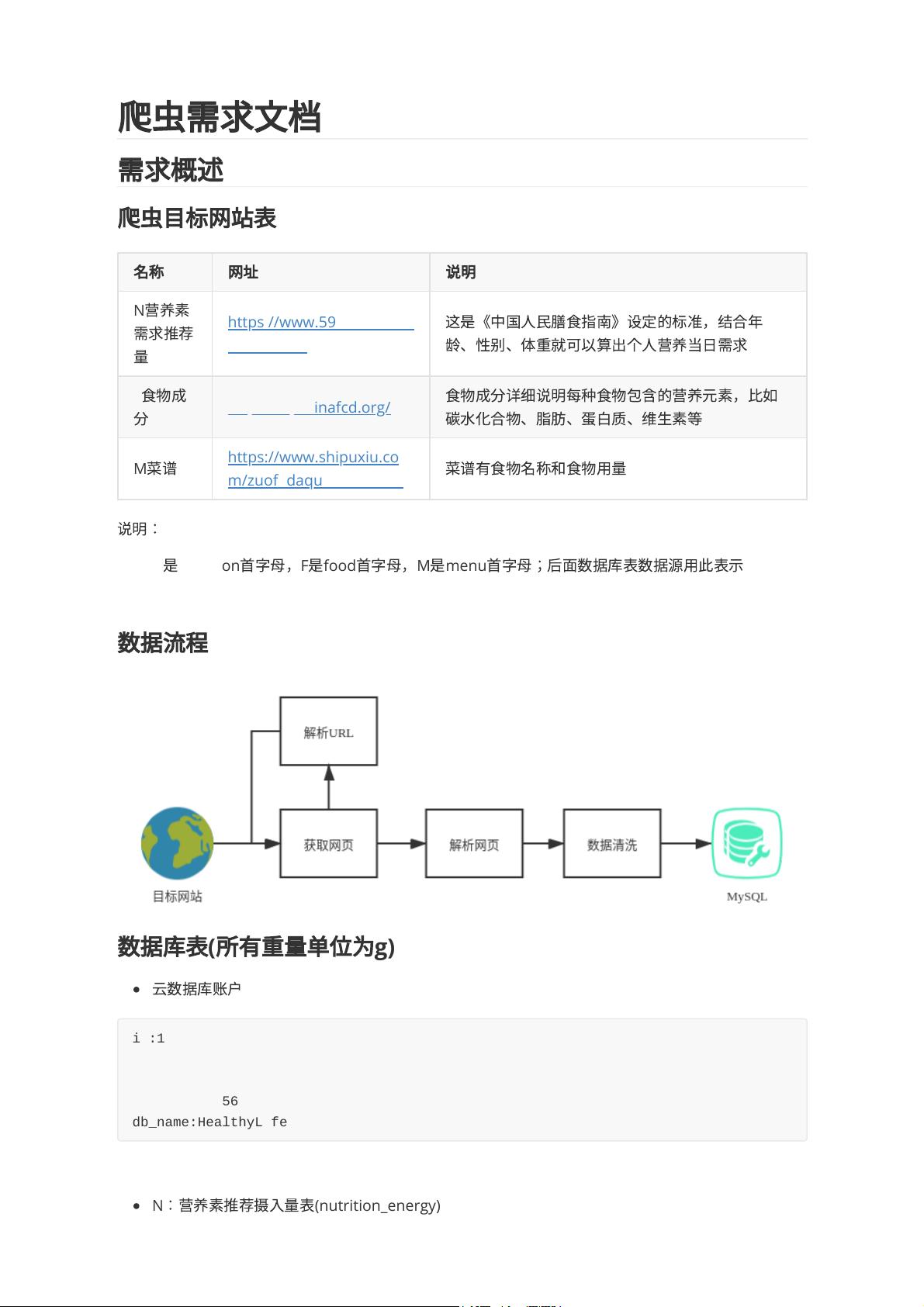
名
称
⽹
址
说
明
N
营
养
素
需
求
推
荐
量
https://www.59baike.com/
a/42787-33
这
是
《
中
国
⼈
⺠
膳
⾷
指
南
》
设
定
的
标
准
,
结
合
年
龄
、
性
别
、
体
重
就
可
以
算
出
个
⼈
营
养
当
⽇
需
求
F
⾷
物
成
分
https://fq.chinafcd.org/
⾷
物
成
分
详
细
说
明
每
种
⾷
物
包
含
的
营
养元
素
,
⽐
如
碳
⽔
化
合
物
、
脂
肪
、
蛋
⽩
质
、
维
⽣
素
等
M
菜
谱
https://www.shipuxiu.co
m/zuofadaquan/861852/
菜
谱
有
⾷
物
名
称
和
⾷
物
⽤
量
爬
⾍
需
求
⽂
档
需
求
概
述
爬
⾍
⽬
标
⽹
站
表
说
明
:
1. N
是
nutrition
⾸
字
⺟
,
F
是
food
⾸
字
⺟
,
M
是
menu
⾸
字
⺟
;
后
⾯
数
据
库
表
数
据
源
⽤
此
表
⽰
数
据
流
程
数
据
库
表
(
所
有
重量
单
位
为
g)
云
数
据
库
账
户
N
:
营
养
素
推
荐
摄
⼊
量
表
(nutrition_energy)
ip:122.51.38.230
port:3306
user:xiangli
passwd:123456
db_name:HealthyLife
下载后可阅读完整内容,剩余3页未读,立即下载
2022-10-16 上传
2011-06-22 上传
300 浏览量
2011-12-21 上传
2022-08-08 上传
2016-07-10 上传
2022-08-08 上传
2018-12-13 上传

点墨楼
- 粉丝: 37
- 资源: 279
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
