信用卡欺诈检测:逻辑回归模型与SMOTE平衡样本
需积分: 0 156 浏览量
更新于2024-08-05
收藏 1.64MB PDF 举报
"信用卡欺诈检测--逻辑回归"
在金融领域,尤其是信用卡交易中,欺诈检测是一项至关重要的任务,因为欺诈行为可能导致巨大的经济损失。本项目主要关注如何利用逻辑回归这一统计模型来识别潜在的信用卡欺诈行为。以下是详细的知识点介绍:
1. **数据探索**:
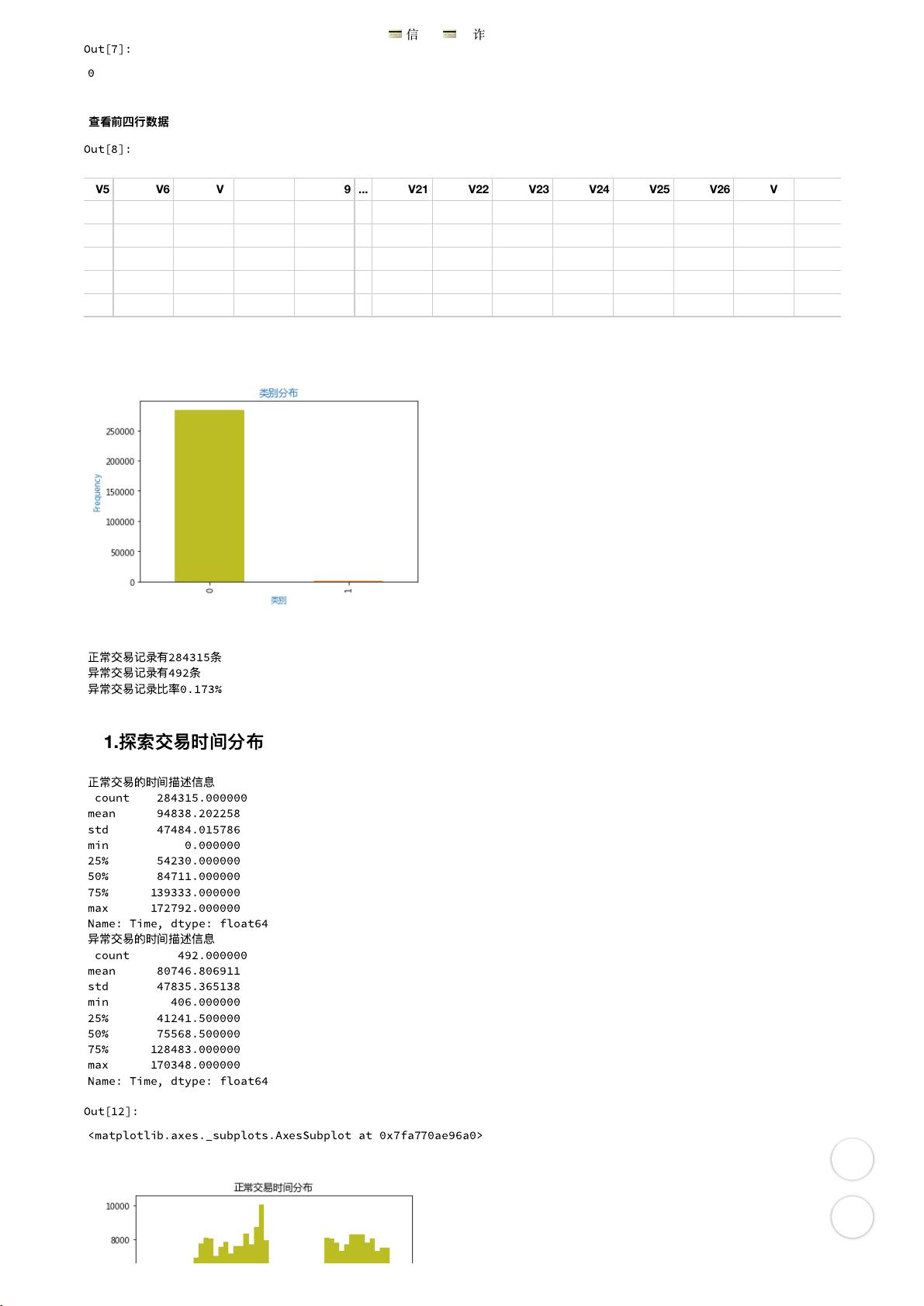
- **探索交易时间分布**:通过分析交易发生的时间,可以寻找欺诈交易的模式,比如是否集中在特定时段或是否有异常的频繁交易。
- **探索交易金额分布**:欺诈交易通常涉及异常的交易金额,可能是异常的大额或小额交易。通过绘制直方图或箱线图,可以发现是否存在异常值或异常分布。
2. **数据预处理**:
- **标准化**:在逻辑回归之前,通常需要对数值特征进行标准化,使所有特征具有相同的尺度,这样可以避免因特征尺度差异导致的模型拟合不准确。
- **处理不平衡样本**:在欺诈检测问题中,欺诈交易通常是少数类,这会导致模型偏向多数类(非欺诈)。为了克服这个问题,可以采用过采样(如SMOTE)或欠采样技术,以平衡两类样本的数量。
3. **使用SMOTE(Synthetic Minority Over-sampling Technique)**:
- SMOTE是一种常用的处理类别不平衡的方法,它通过生成合成的少数类样本来增加其数量。这种方法可以帮助模型更好地学习少数类的特征,提高对欺诈交易的识别能力。
4. **建模与模型评估**:
- **逻辑回归(Logistic Regression)**:逻辑回归是一种分类模型,特别适合二分类问题。在欺诈检测中,它可以预测一个交易是否为欺诈。该模型基于线性回归的结果,通过sigmoid函数将其转化为概率。
- **模型评估**:使用**混淆矩阵(Confusion Matrix)**可以评估模型的性能,包括真阳性、真阴性、假阳性和假阴性,进一步计算出准确率、精确率、召回率和F1分数。**ROC曲线(Receiver Operating Characteristic)**是另一个重要的评估工具,它展示了不同阈值下的真正例率和假正例率,AUC(Area Under the Curve)是ROC曲线下的面积,越大表示模型性能越好。
5. **代码实践**:
- 使用Python的数据科学库,如`numpy`和`pandas`进行数据操作,`plotly`进行数据可视化,以及`plotly.offline`在本地展示图形。
- `!ls ../input/fraud_detection`命令用于查看输入数据集的目录,确保数据已正确加载。
- `import`语句导入了必要的库,如`__version__`用于查看`plotly`库的版本。
这个项目旨在通过数据探索、预处理、构建逻辑回归模型和模型评估,来有效地检测信用卡欺诈行为,其中SMOTE的使用是解决不平衡数据的关键步骤。通过这样的流程,可以构建一个能够对欺诈交易做出准确预测的模型。
2019/2/28
信用卡
欺诈检测--逻辑回归 - Kesci.com
https://www.kesci.com/home/project/5bf7a281954d6e001066ac53 3/13
查
看
前
四
行
数据
1.1.
探
索
交
易时
间
分
布
Out
[7]:
0
Out
[8]:
V5 V6 V7 V8 V9 ... V21 V22 V23 V24 V25 V26 V27 V2
8321 0.462388 0.239599 0.098698 0.363787 ... -0.018307 0.277838 -0.110474 0.066928 0.128539 -0.189115 0.133558 -0.02105
0018 -0.082361 -0.078803 0.085102 -0.255425 ... -0.225775 -0.638672 0.101288 -0.339846 0.167170 0.125895 -0.008983 0.014724
3198 1.800499 0.791461 0.247676 -1.514654 ... 0.247998 0.771679 0.909412 -0.689281 -0.327642 -0.139097 -0.055353 -0.05975
0309 1.247203 0.237609 0.377436 -1.387024 ... -0.108300 0.005274 -0.190321 -1.175575 0.647376 -0.221929 0.062723 0.061458
7193 0.095921 0.592941 -0.270533 0.817739 ... -0.009431 0.798278 -0.137458 0.141267 -0.206010 0.502292 0.219422 0.215153
正
常
交
易
记
录
有
284315
条
异常
交
易
记
录
有
492
条
异常
交
易
记
录
比
率
0.173
%
正
常
交
易
的
时
间
描
述
信
息
count
284315.000000
mean
94838.202258
std
47484.015786
min
0.000000
25
%
54230.000000
50
%
84711.000000
75
%
139333.000000
max
172792.000000
Name
:
Time
,
dtype
:
float
64
异常
交
易
的
时
间
描
述
信
息
count
492.000000
mean
80746.806911
std
47835.365138
min
406.000000
25
%
41241.500000
50
%
75568.500000
75
%
128483.000000
max
170348.000000
Name
:
Time
,
dtype
:
float
64
Out
[12]:
<
matplotlib
.
axes
._
subplots
.
AxesSubplot at
0
x
7
fa
770
ae
96
a
0
>
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-29 上传
2019-12-11 上传
2021-04-27 上传
2024-11-06 上传
2024-02-05 上传
2021-05-14 上传

家的要素
- 粉丝: 29
- 资源: 298
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
