使用Spark和StreamSets构建数据管道
需积分: 9 114 浏览量
更新于2024-07-17
收藏 11.02MB PDF 举报
"Building Data Pipelines with Spark and StreamSets是Pat Patterson在SPARK SUMMIT 2017上的演讲主题,他深入探讨了如何利用Spark和StreamSets构建数据管道,涉及数据偏移、数据流采集以及与Spark的集成等多个关键知识点。"
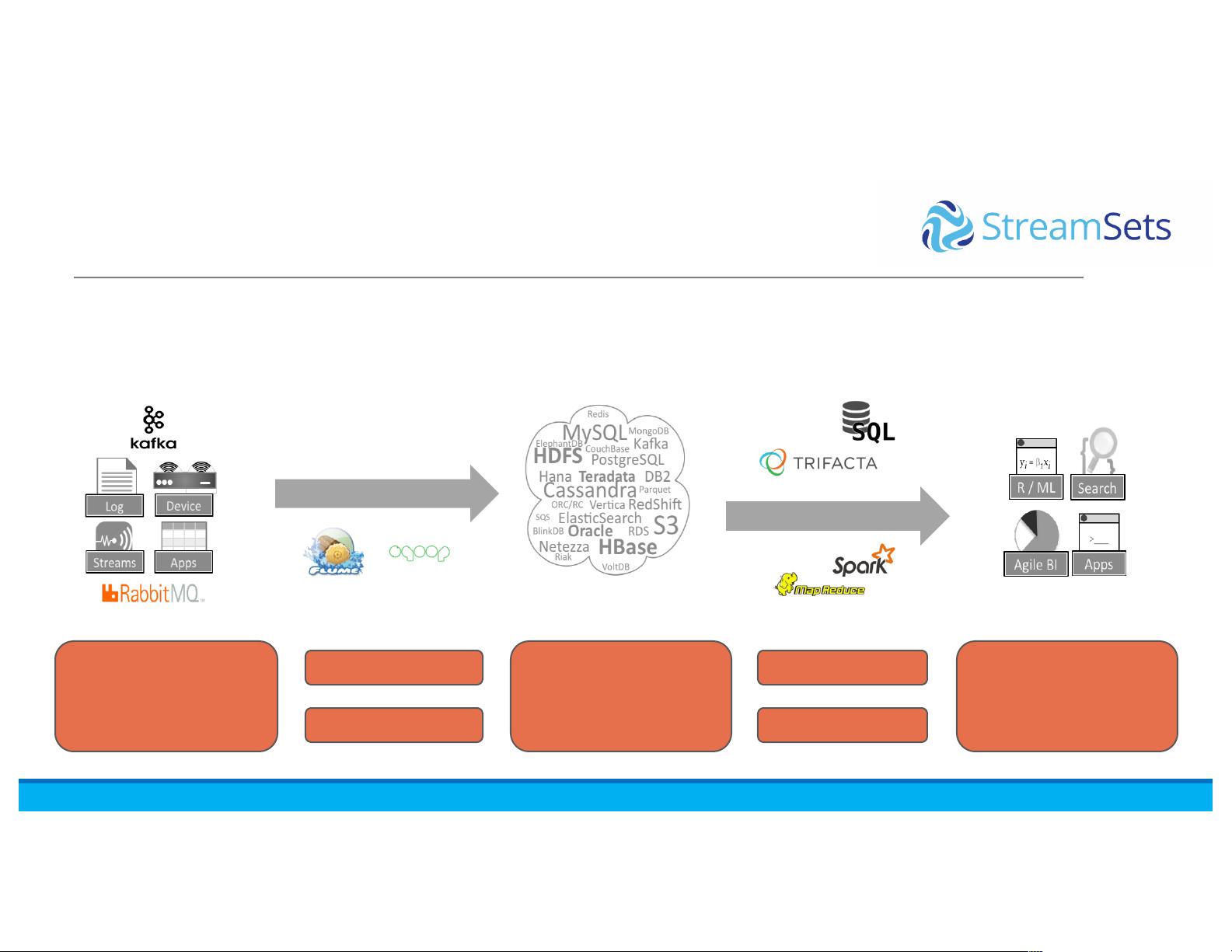
在大数据处理领域,构建高效的数据管道至关重要。Spark作为一款强大的分布式计算框架,被广泛用于实时数据处理和批处理任务。而StreamSets则是一个专门的数据集成工具,旨在解决数据流入和流出过程中的各种挑战。
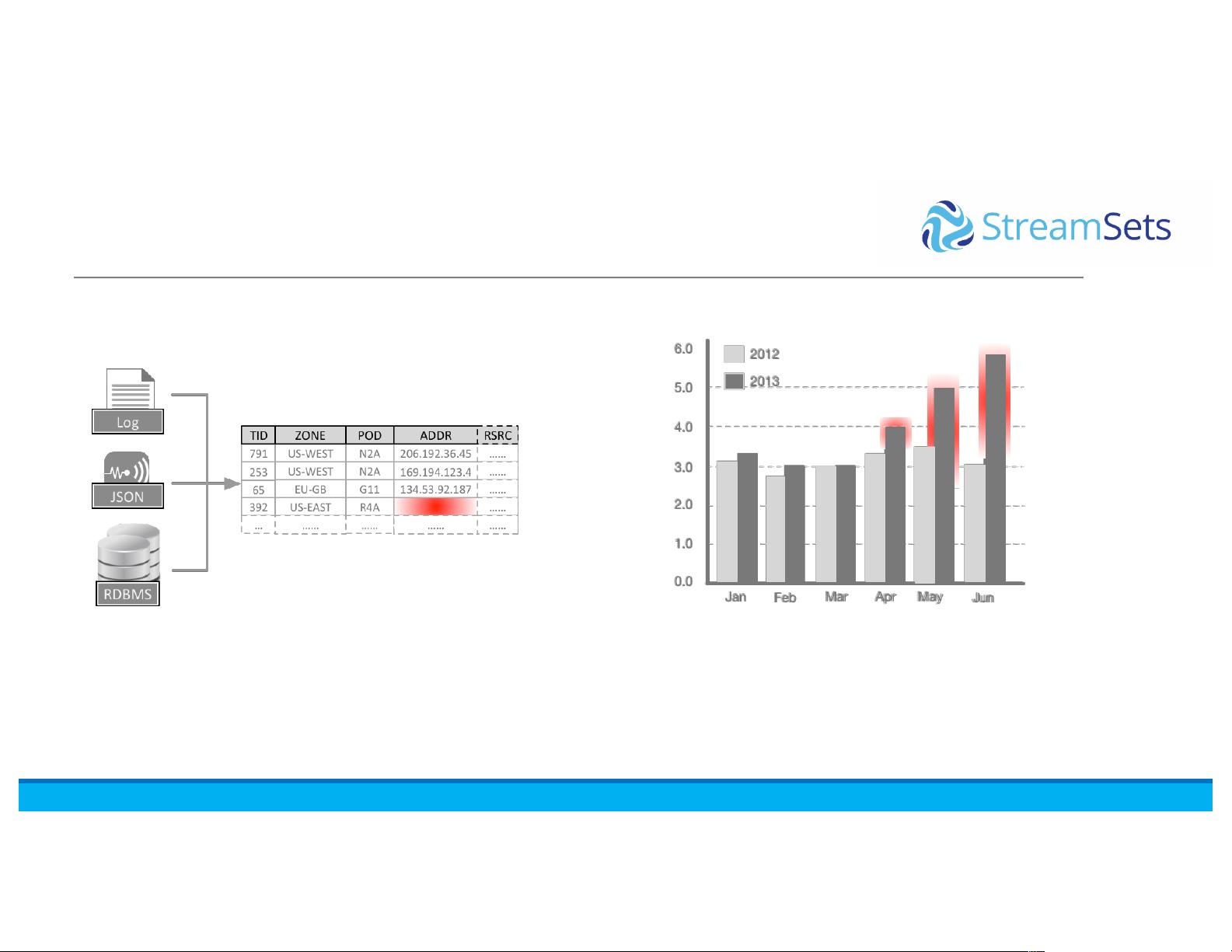
1. 数据偏移(Data Drift):数据偏移是数据工程面临的主要问题之一,它是指数据源的特性在未被预期的情况下发生变化。这种变化可能源于系统的运营、维护或现代化,导致数据结构、语义或基础设施的漂移。例如,数据结构漂移指的是字段的增加、删除或类型改变,语义漂移则涉及到数据含义的变化,而基础设施漂移可能是由于硬件或软件升级引起的。
2. StreamSets数据收集器:StreamSets Data Collector是解决数据偏移问题的一种工具,它允许用户监控和管理数据流,确保数据的准确性和完整性。通过实时检测数据源的变化,它可以自动适应新的数据模式,减少因数据偏移而导致的数据质量问题。
3. Spark集成:演讲中提到在现有的数据管道中运行Spark,这通常意味着利用Spark的并行处理能力加速数据处理。Spark支持批处理、交互式查询(如SQL on Hive)以及流处理,可以无缝地与StreamSets集成,提供从数据摄入到分析的完整解决方案。
4. 未来Spark集成:Pat Patterson可能讨论了未来Spark与StreamSets的进一步集成,可能包括更深度的API整合、性能优化、以及在处理大规模数据偏移时的智能自动化策略。
5. 解决数据偏移的方法:传统上,应对数据偏移往往需要定制代码和固定架构,但这往往效率低下且难以维护。StreamSets提出的意图驱动的漂移处理方法,通过定义数据的关键性能指标(KPIs)和应用,能够自动化检测和处理数据偏移,从而提供可靠的数据洞察。
6. 数据管道的未来:随着云计算的发展,数据管道将变得更加复杂,涉及更多云存储和消费数据的组件。未来的解决方案需要更加灵活和智能,以适应不断变化的数据环境,StreamSets和Spark的结合正是朝着这个方向发展的一个实例。
这场演讲提供了关于如何利用Spark和StreamSets构建健壮、可扩展且能有效处理数据偏移的数据管道的宝贵见解。通过这样的技术组合,数据工程师可以更好地应对现代数据工程面临的挑战,实现快速、准确的数据分析。
SQL -on-Hadoop-(Hive)
Y/Y-Click-Through-Rate
80%(of(analyst(time( is(spent( preparing( and(validating(data,(
while( the( remaining(20%(is(actual(data(analysis
Example:(Data( Loss(and(Corrosion
剩余25页未读,继续阅读
707 浏览量
基于PLC的立体车库,升降横移立体车库设计,立体车库仿真,三层三列立体车库,基于s7-1200的升降横移式立体停车库的设计,基于西门子博图S7-1200plc与触摸屏HMI的3x3智能立体车库仿真控制
2025-01-12 上传
锂电池化成机 姆龙NJ NX程序,NJ501-1400,威伦通触摸屏,搭载GX-JC60分支器进行分布式总线控制,ID262.OD2663等输入输出IO模块ADA801模拟量模块 全自动锂电池化成分容
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传

weixin_38744375
- 粉丝: 373
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







