Spark源码解析:论文与演讲引导的深入理解
需积分: 9 46 浏览量
更新于2024-07-20
收藏 2.43MB DOCX 举报
Apache Spark源码走读深入理解
Apache Spark是一个强大的开源分布式计算框架,其核心是Resilient Distributed Dataset (RDD)的概念。在探索Spark源码之前,理解其背后的理论基础至关重要。首先,阅读Matei Zaharia的Spark论文是入门的好起点,它阐述了Spark的设计理念、架构和关键特性,如弹性分布式数据集(RDD)的定义,以及如何通过transformation和action操作来处理数据。
RDD是Spark的核心抽象,它是只读的、分布式的、容错的数据集,可以看作是分布式计算的基本单元。transformation操作类似于数学中的函数,它不会立即执行,而是创建一个新的RDD,表示对原始数据集的变换。而action操作则会产生最终结果,例如reduce、count或collect,这些操作会触发实际的计算并在集群上执行。
Job是Spark执行的基本单元,由一系列RDD及其操作组成,但只有当action被执行时,整个Job及其依赖的transformation才会被调度到集群中运行。为了优化性能,Spark将Job划分为多个Stage,每个Stage对应一个逻辑上独立的计算步骤,这样可以减少网络传输和重复计算。
数据的划分是通过Partition实现的,一个RDD可能被切分成多个逻辑分区,每个分区在集群的不同节点上存储。依赖关系被组织成有向无环图(DAG),这有助于Spark进行有效的任务调度和内存管理。窄依赖指子RDD仅依赖于父RDD的一个或几个分区,而宽依赖则意味着子RDD与父RDD的所有分区都有关联。
Spark的缓存管理机制(Caching Management)是一个关键特性,它允许用户将中间结果存储在内存中,以便后续操作直接访问,显著提升性能。这种策略对于那些频繁被多次使用的transformation结果尤其有效。
最后,Spark的编程模型基于RDD和基于图的执行计划,开发者通过编写transformation操作构建数据处理流程,然后通过action触发实际执行。整个过程涉及组件如Task、Executor、Driver等,它们共同协作以实现高效的分布式计算。
深入理解Apache Spark源码前,先掌握基本概念、编程模型和核心原理至关重要。通过对论文和演讲的学习,再结合源码阅读,可以更有效地定位和理解代码的设计意图,从而提高对Spark整体架构和实现的理解。
上述代码统计在 :$:4 中含有 的行数有多少
部署过程详解
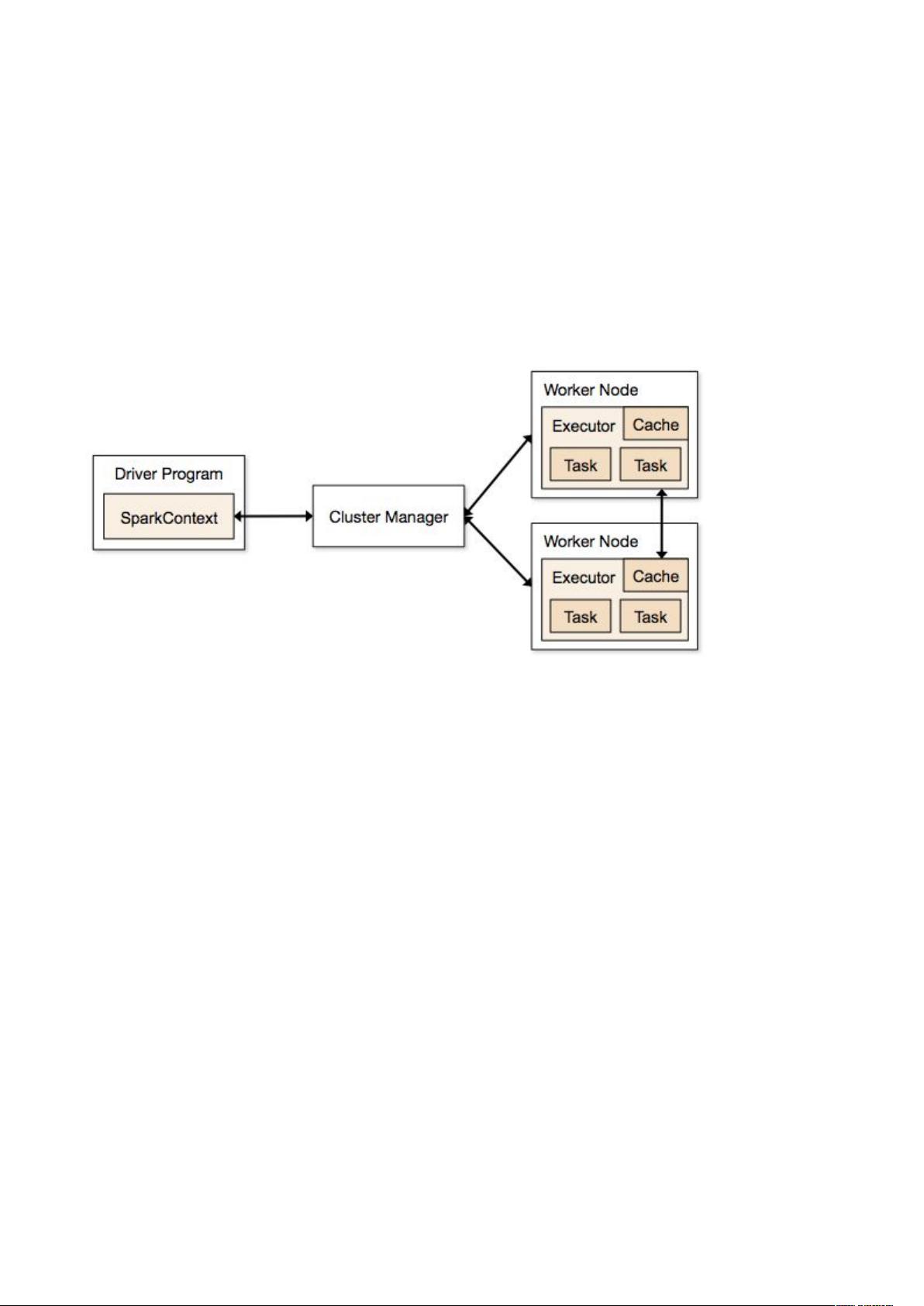
布置环境中组件构成如下图所示。
Driver Program简要来说在 中输入的 ) 语句
对应于上图的 #"4
Cluster Manager!就是对应于上面提到的 ,主要起到 &
" 的作用
Worker Node!与 相比,这是 。上面运行各个
/,/ 可以对应于线程。/ 处理两种基本的业务
逻辑,一种就是 "'另一种就是 5 在提交之后拆分成
各个 ",每个 " 可以运行一到多个


剩余63页未读,继续阅读
2015-01-06 上传
2015-01-06 上传
2015-01-06 上传
2023-05-13 上传
2023-06-09 上传
2023-05-24 上传
2023-05-12 上传
2023-05-12 上传
2023-06-13 上传

hery_csnd168
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
