主动学习与自训练提升多视角姿态估计效率与精度
130 浏览量
更新于2024-06-20
收藏 762KB PDF 举报
本文主要探讨了一种创新的3D姿态估计方法,结合了主动学习(Active Learning, AL)和自训练技术,旨在提高计算机视觉中人体和手部姿态估计的效率,尤其是在数据标注有限的情况下。姿态估计是计算机视觉领域的一个核心任务,它对于动作识别、社交交互理解和手语解析等应用至关重要。然而,深度神经网络的监督学习方法对大量标注数据的依赖使其成本高昂。
传统的监督学习方法依赖于大规模注释数据,如MPII这样的基准,其创建过程需要大量人力和时间。为了克服这个问题,研究者提出了一种新颖的框架,该框架扩展了单视图主动学习策略,利用多视图几何的优势,有效地挑选出最具价值的样本进行人工标注,从而显著降低标注时间和成本。
文中提出了两种新的主动学习策略,它们在多视图设置中更加高效。同时,将主动学习过程中计算出的伪标签(自我训练的一种形式)融入模型,进一步提升了系统的性能。结果显示,相较于传统的注释流程,他们的方法在CMUPanopticStudio和InterHand2.6M这两个大型基准上实现了显著的性能提升,例如在CMUPanopticStudio上,他们的系统能够将注释周转时间和成本分别减少60%和80%,对于复杂和难以识别的“闭塞”案例,也能保持稳定的高质量估计。
总结来说,这篇文章通过引入主动学习和自训练技术,为3D姿态估计提供了一个更有效、低成本的数据驱动解决方案,为计算机视觉领域中的实时应用开辟了新的可能性。这种方法对于那些对标注资源有限的场景,如移动设备或边缘计算环境,具有重要的实际价值。
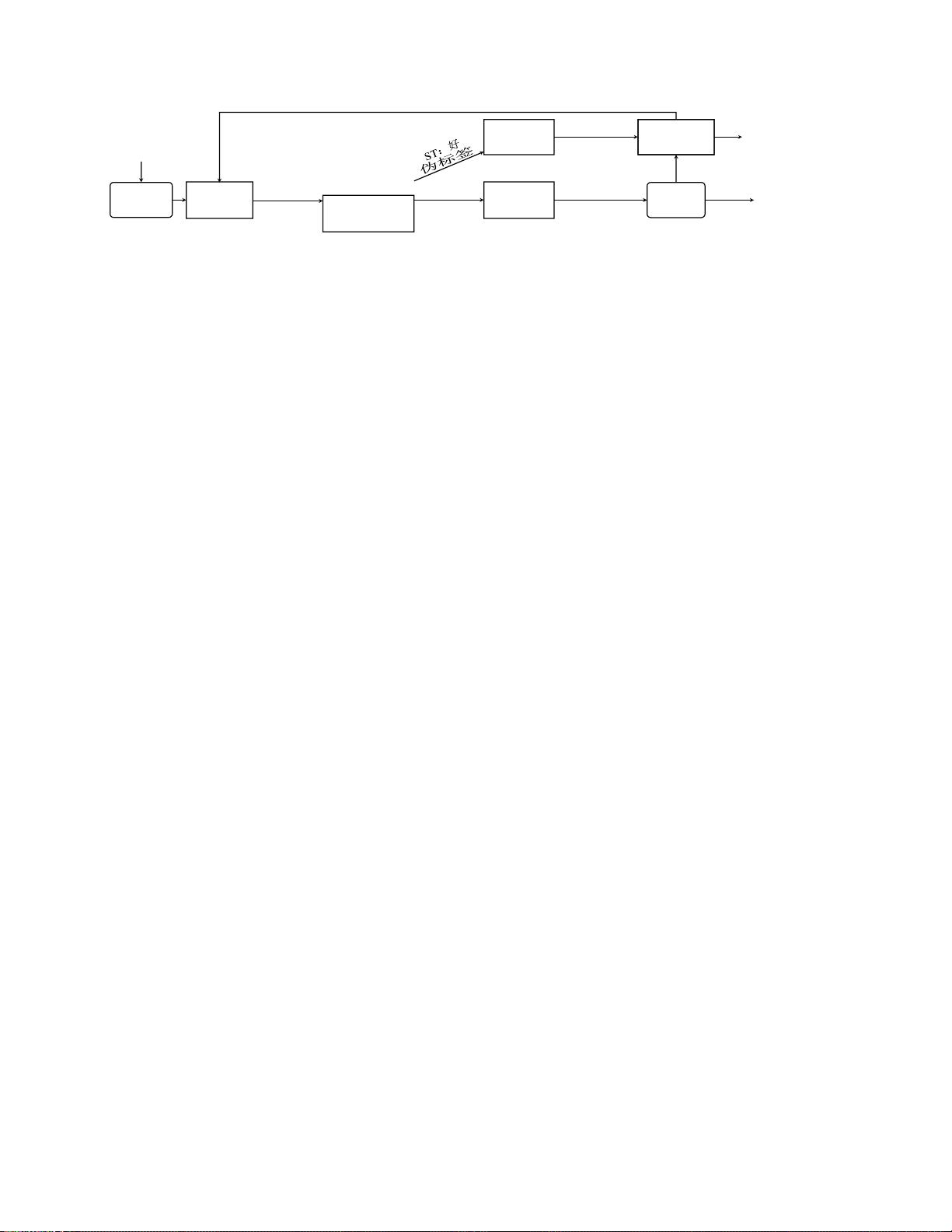
5697
未标记样本池
使用训练模型
进行推理
收集的原始数据
伪标签
训练模型
AL
:不
好
伪标签
从未标记池
添加到
地面实况标
签
标记合并液
姿势估计模型
注释数据
伪标签
图2:所提出的用于多视图3D姿态估计的主动学习(AL)系统的概述虽然先前的作品只考虑了AL的单视图姿态估
计,我们的系统是第一个工作在多视图设置(第二。3.3),我们提出了两个有效的策略,充分利用多视图几何。此
外,通过在建议的自训练过程中加入伪标签(Sec.3.4),我们在没有额外的注释或计算成本的情况下进一步提高了
注释效率
提出了两种新的基于几何启发的、易于计算的人工智能
算法。据我们所知,用于姿态估计的其他现有AL系统
[5,21,44]不考虑多视图输入,并且其中提出的单视
图策略不能很好地推广到多视图设置。
除了主要的AL公式之外,我们还探索了通过
自训练
进一步提高注释效率,这是图像分类的成功策略[28,
41,48]。为此,在每次AL迭代期间,我们使用从模型
的预测计算的伪标签来增强人类注释的标签我们的实验
表明,通过仔细选择,伪标签可以进一步提高姿态估计
性能,而无需额外的注释或计算成本。
我们对两个大规模基准进行注释模拟、实验和消融
研 究 , CMU Panop- tic [18] 用 于 身 体 姿 势 估 计 ,
InterHand2.6M [25]用于手部姿势估计。我们提出的多
视角AL策略,加上自我训练策略,consistently优于基
线策略的显着利润率。值得注意的是,如图1、在CMU
Panoptic上,与现有的数据注释流程相比,我们的完整
系统将注释周转时间减少了60%,注释劳动力成本减少
了80%总之,我们在本文中的贡献有三个方面:
•
我们提出了一种基于主动学习的数据标注过程,用
于从多视图RGB图像进行3D姿态估计,并提出了
利用多视图几何结构来减少标注时间和成本的AL
策略。
•
我们探索自我训练的姿态估计在拟议的AL框架,
并表明,进一步的收益可以实现包括伪标签。
•
我们表明,所提出的AL和自训练策略显着提高了
基线的注释效率,并建立了最先进的AL多视图姿
态估计。
2.
相关工作
3D姿态估计:姿态估计是计算机视觉中的基本任务之
一。为了对可以进行关节连接和变形的人体进行建模,
早期 的方法 大 多 从 经 典 的象 形 结 构 中 获 得 灵感 [2,
10] 。 在 深 度 神 经 网 络 取 得 成 功 之 后 , 并 在 Hu- man
3.6M [15]和MPII [1]等基准的推动下,深度CNN已广泛
应用于身体和手部姿势估计。代表性的方法包括卷积姿
态机[39],堆叠沙漏网络[27],PoseResNet [40],HRNet
[38]
等
。这些方法通常通过预测身体/手部关键点的位置
来工作,被公式化为热图回归问题。另一方面,单视图
3D姿态估计方法[19,20,23,47]直接将2D图像证据
提升到3D关键点或网格表示中,但需要更多高质量的
训练数据以解决固有的2D-3D模糊性。
随着多相机设置的可用性的增加,
多视图
姿态估计
已经聚集了增加的兴趣[12,17,29]。 一个关键的动
机是,这些系统 可用于自动或半自动生成用于单视图
3D姿态估计的“地面实况”,并显著降低标记成本。事
实 上 , 这 样 的 过 程 已 经 在 诸 如 CMU Panoptic [18] 和
HUMBI [45]的基准中被采用用于身体姿势估计,以及
Frei-Hand [47]和InterHand2.6M [25]用于手。然而,训
练多视图模型仍然需要大量的注释的3D姿态数据,这
强烈地激励了诸如主动学习之类的节省成本的策略。
主动学习:主动学习(AL)[7,33]考虑了一个动态环
境,其中ML系统选择未标记的示例来获取标签,并使
用新标记的数据迭代地这在注释预算受限的大量的AL
文献用于分类,包括基于不确定性的采样[30],多样性
最大化[42],贝叶斯方法[32]
等
。尽管取得了多年的进
步,但在实践中,最好的人工智能策略往往是问题依赖
的,随机抽样等策略仍然是强有力的基础。
人类
注释
主动学习(
AL
)
自我训练(
ST
)
列车位姿估
计模型
数据
增强
剩余14页未读,继续阅读
2024-06-09 上传
2021-09-28 上传
2023-08-27 上传
2023-05-10 上传
2023-04-29 上传
2023-05-17 上传
2023-05-14 上传
2023-05-10 上传
2023-08-24 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
