HBase入门:C#操作与架构解析
版权申诉
100 浏览量
更新于2024-08-06
收藏 703KB DOC 举报
"本文档介绍了如何使用C#操作HBase,涵盖了HBase的基本概念、架构、存储机制以及安装步骤。"
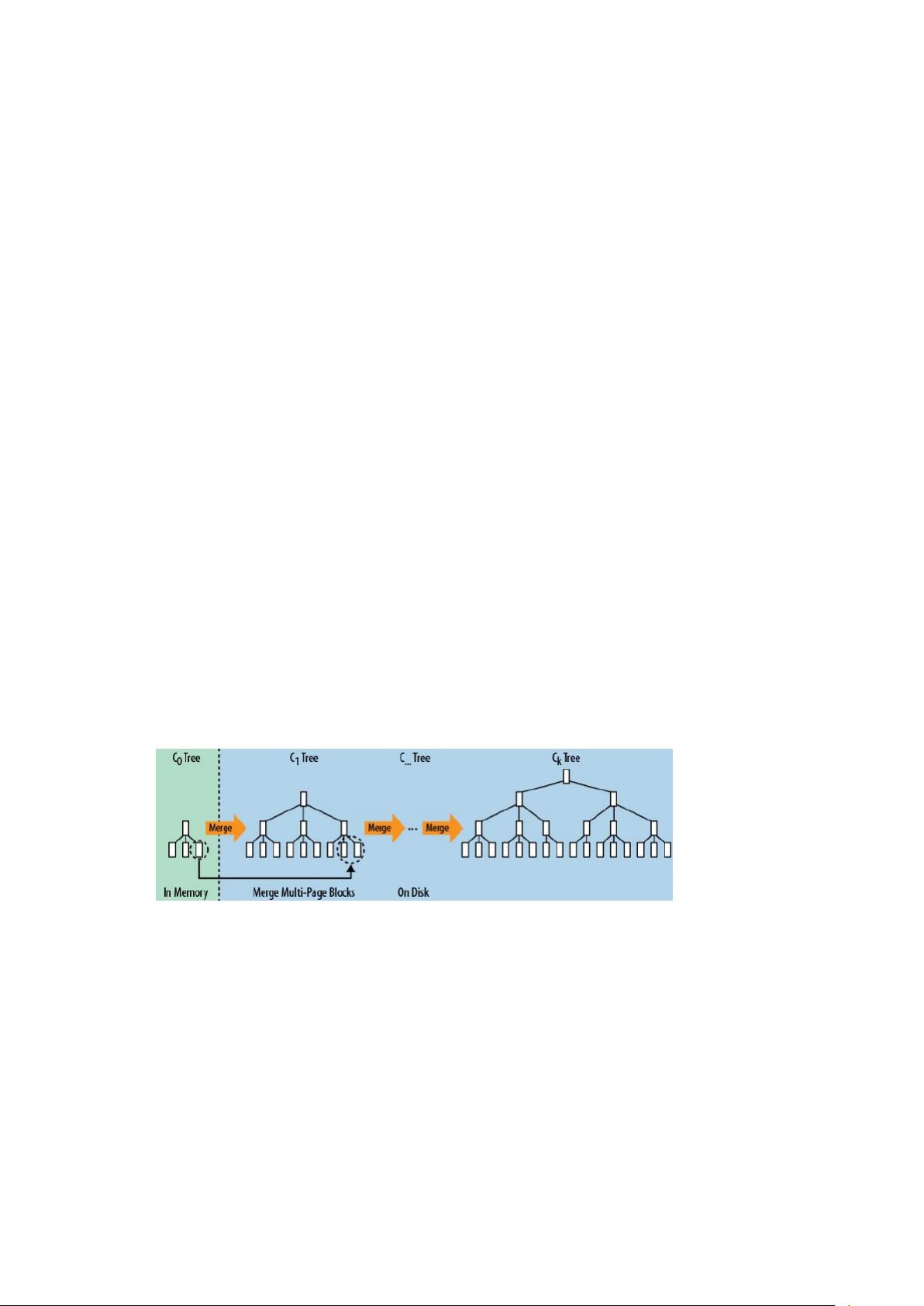
在大数据处理领域,HBase是一个重要的NoSQL数据库,它基于列式存储,适用于处理大规模数据。列式存储使得HBase在查询效率上有显著优势,尤其是在处理部分列和聚合操作时。HBase利用了LSM Tree(Log-Structured Merge Tree)数据结构来平衡读写性能。写入时,数据首先被写入WAL(Write-Ahead Log)确保数据安全,然后存入内存中的跳表结构。当内存达到一定大小后,数据会被flush到磁盘形成小树,随着时间推移,这些小树会定期合并,优化读取性能。
HBase的架构由三个核心组件组成:RegionServer、HBase Master和Zookeeper。RegionServer是实际处理客户端读写请求的节点,它们直接与客户端交互。HBase Master负责管理RegionServer,并处理表结构的变更。Zookeeper则维持整个集群的状态,包括RegionServer的注册和发现,以及MetaTable的位置信息。
在HBase中,读写操作遵循特定步骤。首先,客户端通过Zookeeper找到MetaTable所在的RegionServer,MetaTable存储了所有region的信息。然后,客户端确定处理特定rowKey的RegionServer,最后直接与该RegionServer进行数据交互。
RegionServer内部包含几个关键组件:WAL用于记录写操作,保证故障恢复;BlockCache作为读缓存,加速常用数据的访问;MemStore是写缓存,当其内容达到阈值时,会被flush到磁盘上的HFile中,HFile是以有序key-value形式存储数据的文件,存在于HDFS(Hadoop Distributed File System)上。
HBase的存储模型是基于行和列族的。每个表由多行组成,每行包含多个列族,每个列族又包含多个列,每个列包含了键值对。这种结构允许灵活的数据模型设计,同时也支持高效的数据检索。
至于安装HBase,文档提到了下载HBase 2.4.11版本的链接,但具体的安装步骤没有在提供的内容中详细描述。通常,安装过程会涉及配置环境变量、初始化集群、启动服务等步骤,这些都需要按照官方文档或相关教程进行操作。
总结来说,HBase是适合处理大规模数据的列式存储数据库,它通过LSM Tree实现高效的读写平衡,采用分布式架构,支持灵活的数据模型。在C#中操作HBase,需要理解其基本原理和工作流程,以便正确地进行数据交互。
Hadoop(四)C#操作 Hbase
Hbase
Hbase 是一种 NoSql 模式的数据库,采用了列式存储。而采用了列存储天然具备以下优势:
可只查涉及的列,且列可作为索引,相对高效
针对某一列的聚合及其方便
同一列的数据类型一致,方便压缩
同时由于列式存储将不同列分开存储,也造成了读取多列效率不高的问题
LSM Tree
说到 HBase,我们不得不说其采用的 LSM Tree。我们都知道关系数据库中常用的
B+Tree,叶子节点有序,但写入时可能存在大量随机写入,因此形成了其读快写慢的特点。
而 HBase 采用了 LSM Tree,在读写之间寻找了平衡,损失了部分读取的性能,实现了快
速的写入。LSM 具体实现如下:
写入 WAL 日志中(防止数据丢失),同时数据写入内存中,内存中构建一个有顺序的树,
HBase 采用跳表结构。
随着内存中数据逐渐增大,内存中 flush 到磁盘,形成一个个小树。
磁盘中的小树存在数据冗余,且查询时遍历多个小树效率低,LSM 定期合并,实现数据
合并,而合并的时候,会对数据重新排序,优化读取性能。
HBase 架构
HBase 中三个核心的 Server 形成其分布式存储架构。
RegionServer:负责客户端读写请求,客户端直接与其通信
HBaseMaser:负责维护 RegionServer;表结构的维护
Zookeeper:维护集群状态
下载后可阅读完整内容,剩余6页未读,立即下载
2020-06-11 上传
2021-12-04 上传
2023-07-14 上传
2023-07-24 上传
2023-07-15 上传
2022-08-08 上传
2023-05-29 上传
2023-06-01 上传
2023-07-12 上传
2023-06-11 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- The C++ Standard Library
- STM32经典详细例子
- 初级程序员PHP面试题
- Keil C51指南
- 网上书店的设计论文asp
- 学习C#和.net技巧
- 诺基亚symbian 手册汇编.doc
- Windows平台简易多媒体播放器设计
- Professional Android Application Development
- VMwareWorkstation6基本使用.
- abap语言开发之报表的事件
- 并网型风力发电机组的调节控制
- GNU ARM bootloader 分析
- 大学c语言程序设计经典例题
- Wrox.Professional.JavaScript.For.Web.Developers.2nd.Edition.Jan.2009
- ARM step by step
