基于K-means算法的鸢尾花数据分类系统设计与实现
需积分: 10 21 浏览量
更新于2024-08-04
收藏 179KB DOC 举报
基于K-means模式识别系统的设计与实现版本1代码大全
本文档主要介绍基于K-means模式识别系统的设计与实现版本1代码大全,系统利用K-means聚类算法对鸢尾花数据集进行分类。下面是相关知识点的总结:
1. K-means聚类算法:
K-means聚类算法是一种常用的无监督机器学习算法,用于将数据分为K个簇。该算法的主要思想是通过迭代计算聚类中心和样本之间的距离,直到聚类中心不再发生改变。
2. 鸢尾花数据集:
鸢尾花数据集是一个常用的机器学习数据集,包含150条样本数据,每个样本数据有四个属性:花萼长度、花萼宽度、花瓣长度、花瓣宽度。本文中,我们使用花萼长度和花萼宽度两个属性作为分类标准。
3. Python语言:
Python是一种常用的高级编程语言,广泛应用于机器学习、深度学习、数据分析等领域。本文中,我们使用Python 3.8及以上版本,开发环境为PyCharm 2020。
4. K-means算法的实现:
K-means算法的实现可以分为四步:(1)随机选择k个点作为初始的聚类中心;(2)对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇;(3)对每个簇,计算所有点的均值作为新的聚类中心;(4)重复2、3直到聚类中心不再发生改变。
5. 数据预处理:
数据预处理是机器学习的重要步骤,包括数据清洗、特征工程、数据归一化等。在本文中,我们直接使用鸢尾花数据集,无需进行数据预处理。
6. 聚类中心:
聚类中心是K-means算法的核心概念,代表了每个簇的中心点。聚类中心的计算可以使用均值或中位数等方法。
7.距离计算:
距离计算是K-means算法的重要步骤,用于计算样本之间的距离。常用的距离计算方法包括欧几里德距离、曼哈顿距离、余弦距离等。
8. Matplotlib库:
Matplotlib是一个常用的Python数据可视化库,用于绘制图表、曲线等。本文中,我们使用Matplotlib库绘制分类过程图。
9. Sklearn库:
Sklearn是一个常用的Python机器学习库,提供了多种机器学习算法和工具。本文中,我们使用Sklearn库加载鸢尾花数据集。
10. 机器学习流程:
机器学习流程通常包括数据预处理、特征工程、模型训练、模型评估、模型部署等步骤。本文中,我们主要介绍K-means聚类算法的设计与实现。
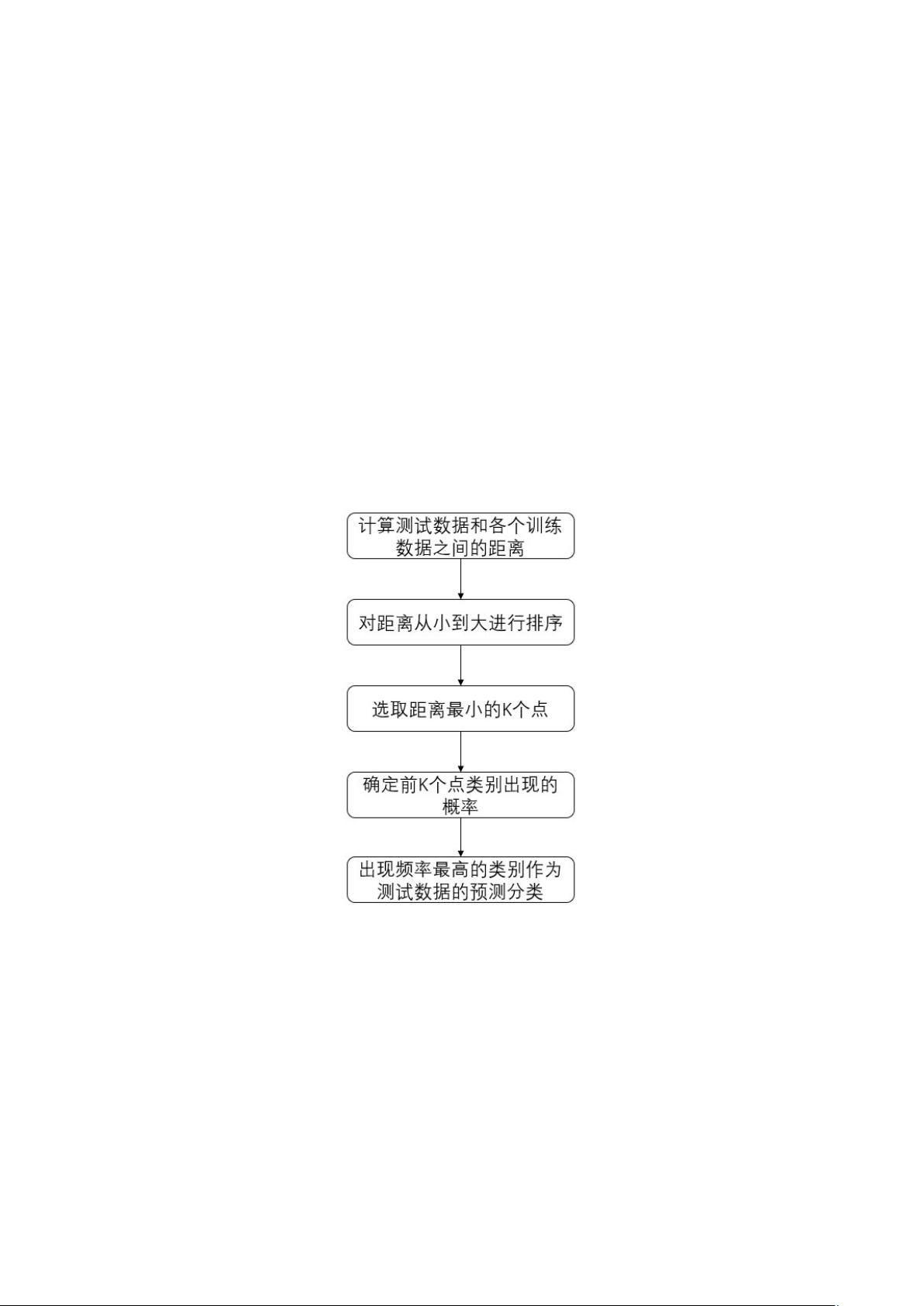
题目 基于 K-means 模式识别系统的设计与实现
1.1 题目的主要研究内容
(1)工作的主要描述
该系统利用 K-means 聚类算法对鸢尾花数据集进行分类。为了方便分类,
使用了数据集中的四类属性中的两类作为分类标准,根据数据集的类别,将 K
设置为 3。开始时先使用 python 自带的 random 随机产生 3 个聚类中心,然后根
据 K-means 算法的流程依次进行迭代,直至分类完成。
(2)系统流程图
图 1 算法流程图
1.2 题目研究的工作基础或实验条件
(1)硬件环境
处理器:AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz
(2)软件环境
开发语言:python 3.8 及以上
下载后可阅读完整内容,剩余6页未读,立即下载
2022-10-19 上传
2022-10-19 上传
2024-06-30 上传
2012-04-12 上传
2021-02-19 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

李逍遥敲代码
- 粉丝: 2995
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- Popup_Window:这是一个简单的项目,用于展示如何在弹出窗口中打开 url
- 社交移动性:CPAL用于社交移动性网站的数据工作空间
- 面试-Java一些常见面试题+题解之网络-Network.zip
- PracticalTest02
- miniature-forms
- windows 11主题壁纸(内含多个主题对应壁纸).7z
- MySixPercent-crx插件
- anitab-forms-web:开源程序(OSP),用于处理较小的4周或全天计划以为开源项目做出贡献的应用程序。 与GSoC,Outreachy或RGSoC相似。 这是网络应用
- pythonProgrammingSMTPClient
- ampersand-infinite-scroll:一个简单的&符号模块,可用于需要无限滚动元素的任何视图
- carto-react-template:用于React的CARTO。 在CARTO平台和React上开发位置智能(LI)应用的最佳方法
- 面试-Java一些常见面试题+题解之JVM-JVM.zip
- aem-cookbook:适用于Adobe AEM的厨师食谱
- 易语言-易语言多线程练习
- Python库 | gurobipy-9.1.0-cp38-cp38-macosx_10_11_x86_64.whl
- speech-to-text-azure:在github中创建回购协议
