深入理解Hadoop:大数据技术探索
需积分: 10 67 浏览量
更新于2024-07-09
收藏 4.7MB PDF 举报
"该资源是一份关于Hadoop的大数据培训课件,涵盖了Hadoop的基本概念、HDFS原理、MapReduce、Hadoop2.0特性、Sqoop、Hive、Hbase,以及Spark入门和Hadoop集群管理等内容。课程旨在使学员深入理解大数据的‘4V’特征,熟悉Hadoop的起源和发展,以及其在大数据处理中的核心优势。"
在大数据领域,Hadoop是一个至关重要的开源框架,主要用于处理和存储海量数据。Hadoop的出现源于Google的三篇开创性论文——GFS(Google文件系统)、MapReduce和BigTable。其中,Doug Cutting是Hadoop的主要开发者,他在Nutch项目中实现了MapReduce,从而催生了Hadoop的诞生。
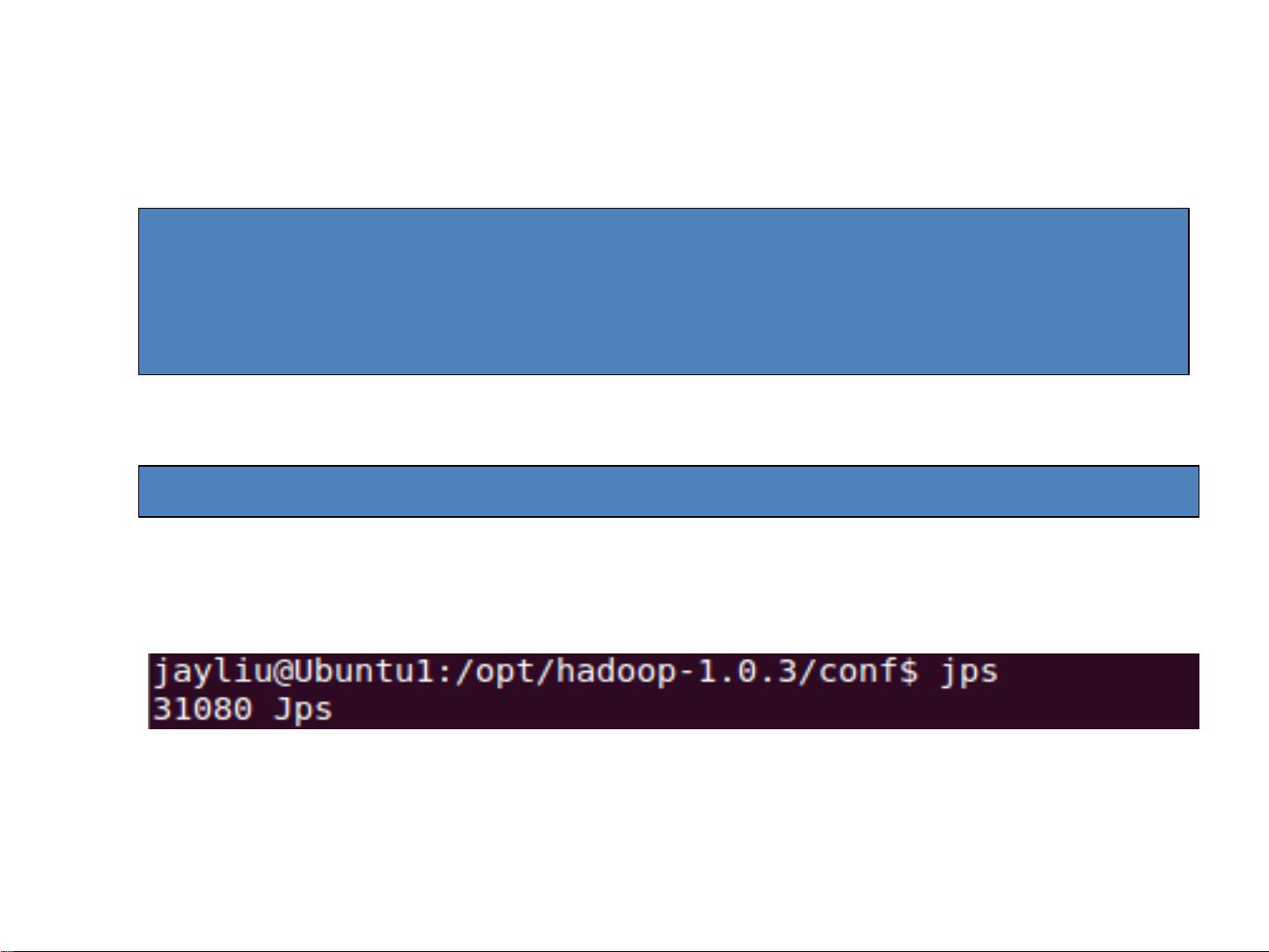
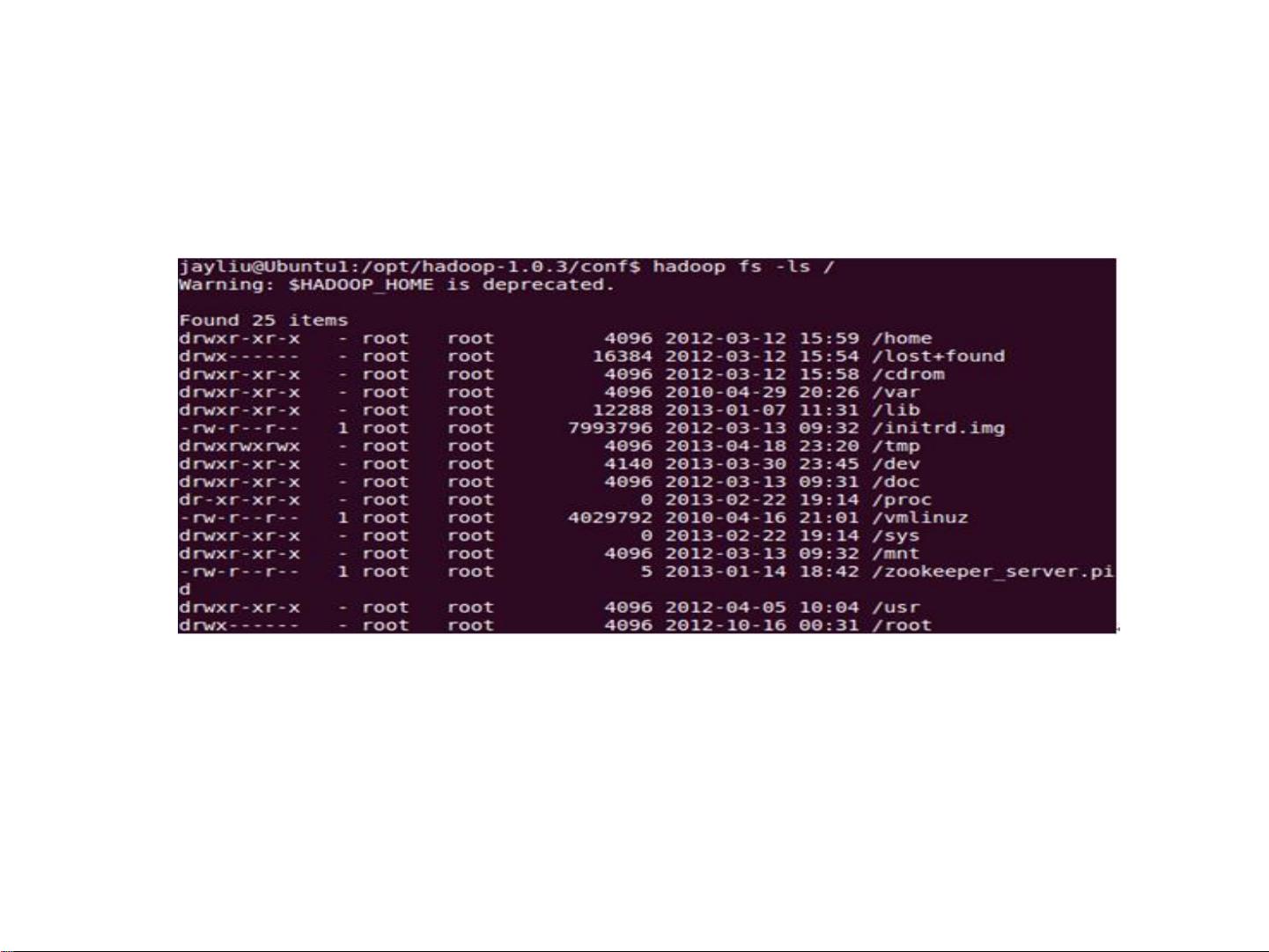
Hadoop的核心组件包括HDFS(Hadoop分布式文件系统)和MapReduce。HDFS提供了一个高容错性的分布式文件系统,能将大量数据分布在多台廉价服务器上,确保数据的可靠性和高可用性。MapReduce则是一种用于大规模数据集处理的编程模型,它将复杂的计算任务分解为映射(map)和化简(reduce)两个阶段,使得并行计算成为可能。
Hadoop的扩展性极强,可以轻松扩展到数千个节点,同时保持高效的性能。数据可以在节点间动态移动,以维持集群的负载均衡。此外,Hadoop具有很好的容错机制,能自动处理节点故障并恢复任务,确保系统的稳定性。
课程还涉及了其他关键组件,如Sqoop,这是一个用于在Hadoop和关系型数据库管理系统之间导入导出数据的工具,极大地简化了大数据环境下的数据迁移工作。Hive是一个基于Hadoop的数据仓库工具,支持SQL-like查询,便于数据分析。Hbase是Hadoop生态系统中的一个NoSQL数据库,适合存储非结构化和半结构化数据,提供了实时的数据访问。
此外,课程还包括Spark的介绍,Spark是另一种大数据处理框架,以其内存计算和流处理能力而闻名,相比Hadoop MapReduce,Spark在某些场景下能提供更高的计算效率。
这份培训课件全面介绍了Hadoop及其在大数据处理中的作用,以及如何通过Hadoop生态系统进行数据管理和分析。通过学习,学员不仅能够理解大数据的基本概念,还能掌握实际操作Hadoop集群和相关工具的技能。



2022-06-22 上传
2020-02-14 上传
2022-07-07 上传
2023-05-25 上传
2023-06-10 上传
2023-06-05 上传
2023-07-25 上传
2023-06-13 上传
2024-05-26 上传

阿晨聊技术
- 粉丝: 74
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
