"京东侯磊实践:链路化压测到流量回放的平台应用"
版权申诉
"03京东-侯磊-从链路化压测到流量回放的平台实践.pdf" 这篇文章探讨了在京东公司侯磊所负责的平台实践中,从链路化压测到流量回放的整个过程。文中指出,压测和流量回放是软件开发中非常重要的一环,对于系统的稳定性和性能具有至关重要的影响。而随着业务的不断增长和变化,传统的压测和流量回放方式已经无法满足需求,因此需要建立一种新的平台实践来应对这一挑战。
文章首先介绍了链路化压测的概念和意义,指出了传统压测的局限性,并提出了链路化压测的优势和特点。侯磊在文章中提到,链路化压测能够更加真实地模拟用户的请求链路,能够更加全面地评估系统的性能和稳定性。而为了实现链路化压测,侯磊提出了一套完整的技术架构和方案,包括对系统进行动态调度和资源分配,以及通过自动化工具进行压测脚本的录制和执行等。
接着,文章进一步介绍了流量回放的概念和重要性。流量回放是指将真实的用户请求流量录制下来,并在压测环境中进行回放,从而评估系统的性能和稳定性。侯磊指出,传统的流量回放方式存在着许多问题,包括流量录制的成本较高、回放效率较低等。因此,他提出了一种新的流量回放方案,通过对流量进行压缩和重放算法的优化,从而大幅降低了流量回放的成本和提高了回放效率。
在文章的后半部分,侯磊详细介绍了他们在京东公司所建立的链路化压测和流量回放平台。这个平台采用了一系列先进的技术手段,包括容器化部署、自动化运维、分布式存储等,极大地提升了压测和回放的效率和稳定性。侯磊还介绍了他们采用的一些创新技术,比如基于机器学习的压测调度算法、自适应调节的资源分配策略等,这些技术使得整个平台更加智能化和自适应化。
最后,文章总结了侯磊团队建立的链路化压测和流量回放平台的成功经验,并展望了未来的发展方向。侯磊认为,随着技术的不断发展和创新,链路化压测和流量回放平台将会变得更加智能化和自动化,能够更好地应对复杂多变的业务环境。同时,他还鼓励更多的企业和团队加入到这一领域,共同推动压测和流量回放技术的进步和发展。
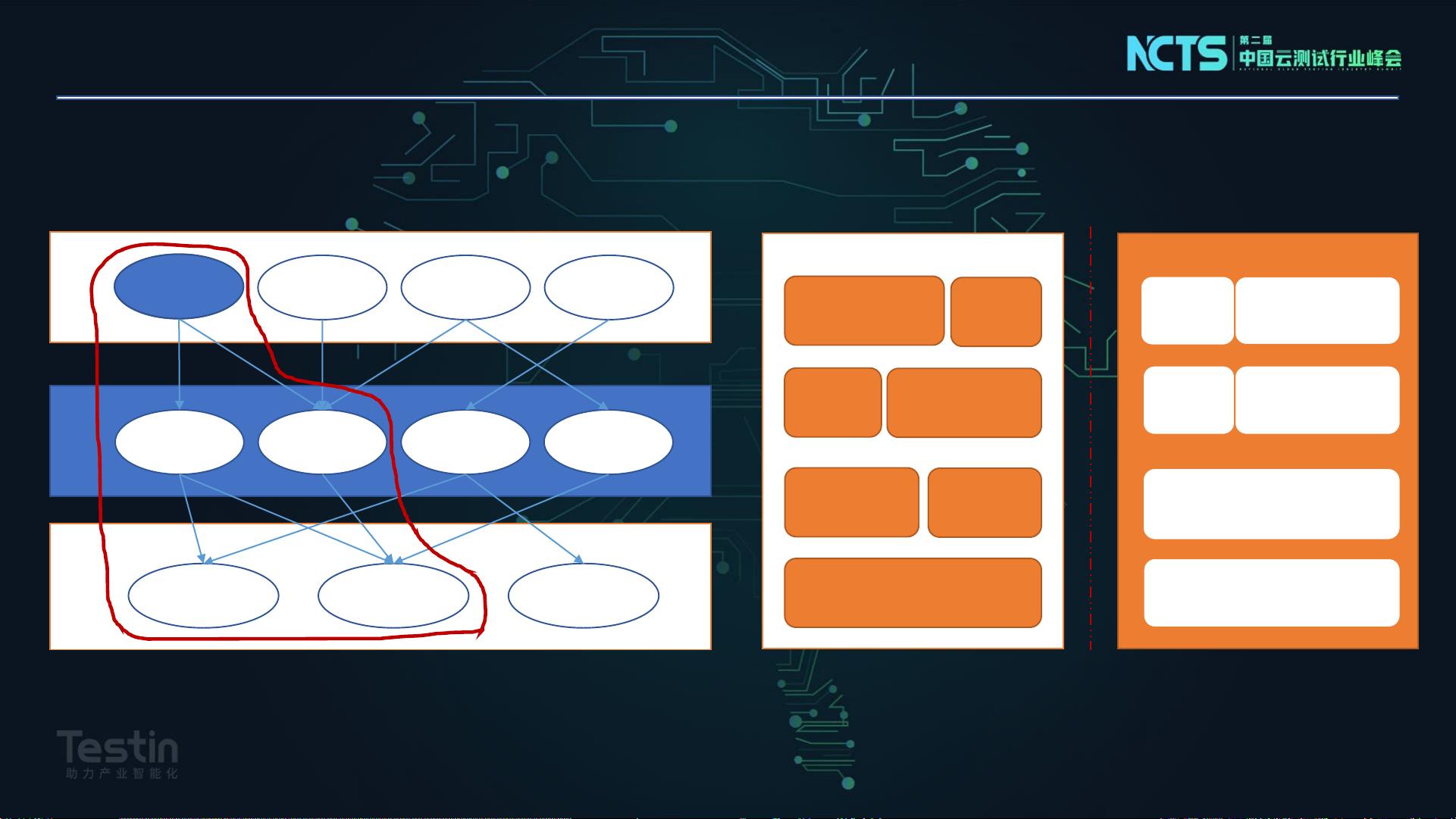
链路压测的原因和意义
应用A
应用B
应用D
应用F
应
用
C
应用E
应
用
A
应用B
应用C
应用D
应用E
应用F
应用B
应用D
应用F
应用C
应用E
应用A
应用A
应用B
应用C
应用F
应用D
应用F
应用E
服
务
层
服
务
层
应
用
层
存
储
APP1
APP2 APP3 APPn
Service1 Service2 ServiceNService3
Cache DB1 DB2
APP1
剩余20页未读,继续阅读
2019-08-16 上传
2021-11-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-19 上传

普通网友
- 粉丝: 48
- 资源: 8282
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
