Switch Transformers: scaling to trillion parameter models
需积分: 12 47 浏览量
更新于2024-07-14
收藏 996KB PPTX 举报
"此资源是一个关于Switch Transformers的PPT分享,主要探讨了Transformer模型在处理万亿参数级别模型时的效率和稀疏性优化策略。"
在深度学习领域,Transformer模型自2017年提出以来,已经成为自然语言处理(NLP)任务的核心组件。Transformer以其自注意力机制和并行计算能力,革新了序列模型的设计,如ELMO(2018)和BERT(2018)。这些模型通过预训练和微调的方法,在各种任务上取得了显著的性能提升。例如,BERT基于Transformer编码器,而GPT系列(包括GPT-2和GPT-3)则采用了Transformer解码器,其中GPT-3的参数量达到了惊人的175亿。
然而,随着模型规模的不断扩大,训练和部署的挑战也随之增加。为了应对这一问题,研究者们提出了Switch Transformer。这是一种旨在提高大规模模型效率的新架构,其核心是“Switch Routing”技术。在Switch Transformer中,每个输入样本不是通过所有专家(即子模型)进行处理,而是根据可学习的权重分配到最具专业知识的专家进行计算,从而实现更高效的资源利用。
具体来说,Switch Routing通过一个学习到的权重矩阵W对输入x进行变换,然后将变换后的向量分配给概率最高的专家。这个过程可以理解为一种动态路由策略,它允许模型根据输入的特性选择性地激活部分专家,降低了计算复杂度。
此外,该PPT可能还涵盖了以下几个方面:
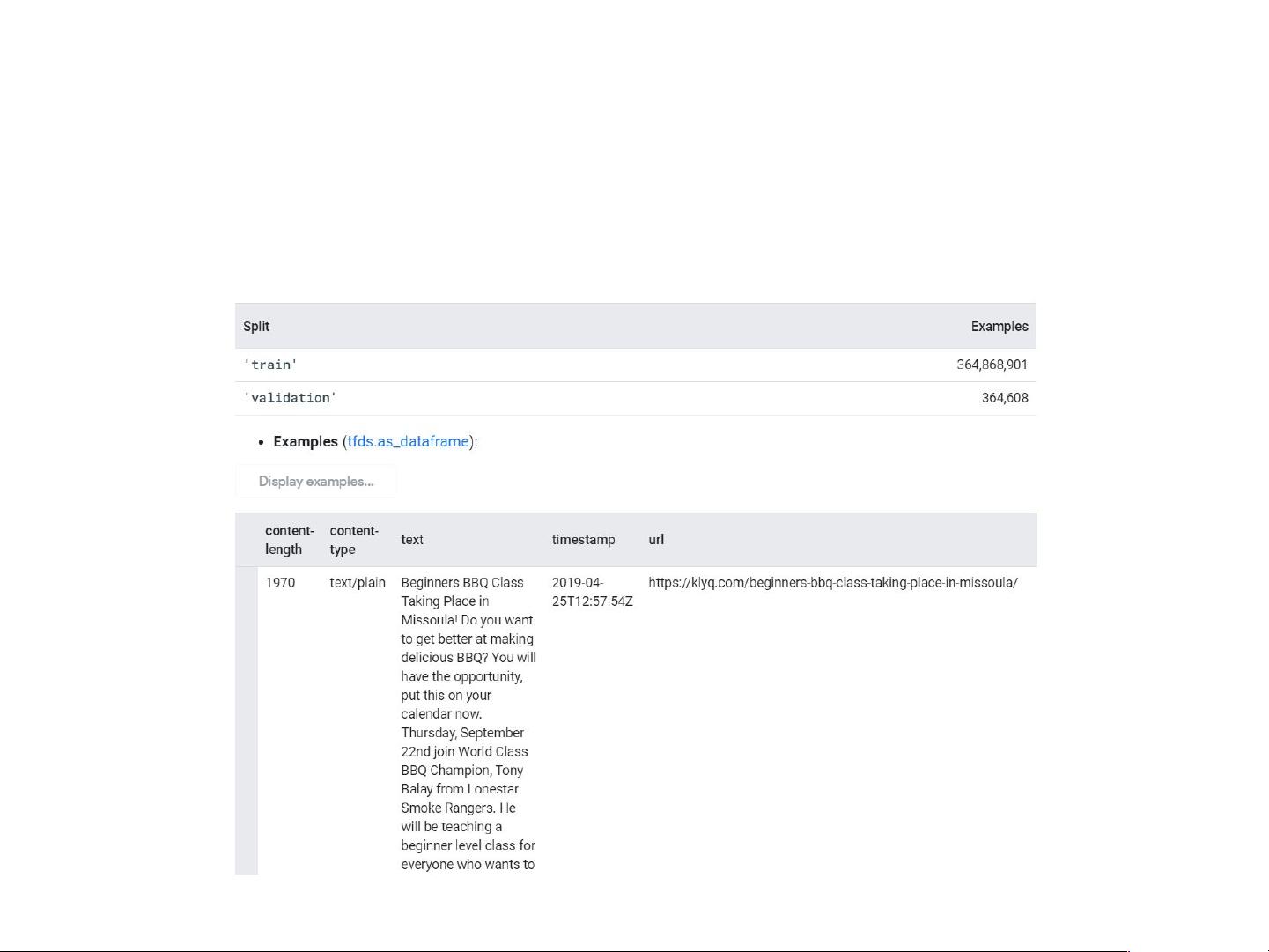
1. 数据集:C4(Common Crawl's Web Crawl Corpus),这是一个大型的互联网文本数据集,用于训练和评估模型。
2. 基线研究结果:可能比较了Switch Transformer与传统Transformer或其它大模型在C4数据集上的表现。
3. 微调研究结果:展示了在特定NLP任务上,Switch Transformer经过微调后的性能提升。
4. 模型蒸馏:如何将微调后的大型模型压缩成更小、更高效的版本,以适应实际应用。
5. 代码结构和实现:可能提供了实现Switch Transformer的代码框架和关键部分,供研究者参考。
Switch Transformer的研究旨在推动大模型的训练和应用进入新的阶段,通过引入稀疏性和效率优化,使得处理万亿级别的参数模型成为可能,这对于AI的未来发展趋势具有重要意义。
Research Background
• Dataset: C4(Common Crawl's Web Crawl Corpus)
剩余16页未读,继续阅读
2019-03-19 上传
2021-04-22 上传
2023-06-15 上传
2023-07-20 上传
2023-05-27 上传
2021-10-13 上传

烟杨绿未成
- 粉丝: 50
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
