京东实时数据仓库开发实践与Deltalake解析
版权申诉
101 浏览量
更新于2024-08-12
收藏 1.08MB PDF 举报
"9-2+京东实时数据仓库开发实践.pdf"
本文主要探讨了京东在实时数据仓库开发中的实践,包括传统数据仓库面临的挑战、京东的实时数据湖解决方案以及Deltalake的核心原理,并对不同开源项目进行了比较。
1. 传统数据仓库的挑战
- ACID语义性无法保证:在传统的Lambda架构中,数据处理通常不支持数据库事务的原子性、一致性、隔离性和持久性,导致数据的一致性难以维护。
- 离线入库的不可靠性:离线批量处理可能因各种原因(如系统故障)导致数据丢失或不完整。
- 细粒度的数据更新功能缺失:传统数据仓库往往不支持或效率低下地处理数据的更新和删除操作。
- 数据流转路径复杂:数据从源头到最终分析的路径复杂,增加了管理和维护的难度。
2. 京东实时数据湖的探索与经验
- 自研方案:京东针对上述挑战,开发了自己的实时数据湖解决方案,融合了社区的优秀经验,如Delta、Hudi和Iceberg等开源项目。
- 社区项目对比:
- Delta:由Databricks开发,提供ACID特性、时间旅行和多版本并发控制(MVCC),支持Spark、Presto和Hive等多种计算引擎。
- Hudi:由Uber开源,同样具备ACID特性,支持时间旅行和Schema演化,但更新/删除功能有限,适用于批处理和流处理。
- Iceberg:由Netflix推出,具有ACID特性,支持Schema演化,但目前在流式sink支持上还在进行中,适用于Spark和Presto。
3. Deltalake核心原理
- Delta数据表:由数据文件和事务日志两部分组成,确保数据的完整性和一致性。
- 事务日志记录:每个提交事务包含时间戳、执行者和具体变更信息,以及涉及的文件路径和统计信息。
- 表的Metadata信息:存储字段名、字段类型、文件格式和配置属性等,便于元数据管理。
4. 批流一体开发流程
- Deltalake允许批处理和流处理无缝结合,通过DeltaStreamer或Spark Streamingsource/sink实现,简化了数据处理的复杂性。
5. 优缺点与总结
- 优点:实时数据湖方案提高了数据处理的时效性和一致性,降低了数据流转的复杂性,增强了数据更新和管理能力。
- 缺点:可能需要更高的硬件资源投入,且不同开源项目之间的兼容性和功能差异需谨慎选择和适配。
京东的实时数据仓库实践展示了如何应对大数据时代的挑战,通过引入和优化开源技术,实现了高效、一致的数据处理,为企业决策提供了强有力的支持。
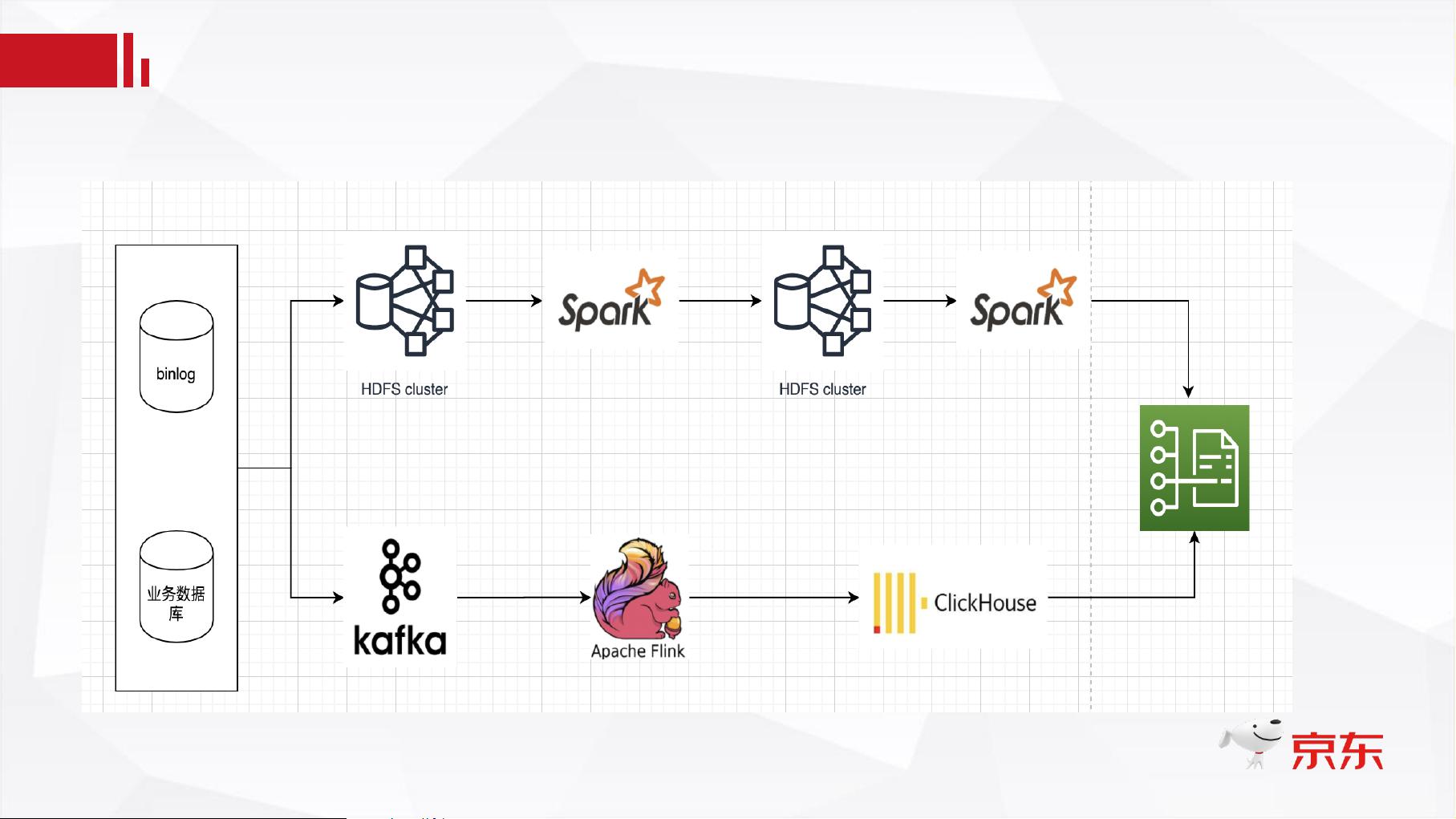
传统数据仓库面临的挑战
Lambda 架构:
剩余12页未读,继续阅读
2701 浏览量
265 浏览量
2023-08-27 上传
221 浏览量
2022-11-20 上传
108 浏览量
149 浏览量
172 浏览量
2019-09-24 上传

普通网友
- 粉丝: 13w+
- 资源: 9193
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新经济及创新商业模式企业改制
- newage-slowmonitor-viewer:慢速监控器
- Bayes:贝叶斯定理:离散情况。-matlab开发
- 基于 zircon 并提供 Linux 兼容操作系统内核
- 上海省乡镇级区划图 shp格式
- 1c-server-repo:1C配置存储服务器
- Code-Quiz:测验您的JS知识的测验
- scatplot:用颜色表示数据密度的散点图。-matlab开发
- 詹戈
- 商业模式与品牌快速成长之道
- 基于socket通讯的文件续传!
- 编译好的OSG-3.4.0库文件
- Collatz:检查 Collatz 序列的工具。-matlab开发
- RadioStationHub
- flask-survey
- 用于全志 SOC 的微型 FEL 工具
