低占用率下实现GPU高性能计算
需积分: 10 137 浏览量
更新于2024-07-23
收藏 732KB PDF 举报
"这篇资料主要探讨了在GPU通用计算中,如何通过增加指令级并行而非仅仅依赖线程级并行来提高性能,同时指出在某些情况下,降低GPU的占用率(occupancy)反而可以实现更高的计算效率。作者Vasily Volkov在2010年的演讲中展示了CUFFT和CUBLAS的实例,证明了降低占用率能够显著提升性能。"
在GPU计算领域,通常建议增加每个多处理器上的线程数量和每个线程块中的线程数量,以隐藏延迟并充分利用硬件资源,这种方法被称为提高“occupancy”或线程占用率。然而,Vasily Volkov的研究表明,增加指令级并行,即在同一时钟周期内执行更多的指令,可能是一种更有效的方法。他通过对比CUFFT(CUDA Fast Fourier Transform)2.2和2.3版本以及CUBLAS(CUDA Basic Linear Algebra Subprograms)1.1和2.0版本的性能,发现使用更小的线程块,降低了occupancy,却能显著提升性能。
CUFFT的例子中,当线程块大小从256减少到64,occupancy下降了一半,但性能却从45Gflop/s提高到93Gflop/s,几乎翻倍。类似地,在CUBLAS的SGEMM(Single-Precision General Matrix Multiply)操作中,线程块从512减少到64,occupancy同样减半,但性能提升了1.6倍,达到204Gflop/s。
这些结果挑战了两个常见的误解:一是认为多线程是隐藏GPU延迟的唯一途径,二是认为共享内存的访问速度可以与寄存器相媲美。Volkov的演讲提示我们,通过优化指令级并行,即使在较低的occupancy下,也能有效地掩盖延迟,从而提升计算速度。
接下来,Volkov的演讲将深入到矩阵乘法的案例研究中,进一步探讨如何通过减少线程数量来优化性能。这表明,对于GPU编程,单纯追求高occupancy并非总是最佳策略,理解并利用指令级并行可以实现更低延迟和更高效率的计算。
这篇资料揭示了一个重要的观点:在GPU计算中,优化不仅仅局限于提高线程占用率,有时减少线程数量、增加指令级并行,可以更有效地利用GPU资源,实现更高的计算性能。对于GPU程序员和高性能计算领域的专业人士来说,这是一个值得深入研究和实践的策略。
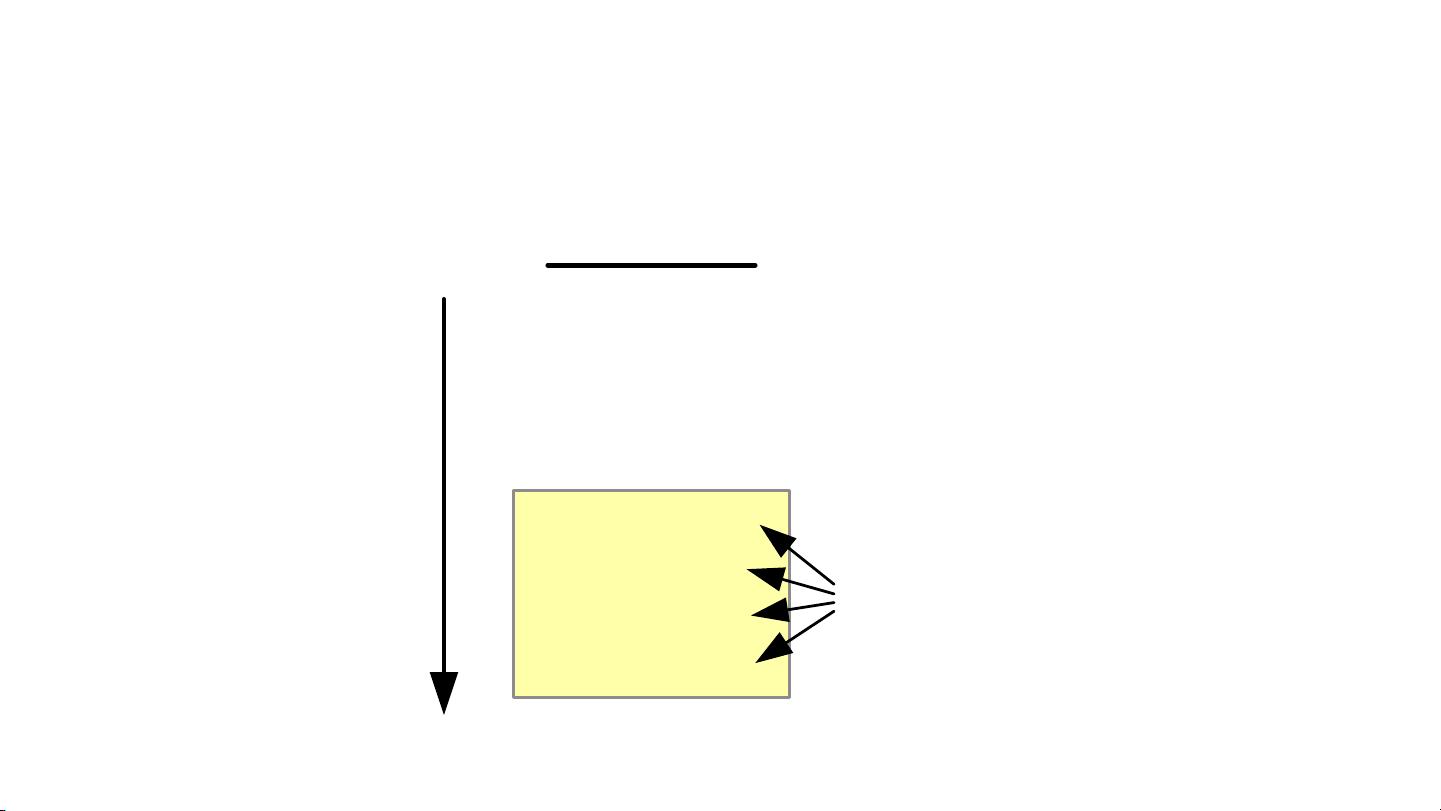
Instruction-level parallelism (ILP)
13
But you can also use parallelism among instructions in a
single thread:
x = x + a
y = y + a
w = w + a
z = z + a
x = x + b
y = y + b
w = w + b
z = z + b
instructions
thread
4 independent
operations


剩余74页未读,继续阅读
2024-04-25 上传
120 浏览量
2021-11-24 上传
2019-07-29 上传
2023-03-11 上传
2010-06-22 上传
2009-03-11 上传
2007-11-20 上传
2023-08-22 上传

奋斗在哈佛
- 粉丝: 3
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
