Python数据清洗:缺失值与异常值处理实战
版权申诉
'123456', db='python') # 链接本地数据库
sql = 'select * from taob' # sql语句
data = pd.read_sql(sql, conn) # 获取数据
在数据清洗过程中,缺失值处理是非常关键的步骤,因为它直接影响到数据分析的准确性和可靠性。在上述内容中,我们注意到数据集中存在价格(price)为0的情况,这可能是由于数据输入错误或者某些商品未标价导致的。在这种情况下,通常会选择用合适的统计量来填充这些缺失值。在这个例子中,作者选择将价格为0的数据替换为中位数,这是因为中位数对于异常值(如异常高价或低价)不敏感,能提供一个较为稳健的代表值。这里的中位数是36,所以可以执行以下操作:
```python
data['price'] = data['price'].fillna(data['price'].median())
```
这样,所有价格为0的记录都将被替换为36。
4。异常值处理
异常值是指那些显著偏离其他观察值的数值,它们可能由数据输入错误、测量误差或其他原因造成。在描述性统计中,异常值可能导致均值和标准差等统计指标的扭曲。对于评论数(comment)来说,平均值562和最大值454037可能暗示存在异常值。为了处理异常值,可以使用一些统计方法,比如Z-score或IQR(四分位距)。
Z-score方法基于数据点与均值的距离,如果某个值的Z-score超过一定的阈值(例如3或-3),则认为它是异常值。IQR方法则通过计算数据的上四分位数(Q3)减去下四分位数(Q1)的1.5倍来确定异常值范围。任何低于Q1-1.5*IQR或高于Q3+1.5*IQR的值都可能被视为异常。
例如,使用IQR方法:
```python
Q1 = data['comment'].quantile(0.25)
Q3 = data['comment'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = (data['comment'] < lower_bound) | (data['comment'] > upper_bound)
data = data[~outliers]
```
这段代码首先计算了评论数的Q1和Q3,然后确定了异常值的边界。最后,它筛选出那些不在异常值范围内的记录。
5。数据预处理总结
数据清洗是数据分析的前期准备,包括处理缺失值和异常值,目的是提高数据质量和模型的预测能力。在Python中,我们可以利用pandas库的强大功能进行数据处理。对于缺失值,可以根据情况选择用均值、中位数、众数或者其他合理的值进行填充;对于异常值,可以使用统计方法如Z-score或IQR来识别并处理。在实际应用中,还应结合业务背景和数据分布特性来确定最合适的处理策略。
Python提供了丰富的工具和方法来进行数据清洗,使得我们能够更好地理解和利用数据,从而推动更有效的数据分析和决策。
python实现数据清洗实现数据清洗(缺失值与异常值处理缺失值与异常值处理)
今天小编就为大家分享一篇python实现数据清洗(缺失值与异常值处理),具有很好的参考价值,希望对大家有所帮助。一
起跟随小编过来看看吧
1。。 将本地将本地sql文件写入文件写入mysql数据库数据库
本文写入的是python数据库的taob表
source [本地文件]
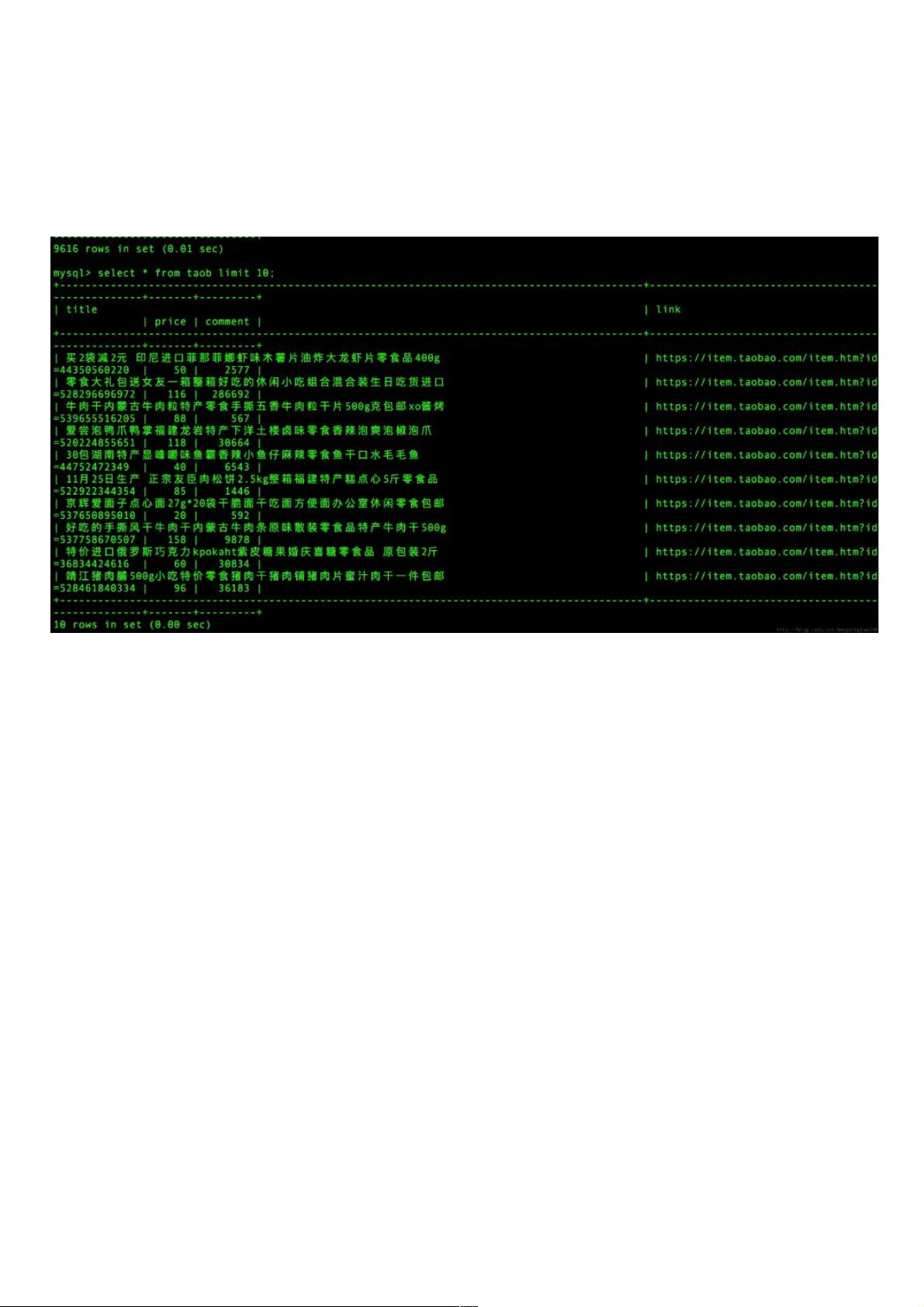
其中总数据为9616行,列分别为title,link,price,comment
2。使用。使用python链接并读取数据链接并读取数据
查看数据概括
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select * from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
print(data.describe())
说明数据的导入是正确的,简单的分析发现问题并不是这么简单,因为comment均值562可能偏大,最大评论数454037也可能出现错
误,price价格为0也不太可能出现。
price comment
count 9616.00000 9616.000000
mean 64.49324 562.239601
std 176.10901 6078.909643
min 0.00000 0.000000
25% 20.00000 16.000000
50% 36.00000 58.000000
75% 66.00000 205.000000
max 7940.00000 454037.000000
3。缺失值处理。缺失值处理
将价格为0的值设置为中位数36
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
下载后可阅读完整内容,剩余3页未读,立即下载
2020-09-21 上传
2020-09-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38750007
- 粉丝: 4
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android应用源码仿支付宝九宫格解锁-IT计算机-毕业设计.zip
- BostonUnderwater:洪水检测网络 - 使用 GoogleMaps 和 Amcharts 集成记录远程洪水
- Elixir_in_action:我对《 Elixir in Action》一书中程序的实现
- 萝拉:萝拉图片网站
- Meta:Python元编程
- 基于Pytorch, 使用强化学习(自博弈+MCTS)训练一个五子棋AI.zip
- AxaTests
- WISE_ML:明智的机器学习模块
- 移动实习——基于移动终端用户画像的大规模数据过滤与性能优化研究 7.17-8.25.zip
- k8s研究
- website:个人网站
- JavaScript-Calculator
- asteroidstest
- 行业文档-设计装置-一种利用牛奶盒制作宣纸配方.zip
- flutter_practice
- nkn-monitoring:PHP(Laravel)上的一个简单的NKN节点监视GUI工具
