Hadoop入门指南:大数据与分布式计算详解
需积分: 10 77 浏览量
更新于2024-07-15
收藏 413KB DOCX 举报
本文档是关于Hadoop学习的笔记,主要针对大数据领域的初学者设计。随着互联网技术的发展,数据量呈爆炸式增长,传统的数据处理技术已无法满足需求,催生了大数据处理软件工具,如Hadoop、Spark、Storm等。Hadoop尤其关键,它由三个核心组件组成:分布式文件系统HDFS、分布式运算编程框架MapReduce以及分布式资源调度平台YARN。
首先,大数据是指海量的数据集,这些数据来源于日常生活、工作等多个领域,对数据的处理和分析有着强烈的需求。例如,电商通过推荐系统利用用户行为数据进行个性化商品推荐,而精准广告推送则依赖于用户画像技术,根据用户属性进行定向广告投放。
Hadoop的核心组件具体阐述如下:
1. **分布式文件系统HDFS**:HDFS作为Hadoop的基础,它模仿单机文件系统的设计,但实现了数据的分布式存储。文件被切分为多个块,分散存储在多台Datanode服务器上,提供创建、删除等操作。文件块的信息和位置由NameNode节点管理,确保数据冗余以增强安全性,可以通过指定副本数量来控制。
2. **分布式运算编程框架MapReduce**:MapReduce是一种编程模型,用于在多台机器上并行处理大量数据。它将复杂的问题拆分成一系列简单的Map和Reduce任务,非常适合处理大规模数据的批处理任务。
3. **分布式资源调度平台YARN**:YARN(Yet Another Resource Negotiator)负责管理和调度Hadoop集群的资源,包括内存、CPU等,使得MapReduce任务能够高效地运行。
总结起来,Hadoop通过其特有的分布式存储和计算能力,解决了传统技术难以处理大数据的问题,成为大数据处理不可或缺的工具。无论是电商的推荐系统还是广告推送,Hadoop都在背后发挥着关键作用。对于想要进入大数据领域或进一步提升技能的学习者来说,这篇笔记提供了很好的入门指南,适合新手从理解大数据的基本概念开始,逐步掌握Hadoop的核心组件及其工作机制。
学大数据,上小牛学堂 答疑 :
主机名:2对应的 地址:34
主机名:2对应的 地址:34
主机名:2-对应的 地址:34-
三、从 55 中用  软件进行远程连接
在 55 中将各台 ). 机器的主机名配置到的 55 的本地域名映射文件中:
*7,55,8,9,*,
34 2
34 2
34 2
34- 2-
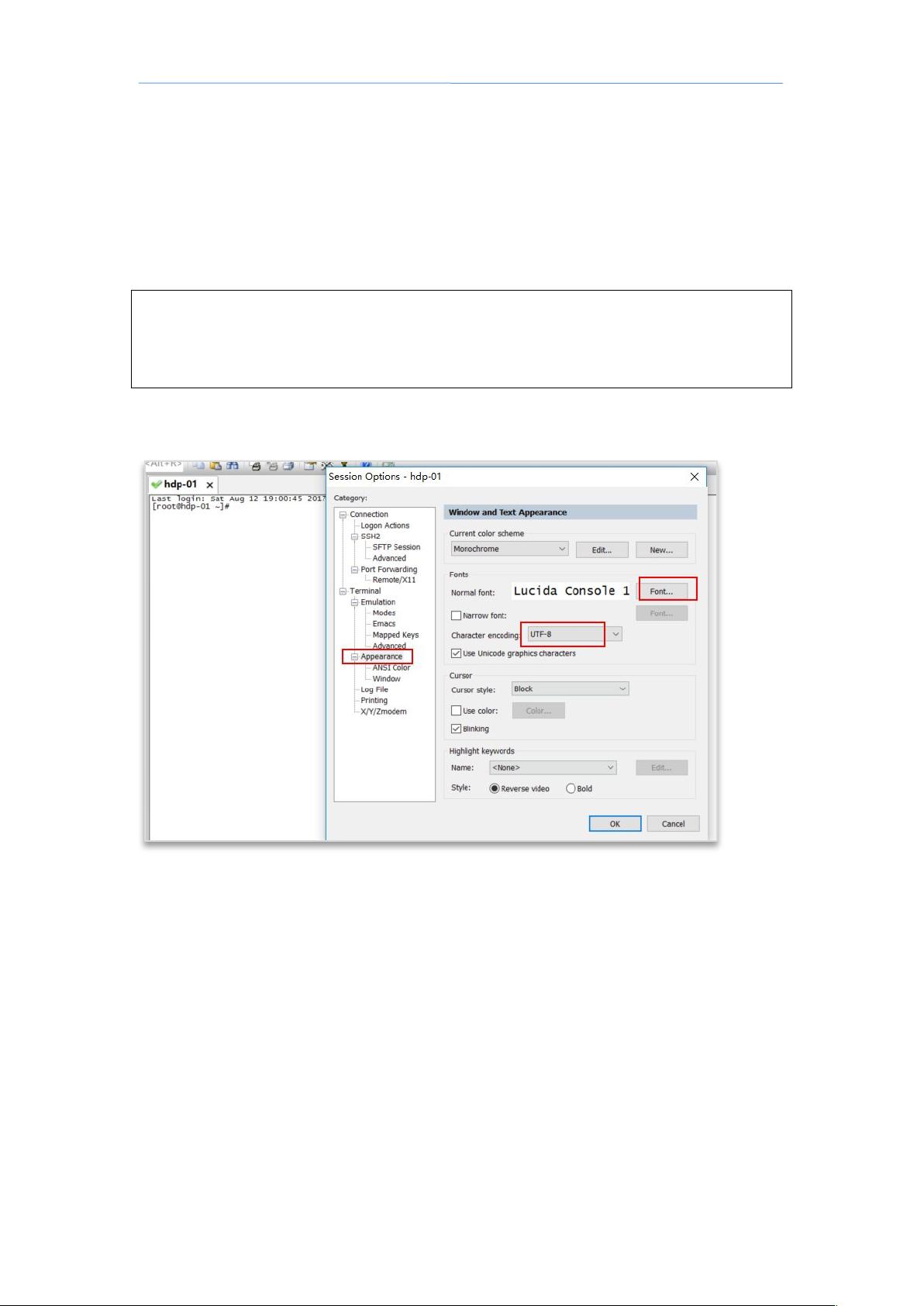
用 * 连接上后,修改一下 * 的显示配置(字号,编码集改为 %624):
四、配置 linux 服务器的基础软件环境
防火墙
关闭防火墙:9*:
关闭防火墙自启: **;<:=
安装 >:( 体系中的各软件都是 >9 开发的)
? 利用 1打开 @ 窗口,然后将 > 压缩包拖入 @ 窗口
? 然后在 ). 中将 > 压缩包解压到,,下
? 配置环境变量:A!B!CD $"!6
9,*,;在文件的最后,加入:
剩余17页未读,继续阅读
2013-11-07 上传
2020-01-31 上传
2022-11-03 上传
2020-03-24 上传
2012-11-25 上传
2016-11-03 上传
2021-10-04 上传

skyleebc
- 粉丝: 4
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
