李宏毅机器学习笔记:Adaptive Learning Rate算法详解与应用
需积分: 0 125 浏览量
更新于2024-08-03
收藏 651KB PDF 举报
本篇文章是关于李宏毅的机器学习学习笔记,主要聚焦于Adaptive Learning Rate在深度神经网络训练中的应用。Adaptive Learning Rate是一种策略,旨在解决固定学习率在训练过程中可能遇到的问题,如过早停止在非全局最优点,尤其是在接近训练过程后期,当损失不再下降但梯度仍在震荡时。常见的适应性学习率算法包括:
1. Adagrad: 它根据每个参数的历史梯度平方自适应地调整学习率,有助于防止过拟合,尤其在稀疏数据集上表现良好。
2. RMSProp: 基于Adagrad的改进版,它引入了一个衰减因子来平滑历史梯度的平方,从而提供更稳定的训练过程。
3. Adam: 是一种结合了动量(momentum)和RMSProp的优化器,通过指数移动平均估计梯度的一阶矩估计和二阶矩估计,能有效处理大规模数据集和高维度参数空间。
4. Learning Rate Decay: 随着训练迭代增加,逐渐降低学习率,有助于模型收敛,避免过拟合。
5. WarmUp: 在训练初期采用较大的学习率,然后逐步减小,有助于模型更快地进入学习区域。
文章引用了以下参考资料来支持这些概念的讲解:
- MIT-DeepLearning: 提供了深度学习理论基础的详细讲解,对于理解优化算法背后的原理很有帮助。
- Adam论文:阐述了Adam优化器的详细算法和优势。
- Residual Network (ResNet) 和 Transformer 文献:展示了这些深度学习架构如何通过优化学习率策略受益。
- RAdam (Rectified Adam):一种改进的Adam变体,通过修正Adam中的偏差问题,进一步提升训练性能。
通过这些内容,学习者可以了解到如何灵活运用适应性学习率策略来提升深度学习模型的训练效果,以及在实际操作中如何选择和调整这些算法以适应不同场景。理解这些策略的重要性在于,它们可以帮助我们优化模型训练过程,避免陷入局部最优,提高模型最终的泛化能力。
本节课主要介绍了 Adaptive Learning Rate 的基本思想和方法。通过使用 Adaptive Learning
Rate 的策略,在训练深度神经网络时程序能实现在不同参数、不同 iteration 中,学习率不同。
本节课涉及到的算法或策略有:Adgrad、RMSProp、Adam、Learning Rate Decay、Warm Up。
本节课参考的资料有:
MIT-Deep Learning:https://www.deeplearningbook.org/
Adam:https://arxiv.org/pdf/1412.6980.pdf
Residual Network:https://arxiv.org/abs/1512.03385
Transformer:https://arxiv.org/abs/1706.03762
RAdam:https://arxiv.org/abs/1908.03265
一、背景:固定learning rate的弊端
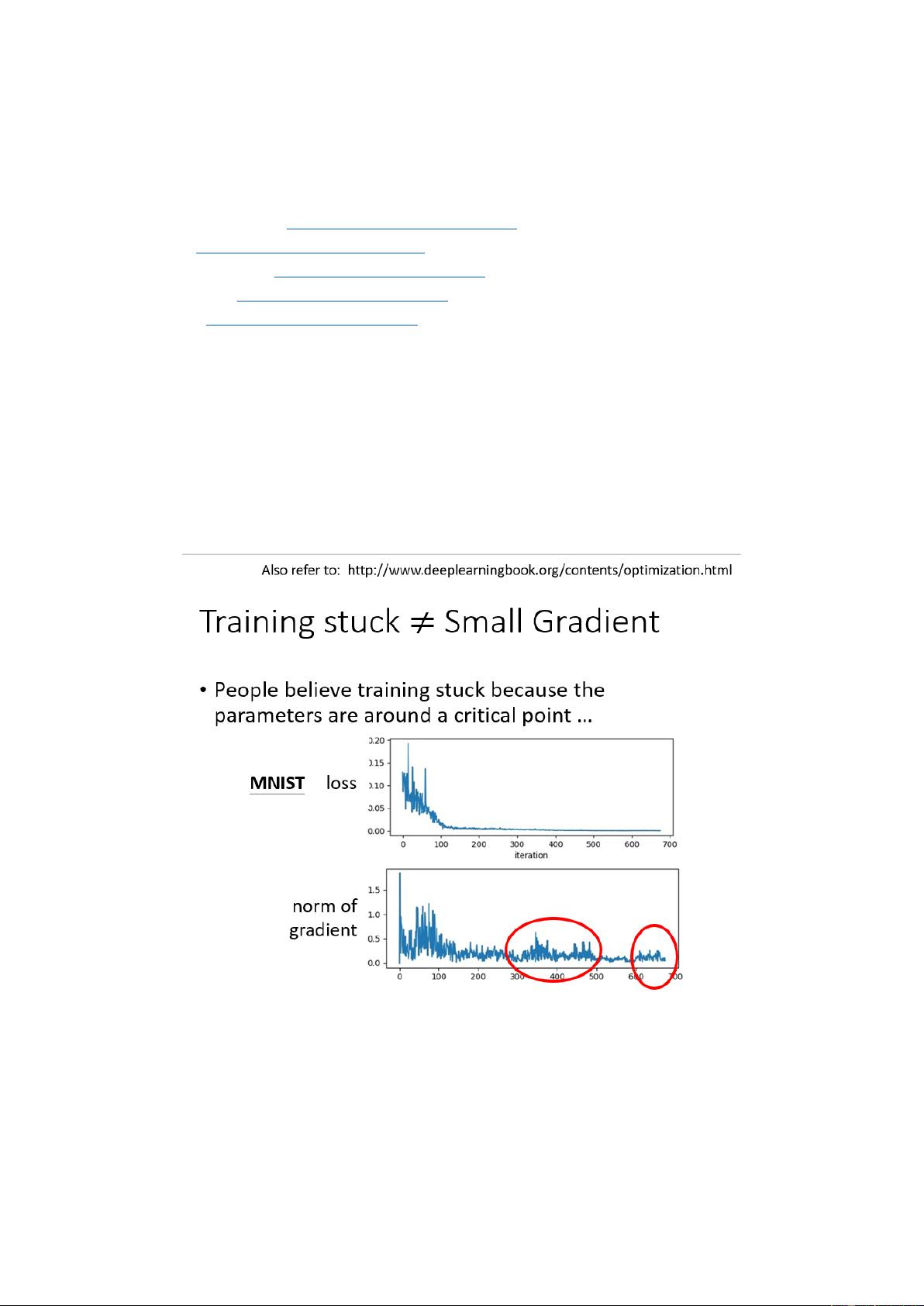
在对神经网络进行训练时,critical point 不一定是训练过程中最大的阻碍点,多数时候,
training 还没有走到 critical point 的时候训练过程就已经停止了。图 1 上半部分反映的是 loss
值随着 iteration 的变化情况,下半部分反映的是 norm of gradient(gradient 向量的长度)随
着 iteration 的变化。可知,随着 iteration 增大,loss 不再下降,但是 gradient 的长度却并没
有减小。此时 gradient 可能在 error surface 山谷的谷壁间不断来回震荡,只是 loss 不再下降,
但并非卡在 critical point。
图 1
图 2 展现的是 training convex optimization 的情景。图中右上部分的叉号标记的为我们的最
优点,其 error surface 是一个椭圆形状(图中只呈现了 error surface 的部分),在横轴方向
gradient 的梯度变化较小,坡度较缓;在纵轴方向 gradient 变化较大,坡度较陡。图中左下
角展示的是当学习率为 10
-2
时,参数 update 的路径,可知 gradient 是处于震荡状态;当将学
习率调整到 10
-7
时,gradient 终于不再震荡,但 update 到图中心的直角处时,始终都走不到
下载后可阅读完整内容,剩余5页未读,立即下载
131 浏览量
218 浏览量
2022-09-12 上传
2021-02-03 上传
2023-09-22 上传
104 浏览量

MilkLeong
- 粉丝: 185
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
