Python爬虫入门:从零开始学习爬虫技术
下载需积分: 13 | DOCX格式 | 2.95MB |
更新于2024-07-01
| 93 浏览量 | 举报
"这篇资源是关于Python爬虫学习的笔记,涵盖了从基础知识到实践操作的逐步讲解,旨在帮助初学者入门并培养自学能力。"
在Python爬虫学习中,首先我们要理解什么是爬虫。爬虫是一种自动抓取互联网信息的程序,通过模拟人类浏览网页的行为,获取并处理大量网络数据。它可以应用于各种场景,如商业分析、生活辅助等,例如通过爬虫获取北京二手房成交均价、深圳Python工程师薪资水平或推荐北京最佳粤菜餐厅等信息。企业也广泛使用爬虫,如搜索引擎百度和谷歌,它们依赖强大的爬虫技术来抓取和索引网页内容。
了解爬虫的基本工作原理对于学习至关重要。这一过程通常包括四个步骤:
1. 获取数据:爬虫程序根据指定的URL向服务器发送HTTP请求,请求包含获取数据的指令。
2. 解析数据:服务器接收到请求后返回HTML或其他格式的响应数据,爬虫需要解析这些数据,通常使用如BeautifulSoup或lxml等库将HTML转换为可读结构。
3. 提取数据:解析后的数据可能包含大量信息,爬虫需要进一步提取目标数据,如文本、图片链接等。
4. 储存数据:最后,爬虫将提取到的有价值信息保存至本地文件或数据库,方便后续分析和使用。
在实践中,我们通常使用requests库来实现网络请求。例如,以下代码展示了如何使用requests.get()方法获取网页内容:
```python
import requests
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md')
```
通过`response.status_code`属性,我们可以检查请求是否成功,状态码200表示请求成功。同时,`response.content`属性提供了返回的二进制数据,适用于下载图片、音频或视频内容:
```python
res = requests.get('https://res.pandateacher.com/2018-12-18-10-43-07.png')
pic = res.content
```
这只是一个基础示例,实际上,Python爬虫还涉及到反爬虫策略、代理IP、验证码识别、多线程爬取、数据清洗等多个复杂环节。随着学习深入,你将掌握如何应对这些挑战,实现更高效、更智能的爬虫程序。
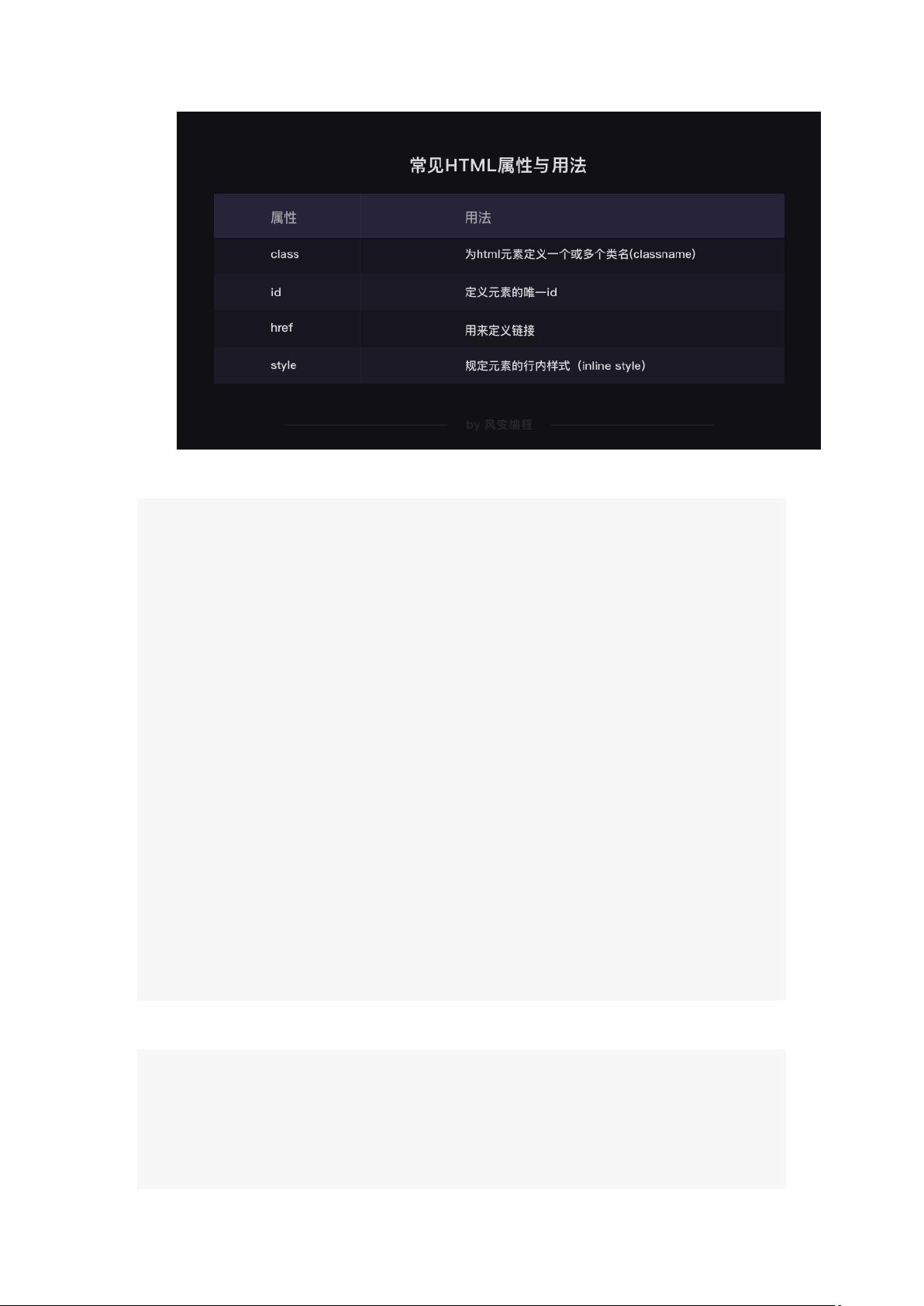
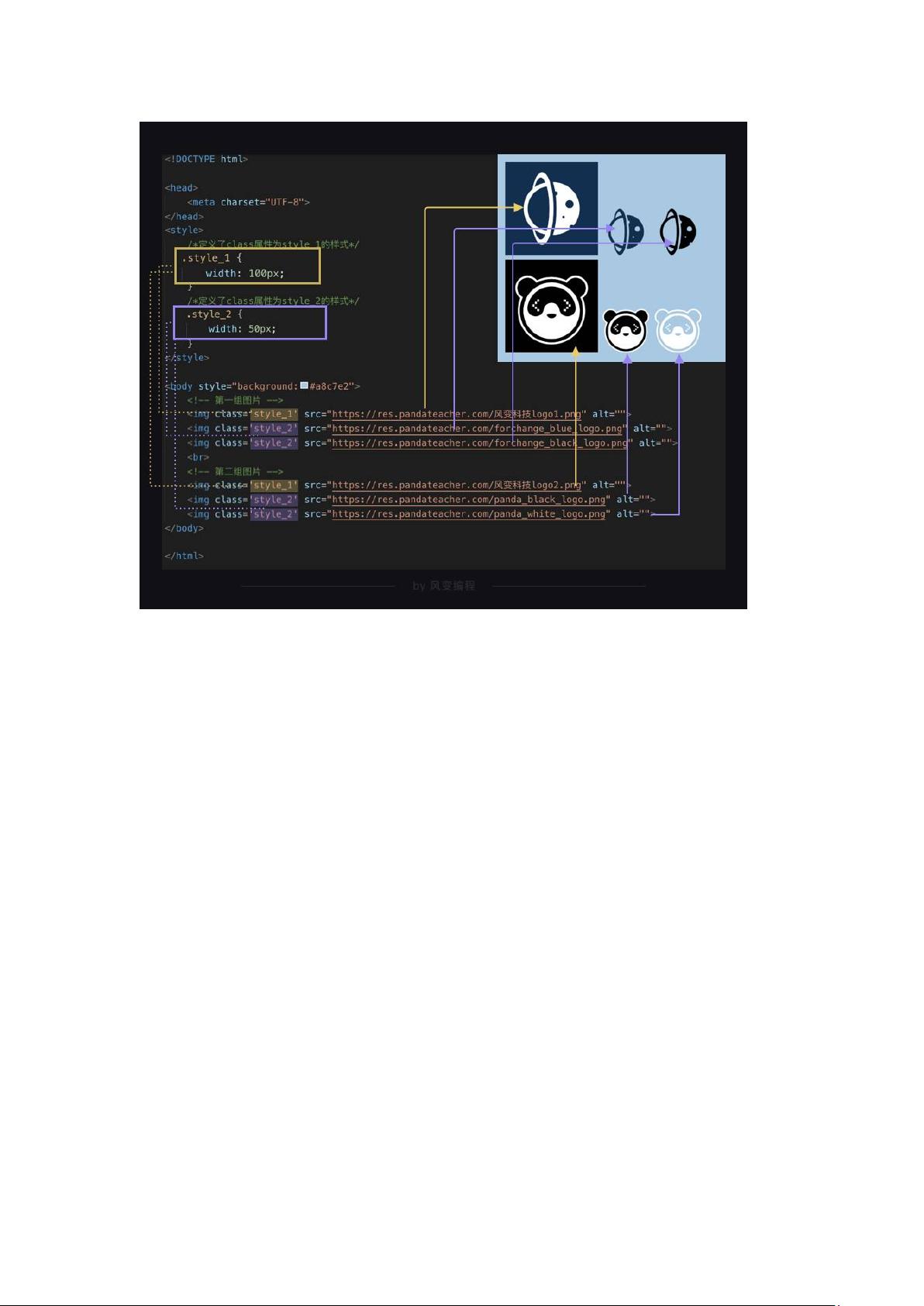
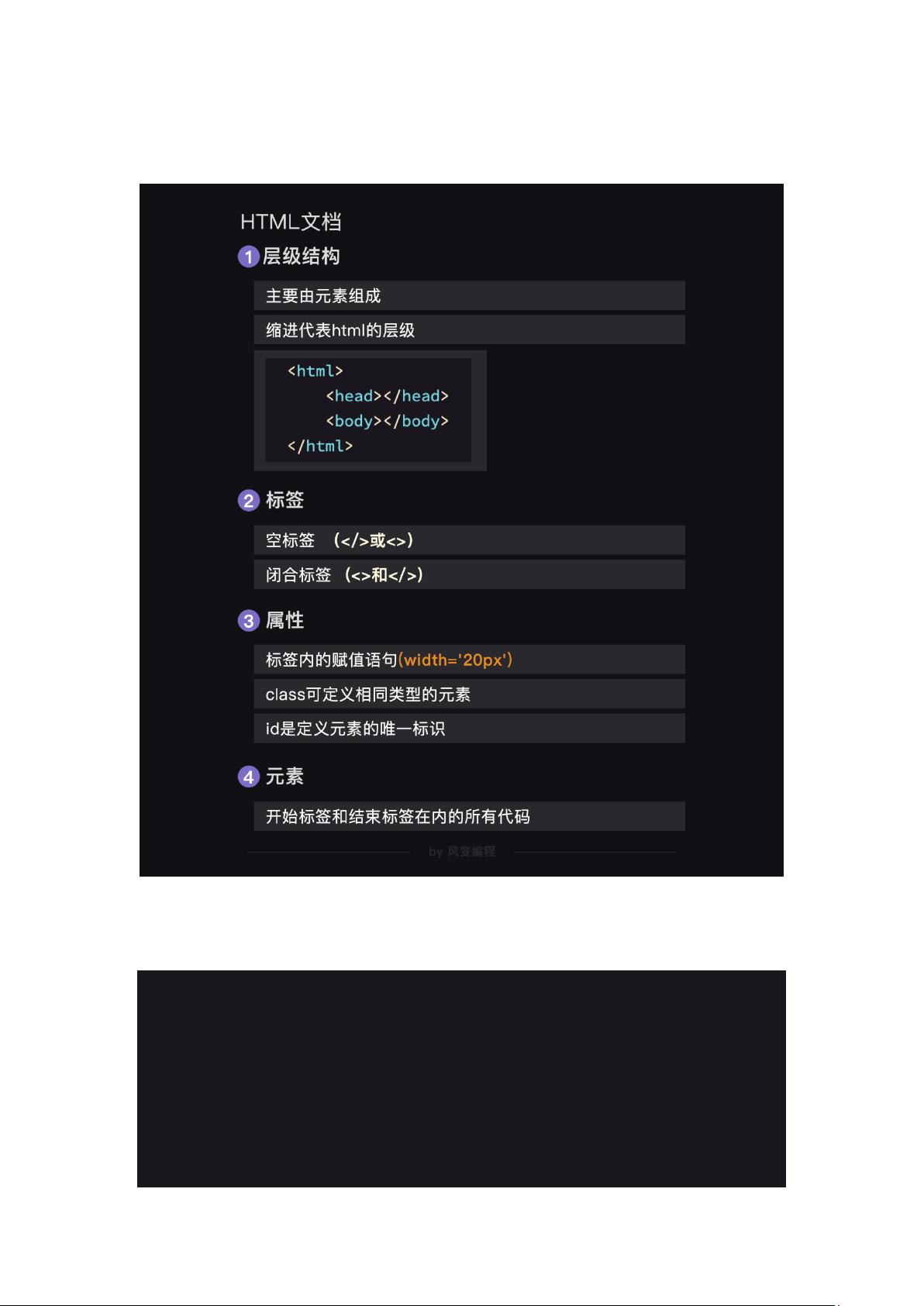
a) style 属性
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<style>
/*规定 h1 的具体样式*/
h1 {
font-weight: bold;/*控制元素字体粗细*/
text-align: center;/*控制元素对齐方式*/
letter-spacing: 2px;/*控制文本字符的间距*/
color: #20b2aa;/*控制元素的颜色*/
}
</style>
</head>
<body>
<h1>这个书苑不太冷</h1>
</body>
</html>
b) <h1>只增添文本内容
<style>
/*规定 h1 的具体样式*/
h1 {
font-weight: bold;/*控制元素字体粗细*/
text-align: center;/*控制元素对齐方式*/

剩余132页未读,继续阅读
相关推荐




hh.scorpio
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 安装Oracle必备:unixODBC-2.2.11-7.1.x86_64.rpm
- Spring Boot与Camel XML聚合快速入门教程
- React开发新工具:可拖动、可调整大小的窗口组件
- vlfeat-0.9.14 图像处理库深度解析
- Selenium自动化测试工具深度解析
- ASP.NET房产中介系统:房源信息发布与查询平台
- SuperScan4.1扫描工具深度解析
- 深入解析dede 3.5 Delphi反编译技术
- 深入理解ARM体系结构及编程技巧
- TcpEngine_0_8_0:网络协议模拟与单元测试工具
- Java EE实践项目:在线商城系统演示
- 打造苹果风格的Android ListView实现与下拉刷新
- 黑色质感个人徒步旅行HTML5项目源代码包
- Nuxt.js集成Vuetify模块教程
- ASP.NET+SQL多媒体教室管理系统设计实现
- 西北工业大学嵌入式系统课程PPT汇总
