
python爬虫实例详解爬虫实例详解
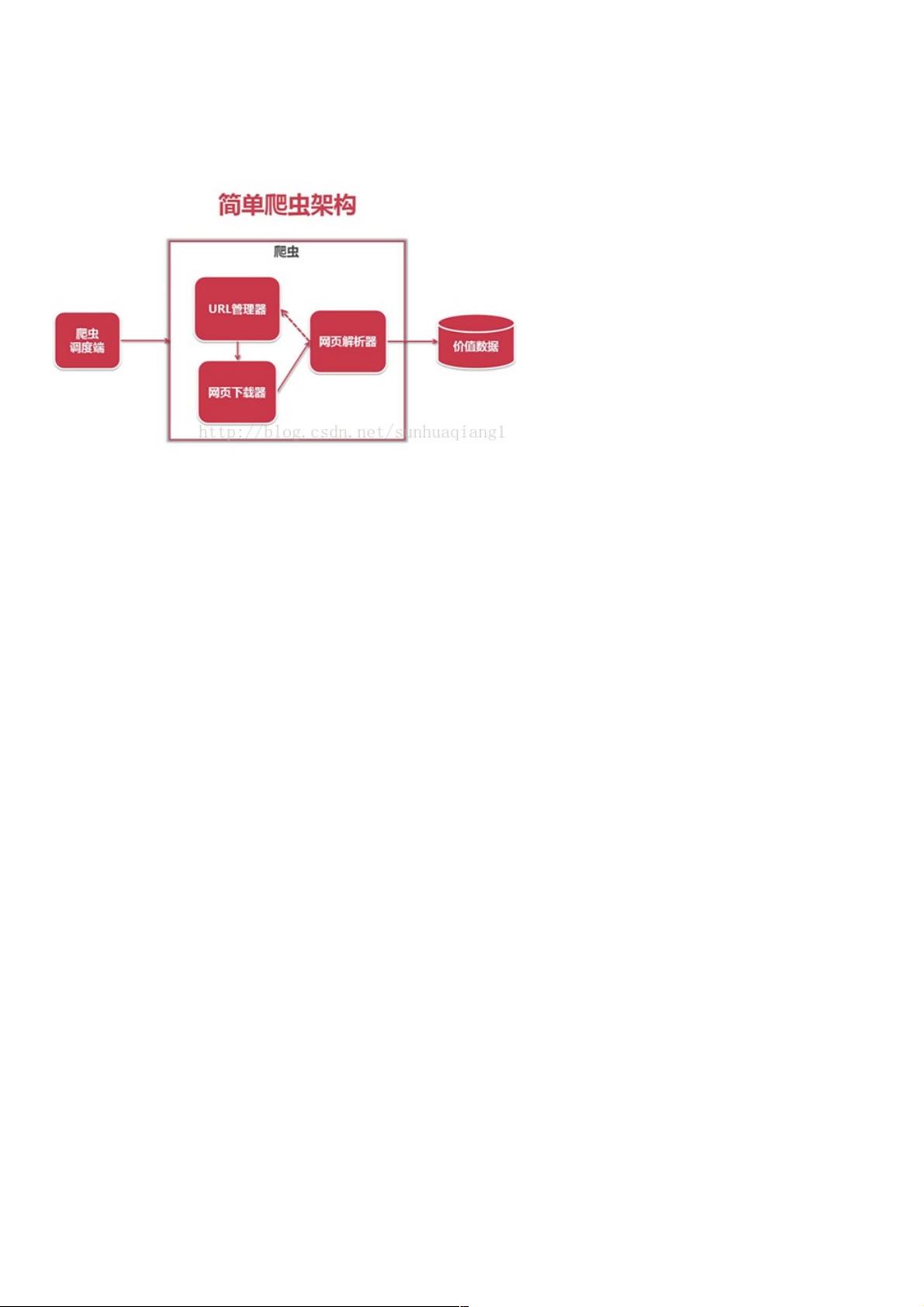
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器、HTML下载器和HTML解析
器。
爬虫简单架构爬虫简单架构
程序入口函数程序入口函数(爬虫调度段爬虫调度段)
#coding:utf8
import time, datetime
from maya_Spider import url_manager, html_downloader, html_parser, html_outputer
class Spider_Main(object):
#初始化操作
def __init__(self):
#设置url管理器
self.urls = url_manager.UrlManager()
#设置HTML下载器
self.downloader = html_downloader.HtmlDownloader()
#设置HTML解析器
self.parser = html_parser.HtmlParser()
#设置HTML输出器
self.outputer = html_outputer.HtmlOutputer()
#爬虫调度程序
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print('craw %d : %s' % (count, new_url))
html_content = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_content)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 10:
break
count = count + 1
except:
print('craw failed')
self.outputer.output_html()
if __name__ == '__main__':
#设置爬虫入口
root_url = 'http://baike.baidu.com/view/21087.htm'
#开始时间
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38612568
- 粉丝: 3
- 资源: 898
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


