Python3爬虫与Splash:动态渲染与JavaScript处理详解
73 浏览量
更新于2024-07-15
收藏 1.03MB PDF 举报
"Python3爬虫中使用Splash进行动态页面渲染的详解"
在Python3的网络爬虫开发中,遇到动态内容的网页是一个常见挑战。Splash提供了一个解决方案,它是一个JavaScript渲染服务,结合了HTTP API与Twisted(Python的异步网络库)和QT(用于图形用户界面的库)。通过Splash,我们可以克服JavaScript阻碍,实现动态页面的抓取,获取完整的网页源代码、截图,甚至控制页面渲染过程。
1. 功能特性
- **异步渲染**:Splash支持同时处理多个网页的渲染任务,提高效率。
- **获取源码与截图**:不仅能够获取渲染后的HTML源代码,还可以获取页面的截图,便于视觉验证。
- **优化渲染**:通过禁用图片渲染或应用Adblock规则来加速页面加载。
- **执行JavaScript**:允许在渲染过程中执行自定义的JavaScript代码。
- **Lua脚本控制**:使用Lua编程语言编写脚本来精确控制页面的渲染步骤。
- **HAR输出**:提供HTTP Archive (HAR) 格式的详细渲染日志,便于分析加载过程。
2. 使用准备
在开始使用Splash前,需要确保已正确安装并启动服务。如果未安装,可以参考相关文档进行安装。
3. 实践操作
要体验Splash的功能,可以通过其内置的Web界面进行测试。运行服务后,访问`http://localhost:8050/`,可以看到一个简单的控制台,可以输入URL并点击渲染按钮。例如,输入`https://www.baidu.com`,点击Renderme按钮,会显示渲染后的截图、源代码和HAR数据。
渲染脚本是用Lua编写的,例如:
```lua
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(0.5))
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end
```
这个脚本首先导航到指定URL,等待一段时间(0.5秒),然后返回渲染后的HTML、PNG截图以及HAR记录。
4. 应用场景
- **复杂动态网站**:对于依赖JavaScript的复杂网站,Splash可以模拟浏览器行为,抓取完整内容。
- **反爬策略**:有些网站会检测非浏览器行为,Splash可以降低被识别为爬虫的风险。
- **数据分析**:通过HAR数据,可以分析网页加载性能,优化爬虫策略。
5. 整合到Python爬虫
要在Python爬虫项目中使用Splash,可以使用`scrapy-splash`库,它提供了Scrapy框架与Splash的集成。通过设置中间件和调度器,可以方便地在请求中加入Splash的渲染过程。
Splash是Python3爬虫处理动态内容的强大工具,它提供了一种有效的方式去解析和抓取JavaScript驱动的网页,使爬虫能够更全面地模拟浏览器行为,从而获取更完整的数据。
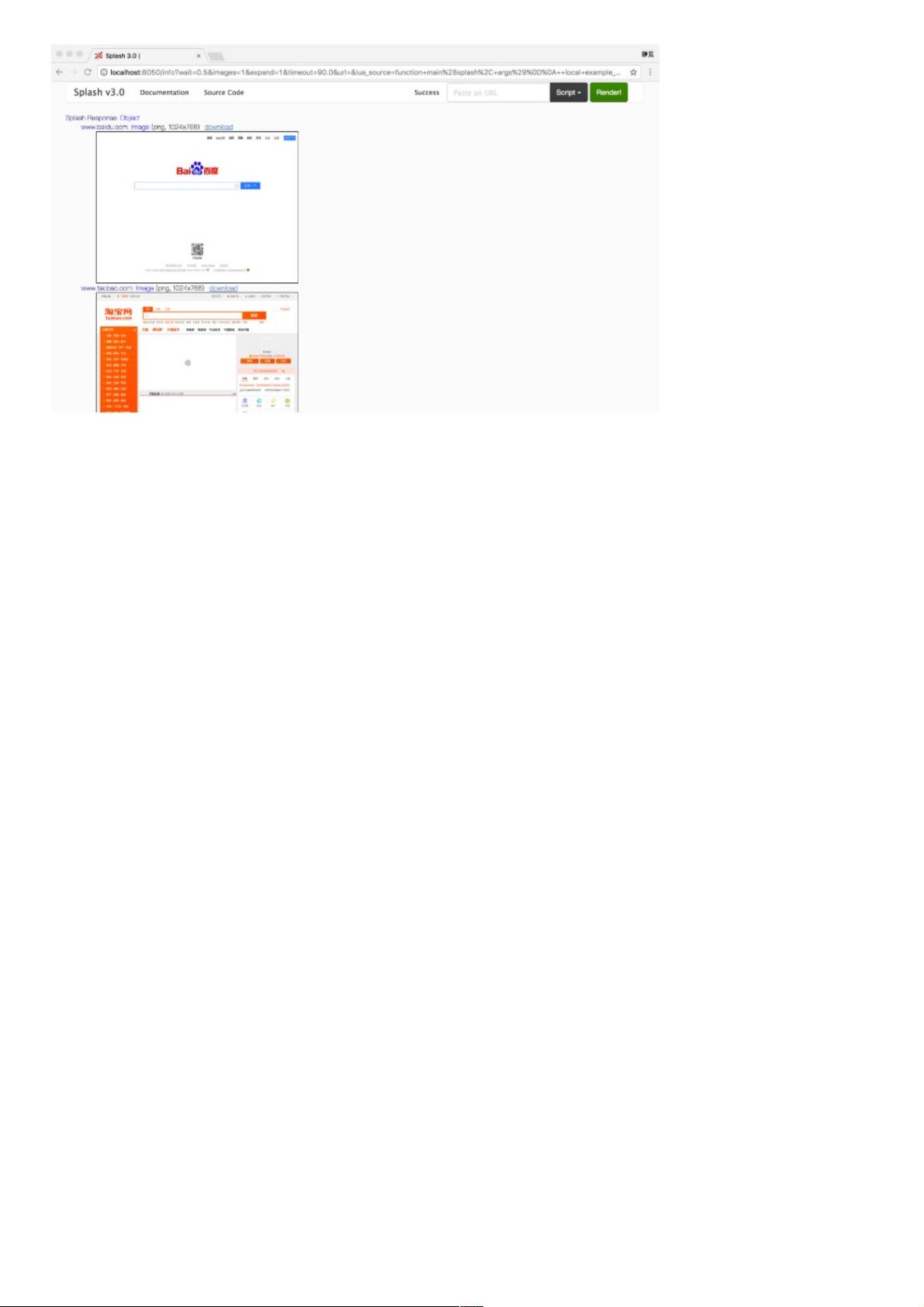
图7-9 运行结果
在脚本内调用的wait()方法类似于Python中的sleep(),其参数为等待的秒数。当Splash执行到此方法时,它会转而去处理其他
任务,然后在指定的时间过后再回来继续处理。
这里值得注意的是,Lua脚本中的字符串拼接和Python不同,它使用的是..操作符,而不是+。如果有必要,可以简单了解一下
Lua脚本的语法,详见http://www.runoob.com/lua/lua-basic-syntax.html。
另外,这里做了加载时的异常检测。go()方法会返回加载页面的结果状态,如果页面出现4xx或5xx状态码,ok变量就为空,就
不会返回加载后的图片。
5. Splash对象属性对象属性
我们注意到,前面例子中main()方法的第一个参数是splash,这个对象非常重要,它类似于Selenium中的WebDriver对象,我
们可以调用它的一些属性和方法来控制加载过程。接下来,先看下它的属性。
args
该属性可以获取加载时配置的参数,比如URL,如果为GET请求,它还可以获取GET请求参数;如果为POST请求,它可以获
取表单提交的数据。Splash也支持使用第二个参数直接作为args,例如:
function main(splash, args)
local url = args.url
end
这里第二个参数args就相当于splash.args属性,以上代码等价于:
function main(splash)
local url = splash.args.url
end
js_enabled
这个属性是Splash的JavaScript执行开关,可以将其配置为true或false来控制是否执行JavaScript代码,默认为true。例如,
这里禁止执行JavaScript代码:
function main(splash, args)
splash:go("https://www.baidu.com")
splash.js_enabled = false
local title = splash:evaljs("document.title")
return {title=title}
end
接着我们重新调用了evaljs()方法执行JavaScript代码,此时运行结果就会抛出异常:
{
"error": 400,
"type": "ScriptError",
"info": {
"type": "JS_ERROR",
"js_error_message": null,
"source": "[string \"function main(splash, args)\r...\"]",
剩余19页未读,继续阅读
2022-06-11 上传
2023-12-30 上传
2022-07-01 上传
2021-09-13 上传
2020-09-21 上传
2017-04-01 上传
2021-09-23 上传
2021-06-17 上传
2021-02-03 上传

weixin_38717870
- 粉丝: 2
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







最新资源
- radio-pomarancza:Szablon PHP,HTMLCSS pod广播互联网
- mini-project-loans:Lighthouse Labs迷你项目,用于创建简单的贷款资格API
- 行业分类-设备装置-可远程控制的媒体分配装置.zip
- 密码战
- Python库 | OT1D-0.3.5-cp39-cp39-win_amd64.whl
- Reactivities
- VB仿RealonePlayer播放器的窗体界面
- symfony_issuer_40452
- healthchecker
- 行业分类-设备装置-可编程多媒体控制器的编程环境和元数据管理.zip
- dosmouse:只是为了好玩:是我在汇编程序I386中编写的一个程序,用于在MsDOS控制台上使用鼠标(在Linux上,类似的程序称为gpm)
- Python库 | os_client_config-1.22.0-py2.py3-none-any.whl
- HERBv1
- BuzzSQL-开源
- show-match:一个允许用户从特定频道搜索电视节目并保存该列表以供将来参考的应用
- ETL-Project:该项目将利用ETL流程
