




复旦大学2014年操作系统课程介绍与教学资源
需积分: 1 189 浏览量
更新于2024-07-21
收藏 7.55MB PDF 举报
"操作系统课程介绍:Fudan University 2014年秋季学期"
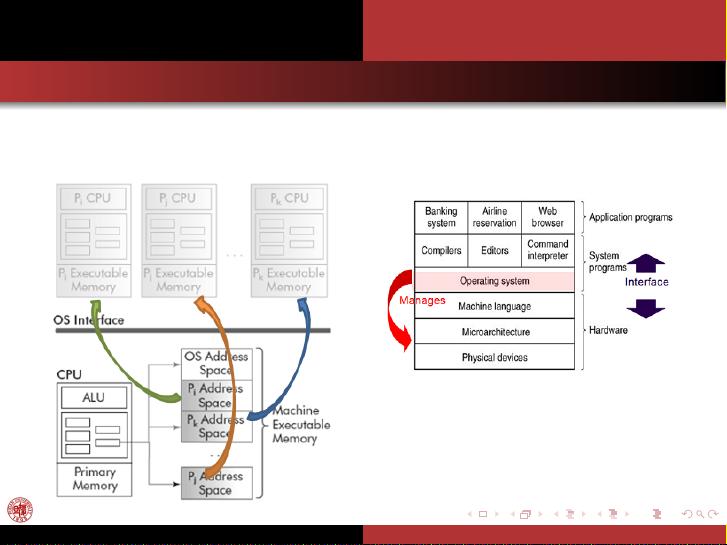
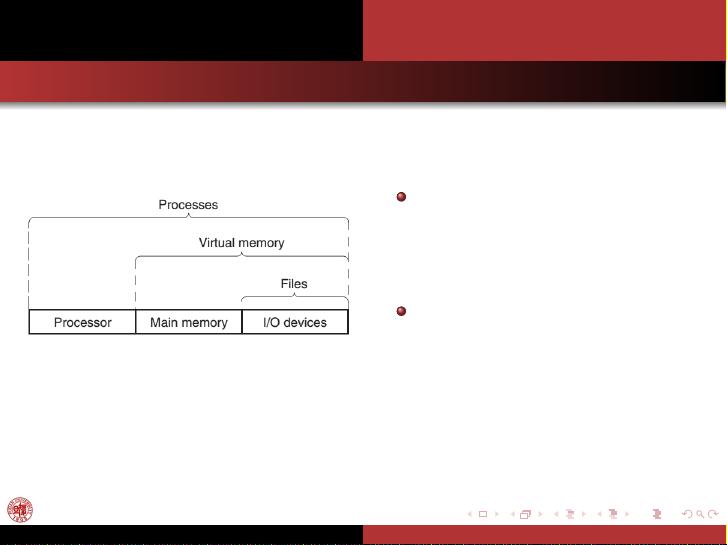
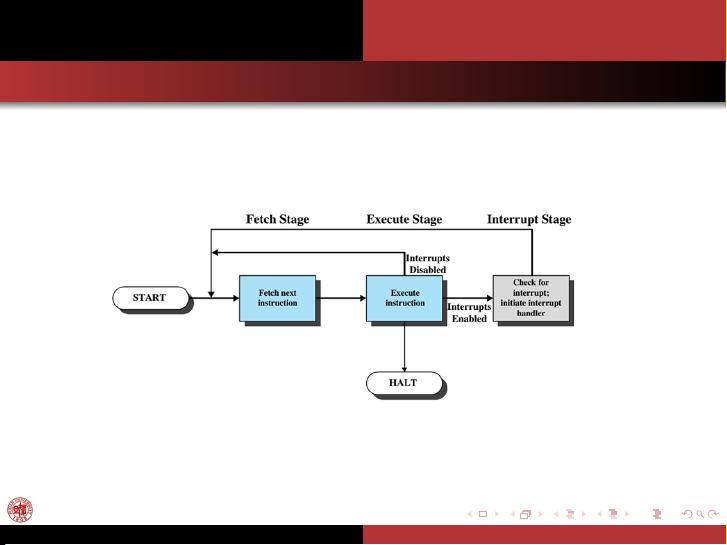
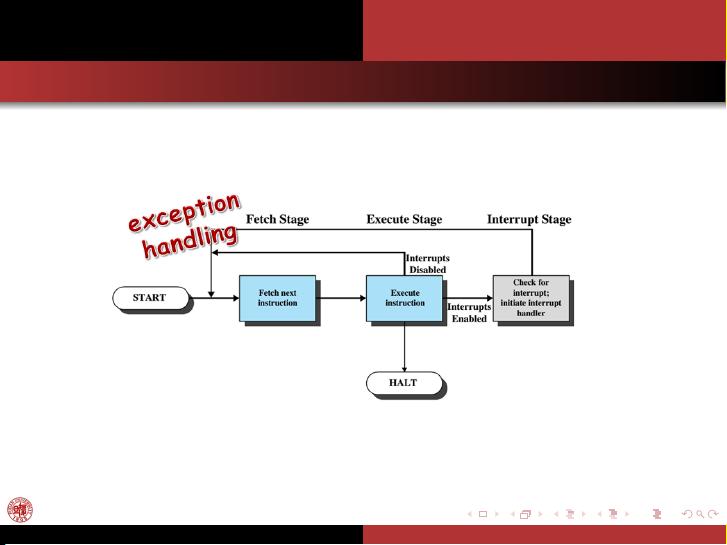
该课程是Fudan大学计算机科学学院在2014年秋季开设的一门名为《Operating Systems》(COMP130110.01)的专业课程,由刘强教授主讲。课程的主要目标是为了让学生深入理解操作系统的基本概念、原理和实践应用。
课程大纲分为两个主要部分:课程信息和具体内容。首先,课程信息部分涵盖了课程的重要细节,如:
1. 课程名称:明确为《Operating Systems》,强调其作为计算机科学的核心课程地位。
2. 教材:推荐了两本教材,分别是A.Silberschatz、P.B.Galvin和G.Gagne合著的《Operating System Concepts》第九版,以及Y.Chen和Y.Xiang编写的《操作系统实验室指南》。教学语言为英语,实验室指导则采用双语模式。
3. 参考材料:学生可以访问Fudan大学的在线学习平台(http://elearning.fudan.edu.cn/)获取辅助教学资料。
4. 阅读材料:包括经典的 xv6 教学操作系统源代码,以及至少每名学生需要阅读的补充文章。
在"Who, When, and Where"这一部分,课程安排了固定的上课时间和地点,具体包括刘强教授授课、辅导老师 Kaiyu QIAN 的总体指导以及Jiankun LEI 负责实验室指导。讲师的联系方式也提供了,便于学生及时沟通交流。
此外,课程的"Wha

163 浏览量
2009-07-10 上传
2019-09-11 上传
2025-03-24 上传
2023-06-06 上传
110 浏览量
169 浏览量
124 浏览量
798 浏览量


Leon12234567
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- LG Gram 14Z90N黑苹果安装指南与EFI文件下载
- HTML5 Canvas照片墙插件:拖放与图片编辑功能介绍
- 汉化版系统管理员密码恢复工具发布
- 如何手动修复PDF图标无法正常显示的问题
- Java实现的IOT照明模拟系统
- 魔兽争霸辅助神器:冰封键盘修改器使用教程
- 易用小巧的视频剪辑软件介绍
- 基于51单片机的PLC程序开发教程
- JMeter 4.0源码使用与ANTjar包替换指南
- HTML5 SVG焦点图导航箭头:增强用户体验动画设计
- 实时订单列表联邦测试与部署指南
- 基于51芯片的24路继电器串口上下位机控制
- ASP网上书店系统完整教程及毕业论文
- 易语言打造个性化表白软件教程及源码分享
- 详解DLT645-2007多功能电能表通信协议
- HTML5与jQuery实现的鼠标控制圆形进度条插件










