理解Kafka的优秀架构设计:主题与分区
版权申诉
49 浏览量
更新于2024-08-10
收藏 526KB DOCX 举报
"大白话认识 Kafka 背后优秀的架构设计"
Kafka 是一个高度可扩展和高吞吐量的分布式消息系统,广泛应用于实时数据流处理和大数据分析。本文将深入浅出地探讨 Kafka 的核心概念和架构设计,帮助读者理解其优秀之处。
首先,消息系统在软件架构中扮演着至关重要的角色。它充当了不同系统间的通信桥梁,通过存储和转发消息来实现系统的解耦合。以仓库比喻,消息系统能够临时存储数据,确保即使在系统间短暂断开连接时也能保持正常运行。
Kafka 的基本组件包括 Topic(主题)、Partition(分区)以及 Producer(生产者)、Consumer(消费者)和 Message(消息)。Topic 类似于数据库中的表,用于分类和存储消息。Partition 是 Topic 的物理细分,分布在多个服务器上,确保数据的水平扩展性和高并发处理能力。每个 Partition 又由多个日志文件(.log 文件)组成,便于并行处理,从而提升性能。
Partition 还引入了副本(Replication)机制,以防止单点故障。每个 Partition 都有一个主副本和若干个从副本,确保数据的安全性和可用性。分区编号从0开始,便于管理和操作。
Producer 负责向 Kafka 发送数据,而 Consumer 则负责从 Kafka 中消费数据。Kafka 提供了两种消费模式:偏移量(Offset)管理和消费者组(Consumer Group)。Offset 是消费者读取的当前位置,而消费者组允许多个消费者协同工作,共同消费一个 Topic 的所有 Partition,实现了负载均衡。
Kafka 的集群架构由多个 Broker 组成,每个 Broker 存储部分 Topic 和 Partition。通过 ZooKeeper 进行集群协调,确保数据一致性。当新消息写入时,生产者将消息发送到特定 Partition,通常是基于键值的哈希或轮询策略。消费者则按需从 Broker 拉取消息。
Kafka 的优势在于它的高吞吐量、低延迟和持久化特性。由于数据被持久化到磁盘,即使在系统重启后,消息也不会丢失。此外,Kafka 还支持在线缩扩容,适应业务需求的变化。
Kafka 的优秀架构设计体现在其强大的消息处理能力、分布式特性和容错机制上,使其成为大数据实时处理领域不可或缺的一部分。了解和掌握这些核心概念,对于理解和使用 Kafka 进行实时数据处理至关重要。
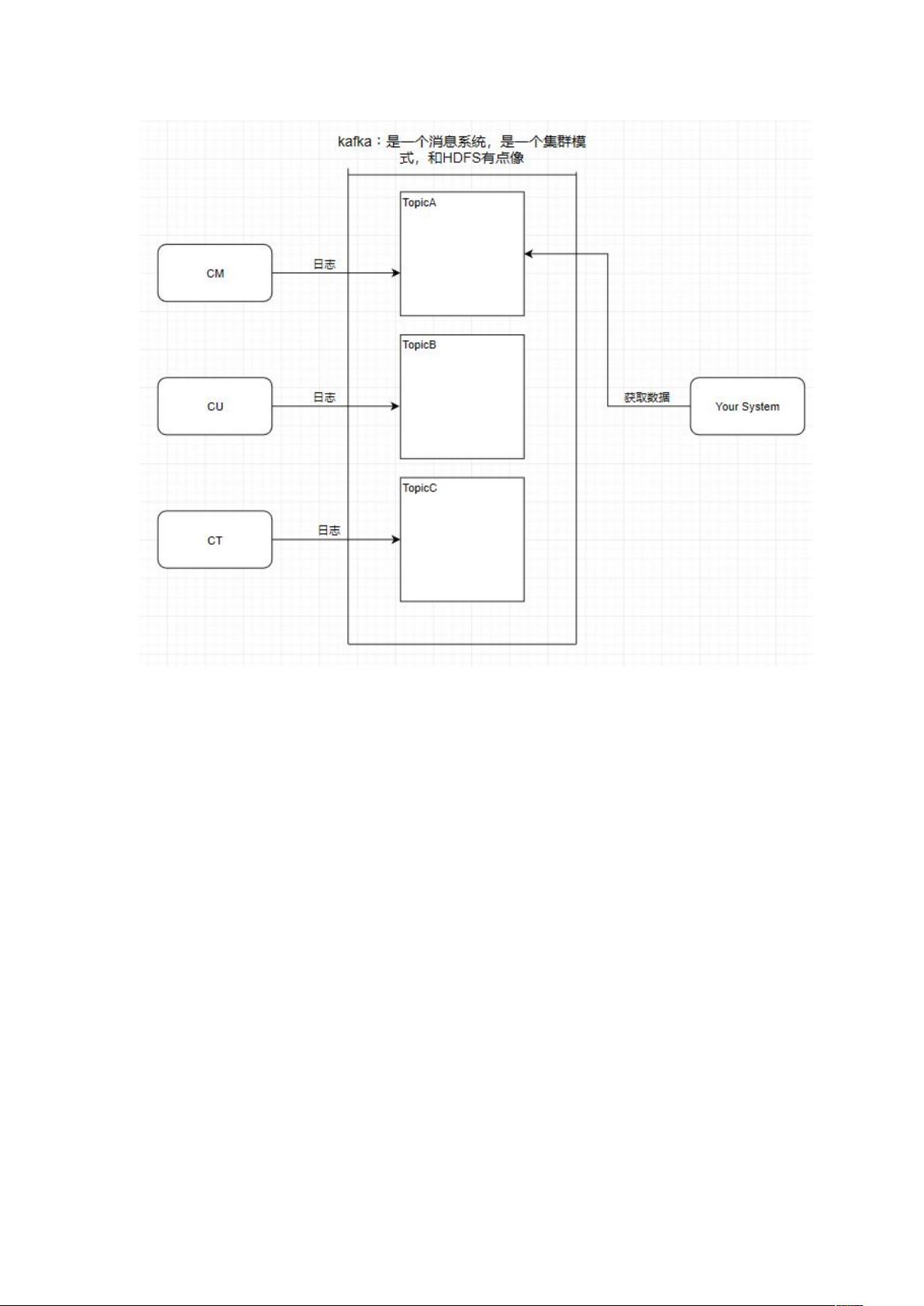
此时我需要获取中国移动的数据,那就直接监听 TopicA 即可
2.Partition 分区
kafka 还有一个概念叫 Partition(分区),分区具体在服务器上面表现起初就是一个目录,一
个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主
机上建了不同的目录。这些分区主要的信息就存在了.log 文件里面。跟数据库里面的分区差不
多,是为了提高性能。
剩余13页未读,继续阅读
2023-09-08 上传
2021-10-24 上传
2022-12-13 上传
2024-01-06 上传
2022-06-20 上传
2024-01-06 上传
2024-01-06 上传
2024-01-06 上传
2024-01-06 上传

jane9872
- 粉丝: 109
- 资源: 7795
 我的内容管理
展开
我的内容管理
展开







