Python Pandas操作Excel:DataFrame列处理与实战示例
167 浏览量
更新于2024-08-30
收藏 353KB PDF 举报
本篇文章主要介绍了如何使用Python的pandas库对Excel文件进行操作,特别关注DataFrame对象中列(Column)的处理。pandas的DataFrame是一个强大的数据结构,它的每一行或列都表现为一个Series对象,这使得数据处理和分析变得高效。
首先,我们学习了如何读取Excel文件,例如使用`pd.read_excel()`函数导入数据,如文件'./excel-comp-data.xlsx'。通过`type(df1['city'])`检查,可以确认数据列的类型为`pandas.core.series.Series`,这体现了pandas基于numpy进行底层数据操作的特点,所有计算都是针对整个列进行的。
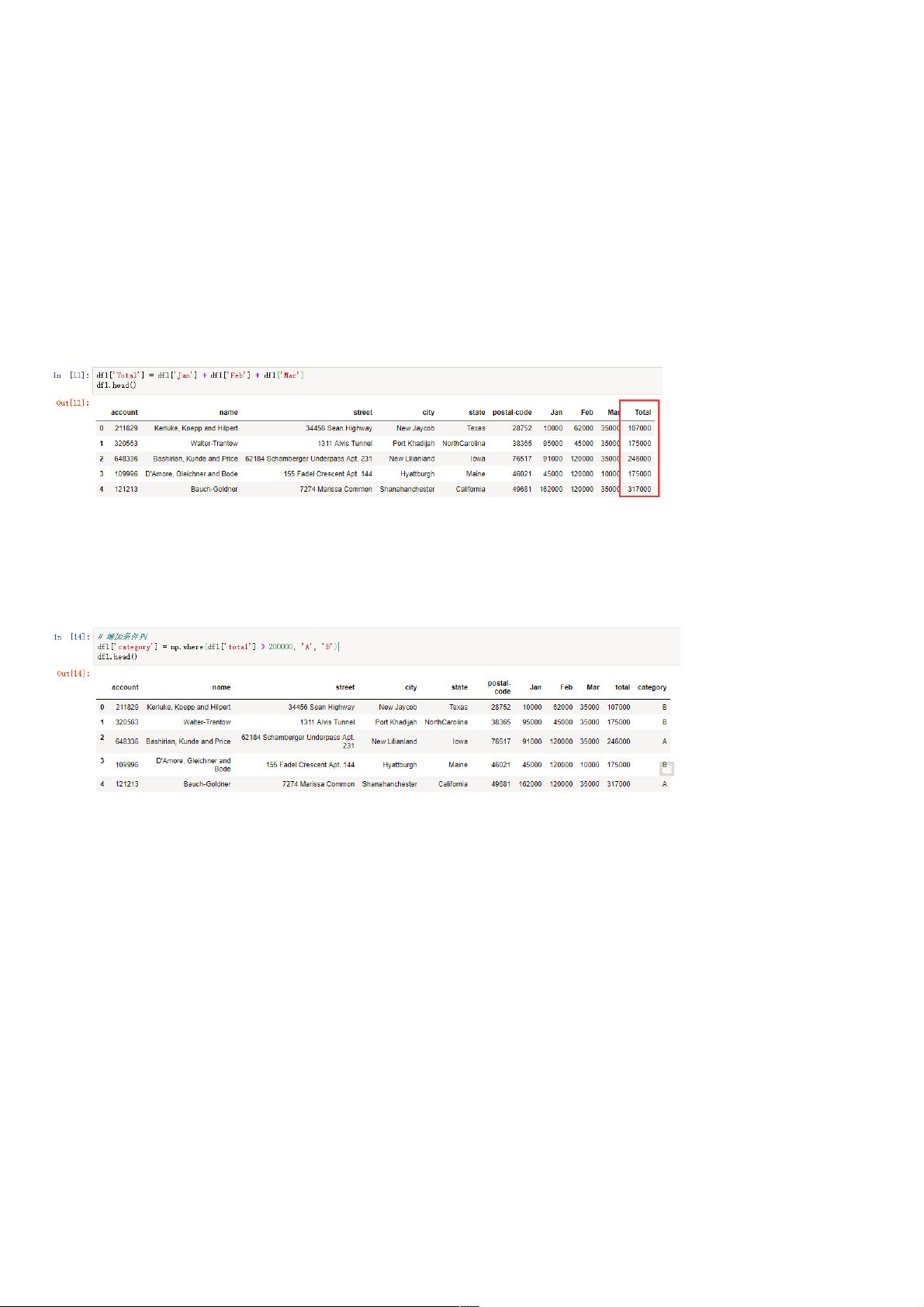
对于数据操作,文章展示了如何增加新的计算列。例如,通过将不同月份的数据相加,如`df1['Total'] = df1['Jan'] + df1['Feb'] + df1['Mar']`,可以轻松地在DataFrame中创建新的数据项。这里的加法操作是利用Series的性质,可以逐元素进行。
接下来,文章涉及条件计算列的创建。在pandas中,可以使用`numpy.where()`函数来根据特定条件应用不同的值,如根据'(total'列大于200,000)设置类别为'A',否则为'B',即`df1['category'] = np.where(df1['total'] > 200000, 'A', 'B')`。
在调整列的位置时,文章提到了`dataframe.insert()`方法。这种方法允许我们在DataFrame的指定位置插入新的列,比如在现有的'state'列之后添加列'abbreviation',这与Excel中的插入操作相似,但更具灵活性。
总结来说,这篇文章详细展示了如何使用pandas对Excel数据进行增删改查,包括创建计算列、条件计算和调整列位置等基本操作,这对于理解和处理大量Excel数据具有实际指导意义。对于初学者或进阶用户,熟练掌握这些操作技巧能极大地提高数据处理效率。
Python pandas对对excel的操作实现示例的操作实现示例
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程。本篇介绍 pandas 的 DataFrame 对列 (Column) 的处理方法。示例数据请
通过明哥的gitee进行下载。
增加计算列增加计算列
pandas 的 DataFrame,每一行或每一列都是一个序列 (Series)。比如:
import pandas as pd
df1 = pd.read_excel('./excel-comp-data.xlsx');
此时,用 type(df1['city'],显示该数据列(column)的类型是 pandas.core.series.Series。理解每一列都是 Series 非常重要,因为 pandas 基于 numpy,对数据的计算都是整体计算。深刻理解这个,才能理解后
面要说的诸如 apply() 函数等。
如果列名 (column name)没有空格,则列有两种方式表达:
df1['city'] df1.city
如果列名有空格,或者创建新列(即该列不存在,需要创建,第一次使用的变量),则只能用第一种表达式。
假设我们要对三个月的数据进行汇总,可以使用下面的方法。实际上就是创建一个新的数据列:
# 由于是创建,不能使用 df.Total
df1['Total'] = df1['Jan'] + df1['Feb'] + df1['Mar']
df1['Jan'] 到 df1['Mar'] 都是 Series,所以使用 + 号,可以得到三个 Series 对应位置的数据合计。
当然,也可以用下面的方式:
df1['total'] = df1.Jan + df1.Feb + df1.Mar
增加条件计算列增加条件计算列
假设现在要根据合计数 (Total 列),当 Total 大于 200,000 ,类别为 A,否则为 B。在 Excel 中实现用的是 IF 函数,但在 pandas 中需要用到 numpy 的 where 函数:
df1['category'] = np.where(df1['total'] > 200000, 'A', 'B')
在指定位置插入列在指定位置插入列
上面方法增加的列,位置都是放在最后。如果想要在指定位置插入列,要用 dataframe.insert() 方法。假设我们要在 state 列后面插入一列,这一列是 state 的简称 (abbreviation)。在 Excel 中,根据 state 来找
到 state 的简称 ,一般用 VLOOKUP 函数。我们用两种方法来实现,第一种方法,简称来自 Python 的 dict。
数据来源:
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU",
"KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI",
"NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM",
"Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL",
"Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA",
"PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM",
"MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE",
"NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA",
"MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH",
"WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA",
"NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND",
"Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI",
"DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}
如果我们想根据 dict 的 key 找到对应的值,可以使用 dict.get() 方法,这个方法在找不到 key 的时候,不会抛出异常,只是返回 None。比如
state_to_code.get('TEXAS') # 返回 TX
state_to_code.get('TEXASS') # 返回 None
dict.get() 方法参数为 key,是一个标量值。我们并不能像下面这样把整列都传给这个方法,比如下面这样:
df1['abbrev'] = state_to_code.get(df1['state'])
所以我们需要先构造一个 Series (abbrev),然后把 abbrev 赋值给 df1['abbrev']:
abbrev = df1['state'].apply(lambda x: state_to_code.get(x.upper()))
df1['abbrev'] = abbrev # 在后面插入列
df1.insert(6, 'abbr', abbrev) # 在指定位置插入列
apply() 函数值得专门写一篇,暂且不细说。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-12-16 上传
2020-09-19 上传
2020-09-20 上传
2020-09-18 上传
2023-12-05 上传
2023-03-16 上传

weixin_38665804
- 粉丝: 11
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
