Spark与HPC算法融合:探索大数据平台的创新应用
需积分: 5 154 浏览量
更新于2024-07-17
收藏 1020KB PDF 举报
在"Bringing HPC Algorithms to Big Data Platforms"的演讲中,Nikolay Malitsky代表Brookhaven National Laboratory在SPARK SUMMIT 2017上探讨了如何将高性能计算(HPC)算法融入大数据平台,特别是以Spark作为实验设施的集成平台。Spark被提及是因为它作为一种强大的数据处理工具,能够支持大规模数据处理和分布式计算,这对于数据密集型科学,如在国家同步辐射光源II(NSLS-II)这样的高级光子源进行的研究尤为关键。
NSLS-II是一个高度优化的第三代同步辐射设施,于2014年在纽约州的Brookhaven国家实验室启动,提供六个实验项目,涵盖了硬X射线光谱学、成像与显微镜、结构生物学、软X射线散射与光谱学、复杂散射以及衍射与实时散射等多个领域。这些研究需要海量数据处理能力,以支撑从基本能源科学到核物理等多学科的前沿研究。
演讲重点讨论了如何弥合大数据和高性能计算生态系统之间的差距,强调了两个主要的领导者:Spark和MPI(Message Passing Interface)。Spark以其易用性和可扩展性成为大数据处理的首选,而MPI则是传统HPC环境中的标准通信接口。为了适应这个融合趋势,提出了三个发展方向:
1. Spark+MPI导向的扩展:通过结合Spark的并行处理能力和MPI的高效通信,可以开发出新的工具和框架,使得HPC算法能够在Spark的分布式环境中无缝运行,提高性能和效率。
2. Spark与大数据分析库的整合:这可能涉及到对Spark API的扩展,使其能更好地支持HPC中的科学计算库,使得科学家可以直接利用Spark进行复杂的数值模拟和数据分析。
3. 新的编程模型和API:可能会出现新的编程模型或API设计,旨在简化将HPC算法迁移到大数据平台的过程,降低学习曲线,促进科研人员之间的交流和合作。
演讲者探讨了如何通过创新的技术融合,如Spark-MPI方法,将高性能计算的力量注入到大数据平台中,以应对数据驱动的科学研究需求,尤其是在具有挑战性的领域,如NSLS-II的实验工作中。这不仅有助于提升科研效率,也有望推动整个科学界的进步。
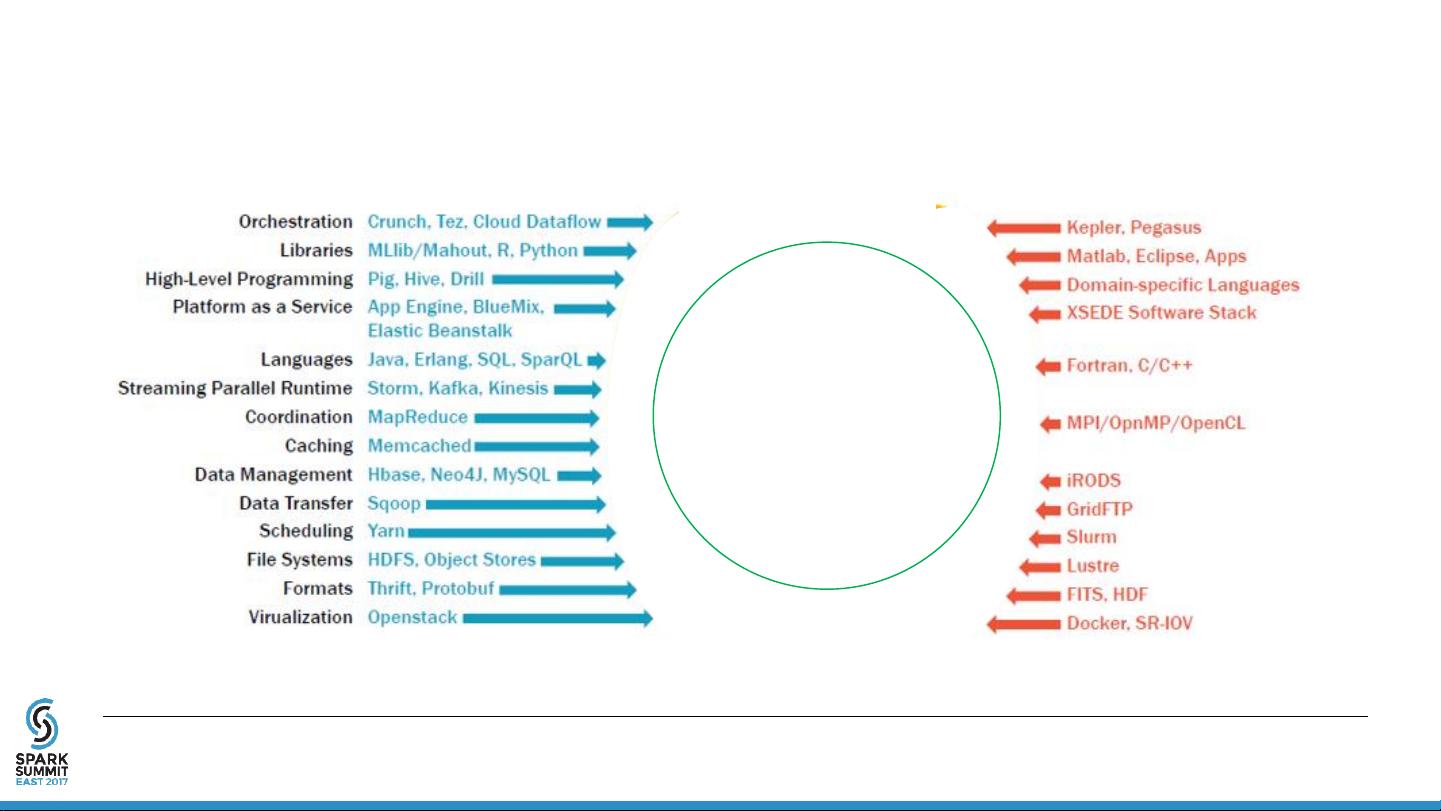
Closing a gap between Big Data and HPC computing
Ecosystems*:
Big Data HPC Computing
*Geoffrey Fox et al. HPC-ABDC High Performance Computing Enhanced Apache Big Data Stack, CCGrid, 2015
Leaders:
Spark
MPI
New Frontiers
剩余20页未读,继续阅读
2024-10-16 上传
2024-10-16 上传
2024-10-16 上传
2024-10-16 上传
2024-10-16 上传

weixin_38743737
- 粉丝: 376
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
