概率主题模型:文献与应用
"这篇资源是关于LDA(Latent Dirichlet Allocation)主题模型的一篇文献,由David M. Blei撰写,详细介绍了概率主题模型在处理大量信息时的作用,如发现隐藏的主题、文档注解以及组织和搜索信息。文中可能会涉及到其他主题模型如CTM(Collaborative Topic Model),并探讨了如何利用这些模型来理解和解析文本数据中的关键概念。"
在主题建模领域,LDA是一种广泛应用的概率模型,主要用于从大量文本数据中发现隐藏的主题结构。LDA假设每个文档是由多个主题混合而成,而每个主题又由一系列概率较高的词汇构成。这种模型通过概率分布来描述文档和主题、主题和词汇之间的关系,从而揭示出文本背后的潜在语义。
LDA的基本过程包括以下几个步骤:
1. 预处理:对原始文本进行分词、去除停用词等预处理操作。
2. 初始化:随机分配每个文档一个主题分布和每个主题一个词汇分布。
3. 推断:根据贝叶斯公式迭代更新文档主题分布和主题词汇分布,直到模型稳定或达到预设迭代次数。
4. 解析结果:分析最终的主题分布,识别出主要的主题和对应的关键词。
CTM(Collaborative Topic Model)则是一种扩展的LDA模型,它引入了协同过滤的思想,考虑了用户和文档之间的交互,用于发现用户兴趣的主题,适用于推荐系统等领域。
主题模型在实际应用中具有广泛的价值,例如:
1. 文档分类与聚类:通过主题分布可以将文档自动归类到相应的主题类别中。
2. 摘要生成:提取文档中与主题相关的关键句子,生成摘要。
3. 信息检索:利用主题信息改进搜索引擎的查询性能,提供更精准的搜索结果。
4. 社交媒体分析:分析社交媒体上的热点话题,理解公众关注的焦点。
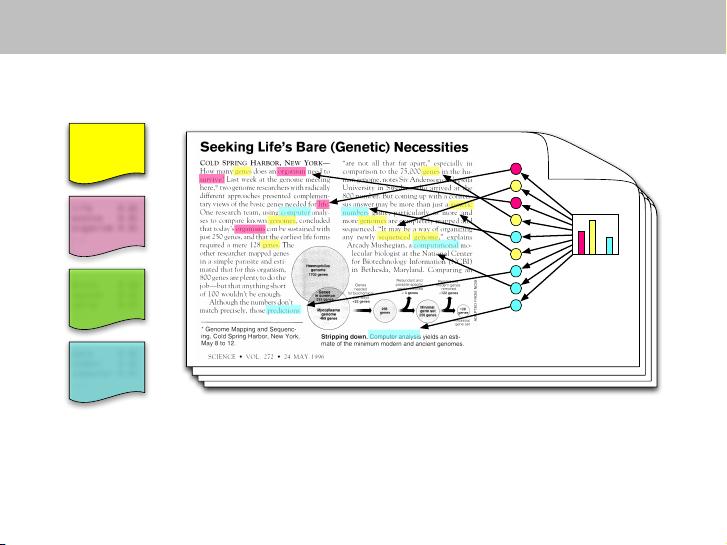
论文中提到的一些关键词,如“Genetics”、“Evolution”、“Disease”和“Computers”,可能代表了研究领域的四个主要主题,分别涉及遗传学、进化论、疾病和计算机科学。通过这些主题,可以对包含这些词汇的文档进行深入的分析和理解。
LDA和CTM等主题模型为大数据时代的文本挖掘提供了有力工具,帮助我们理解、组织和探索信息海洋,推动科研、教育、商业等多个领域的知识发现和创新。通过对这些模型的深入学习和应用,我们可以更好地应对信息爆炸带来的挑战,提高信息处理的效率和准确性。
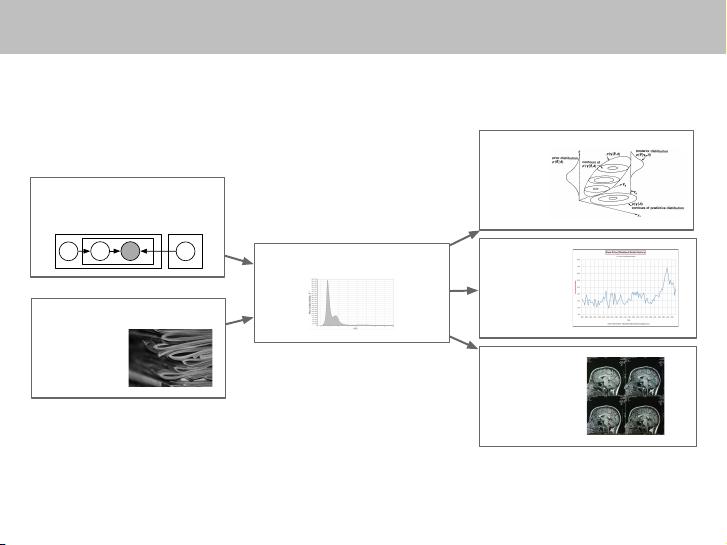
Probabilistic models
Make assumptions
Infer the posterior
Explore
Collect data
Predict
Check



剩余210页未读,继续阅读
2021-07-14 上传
2021-08-09 上传
2021-08-09 上传
2021-08-26 上传
2021-07-07 上传
2021-09-24 上传
点击了解资源详情
点击了解资源详情

a2921599
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
