Flume学习笔记:从源到sink的高可用日志采集系统详解
需积分: 8 90 浏览量
更新于2024-07-16
收藏 2.89MB PPTX 举报
Flume学习笔记深入解析
Flume是一个由Cloudera开发并后来归属Apache的分布式、高可靠的大数据日志采集、聚合和传输系统。它最初在2010年开源,经历了从Flume-OG(0.9.2及后续版本)到Flume-NG的重大重构,以解决早期版本存在的代码冗余、核心组件设计问题和日志传输稳定性不足的问题。
Flume的核心设计理念是基于事件驱动的模型,其数据流以事件(Event)为中心。Event是Flume的基础数据单元,它封装了日志数据(通常是字节数组格式),并携带可选的消息头。事件由外部Source组件生成,源负责捕获数据并对其进行格式化,然后将事件放入Channel(类似于一个缓冲区),等待Sink进行进一步处理,如持久化或传递到下一个Source。
一个Flume Agent是JVM中的一个独立进程,它由Source、Channel和Sink这三个核心组件组成。Source是数据的入口点,负责接收并处理来自客户端的数据;Channel作为数据传输的中间环节,存储事件直到Sink完成处理;Sink则是事件的出口点,负责将数据写入目标存储或者转发到其他Source。
Flume-NG的重构旨在优化代码结构,提高性能和稳定性,包括标准化配置、改进核心组件设计,以及适应Apache项目管理。这一重构也使得Flume能够更好地与其他Apache工具集成,满足大规模、高并发的日志收集需求。
Flume的灵活性体现在其丰富的插件系统,用户可以根据具体场景自定义数据发送方(Source)、数据通道(Channel)和数据接收方(Sink),以适应不同类型的日志源和目的地,如HDFS、Kafka、HBase等。
总结来说,Flume是大数据处理中的关键组件,它通过事件驱动的模型和模块化的设计,提供了一种高效、灵活的数据采集解决方案,尤其适合实时监控、日志分析等场景。学习和掌握Flume对于构建和维护大数据管道至关重要。
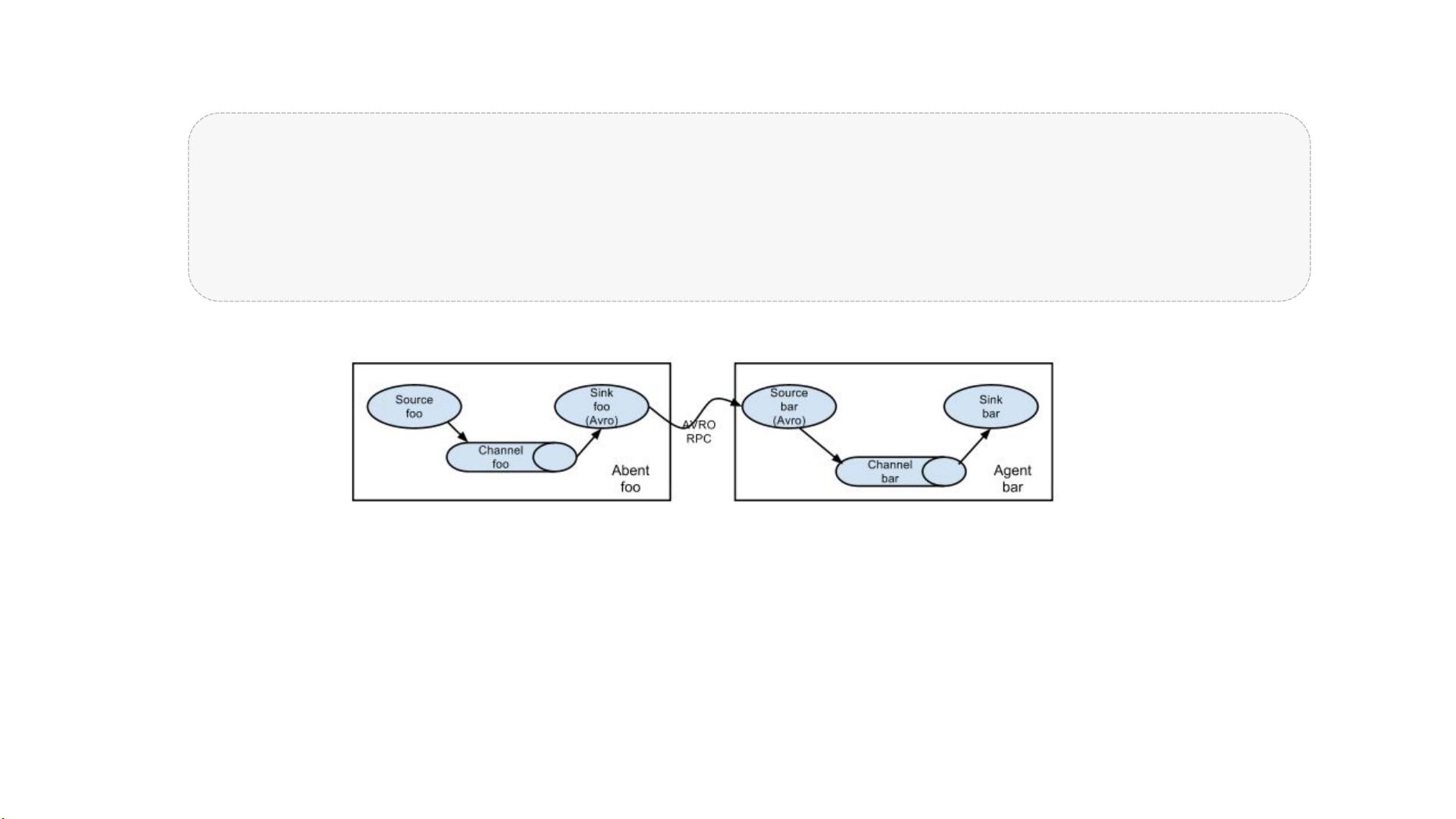
值得注意的是, 提供了大量内置的 、 和 ! 类型。不同类型的 、
和 ! 可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如: 可以把事件暂存在内
存里,也可以持久化到本地硬盘上; ! 可以把日志写入 *+ 、 *," 、 甚至是另外一个 等
等。 支持用户建立多级流,也就是说多个 可以协同工作 # 如下图所示 -
更多的了解,请查看官网: -../.0"
剩余17页未读,继续阅读
2019-10-21 上传
2019-12-21 上传
2023-06-10 上传
2023-06-03 上传
2023-06-13 上传
2023-06-10 上传
exist: /usr/local/flume/example.conf at org.apache.flume.node.Application.main(Application.java:316)
2023-03-24 上传
2023-06-10 上传

qq_1132993896
- 粉丝: 0
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
