Python从零构建神经网络:基础、实现与训练
133 浏览量
更新于2024-08-31
收藏 379KB PDF 举报
"这篇文档介绍了如何使用Python从零开始实现一个简单的神经网络,包括神经元的构建、激活函数的应用、神经网络的搭建以及训练过程。文章以2输入神经元为例,详细阐述了神经元的工作原理,并通过Python代码展示了具体实现。在训练神经网络时,提到了数据集的准备、损失函数(均方误差)的选择以及优化的目标。"
在深入理解神经网络的概念之前,我们首先要了解神经元的基础。神经元是神经网络的基本构建块,它们接收输入,对输入进行加权求和,然后通过激活函数转化为非线性输出。例如,一个2输入神经元会将每个输入乘以相应的权重,接着加上偏置,最后通过激活函数如sigmoid函数转换为(0,1)区间内的输出。sigmoid函数有助于引入非线性,使得神经网络能够拟合更复杂的函数。
Python实现神经元的运算非常直观。假设我们有输入向量x和权重向量w,以及偏置b,我们可以用以下方式计算输出:
```python
output = sigmoid(dot(w, x) + b)
```
其中`dot()`函数表示向量点积,`sigmoid()`是激活函数。对于sigmoid函数,其公式为1 / (1 + e^(-x)),可以使用Python中的math库或numpy库实现。
接下来,我们构建一个简单的神经网络,包含输入层、隐藏层和输出层。隐藏层是位于输入层和输出层之间的中间层,可以有多个。前馈过程是将输入数据逐层传递,通过各层神经元的计算,最终得到输出。例如,一个两层神经网络的前馈计算可以通过循环遍历所有层和神经元来实现。
在训练神经网络时,我们需要一个数据集来调整权重和偏置。以身高、体重预测性别的问题为例,数据预处理是必要的,如归一化特征和编码类别变量。同时,定义一个损失函数来衡量模型预测的准确性,如均方误差(MSE)。MSE是预测值与真实值之间差异的平方和的平均值,越小表示模型的预测越接近实际。
训练过程本质上是一个优化问题,目标是找到最小化损失函数的权重和偏置。这通常通过梯度下降等优化算法完成,其中模型参数在每次迭代中依据损失函数的梯度进行更新。在Python中,可以使用优化库如scipy的optimize.minimize或深度学习框架如TensorFlow、PyTorch来实现这一过程。
本文档提供了一个逐步的指南,教导读者如何用Python实现一个简单的神经网络,从理解单个神经元到搭建完整的网络结构,再到训练网络以适应特定任务。这个过程涉及了基础的数学概念、Python编程技巧以及机器学习中的核心概念。
Python实现简单的神经网络实现简单的神经网络
从零开始学习神经网络
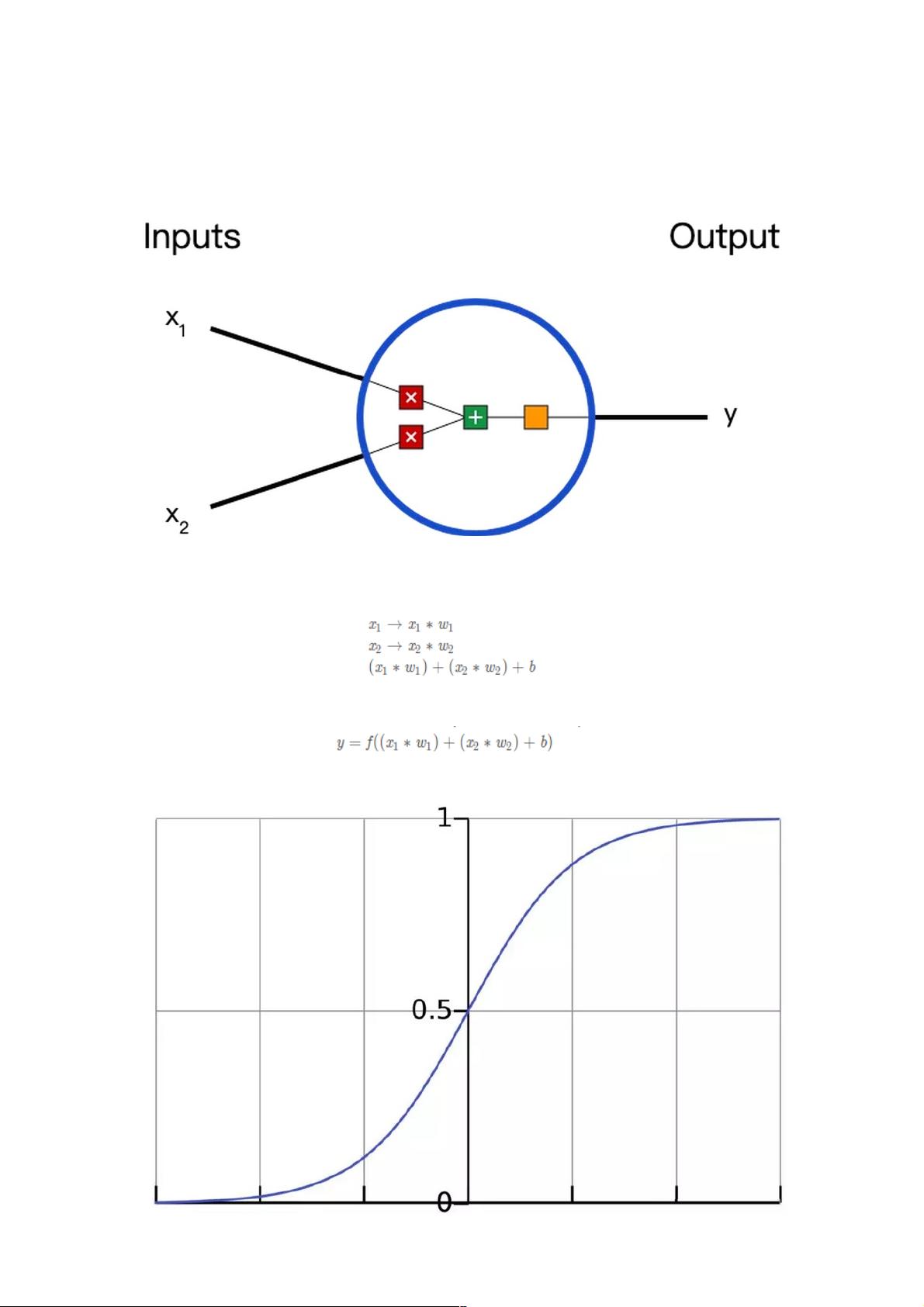
搭建基本模块—神经元
在说神经网络之前,我们讨论一下神经元(Neurons),它是神经网络的基本单元。神经元先获得输入,然后执行某些数学运
算后,再产生一个输出。比如一个2输入神经元的例子:
在这个神经元里,输入总共经历了3步数学运算,
先将输入乘以权重(weight):
最后经过激活函数(activation function)处理得到输出:
激活函数的作用是将无限制的输入转换为可预测形式的输出。一种常用的激活函数是sigmoid函数:
sigmoid函数的输出介于0和1,我们可以理解为它把 (-∞,+∞) 范围内的数压缩到 (0, 1)以内。正值越大输出越接近1,负向数值
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-20 上传
2024-03-02 上传
2024-02-22 上传
2022-06-13 上传

weixin_38582716
- 粉丝: 6
- 资源: 929
 我的内容管理
展开
我的内容管理
展开







最新资源
- R语言中workflows包的建模工作流程解析
- Vue统计工具项目配置与开发指南
- 基于Spearman相关性的协同过滤推荐引擎分析
- Git基础教程:掌握版本控制精髓
- RISCBoy: 探索开源便携游戏机的设计与实现
- iOS截图功能案例:TKImageView源码分析
- knowhow-shell: 基于脚本自动化作业的完整tty解释器
- 2011版Flash幻灯片管理系统:多格式图片支持
- Khuli-Hawa计划:城市空气质量与噪音水平记录
- D3-charts:轻松定制笛卡尔图表与动态更新功能
- 红酒品质数据集深度分析与应用
- BlueUtils: 经典蓝牙操作全流程封装库的介绍
- Typeout:简化文本到HTML的转换工具介绍与使用
- LeetCode动态规划面试题494解法精讲
- Android开发中RxJava与Retrofit的网络请求封装实践
- React-Webpack沙箱环境搭建与配置指南
