演进式理解消息队列:从Redis到Kafka、Pulsar
版权申诉
56 浏览量
更新于2024-07-11
收藏 924KB DOCX 举报
"从演进式角度看消息队列"
本文作者刘德恩,身为腾讯IEG的研发工程师,探讨了消息队列的不同实现及其演进过程,主要以redis、kafka和pulsar为例。文章首先介绍了最基础的消息队列概念,即使用双向链表实现的双端队列,其中producer负责添加消息,consumer负责取出并使用消息。
接着,文章讨论了redis如何作为消息队列使用。redis的list数据结构提供了lpush(左插入)和rpop(右取出)操作,恰好满足队列的基本需求。由于redis对高并发进行了优化,使用其list作为消息队列在性能上有一定优势。然而,redis作为内存数据库,其持久化机制(aof和rdb)并不完全可靠,可能会在服务器宕机时丢失数据,这对许多业务来说是不可接受的。此外,redis的热key问题可能导致高并发下的性能瓶颈,无法通过扩容解决。
接下来,文章提到了kafka,它是一个更高级的消息队列系统,设计用于处理大规模的实时数据流。与redis不同,kafka提供了消息的持久化和分区机制,确保高可用性和可扩展性。每个主题(topic)可以被分成多个分区(partition),每个分区在集群中的一个broker上,这样可以分散读写负载。kafka还支持消费者组,使得多个消费者可以并行消费同一主题的不同分区,提高了处理能力。
最后,文章提到了pulsar,这是一个分布式的消息队列系统,旨在解决大数据和物联网场景下的消息处理问题。pulsar引入了租约、分层存储和多命名空间的概念,进一步增强了消息的管理和持久化能力,同时也支持订阅模式的灵活性,包括独占、共享和故障转移等。
选择消息队列需根据业务需求考虑其持久化、并发处理能力、扩展性以及可靠性等因素。redis适合轻量级和低延迟的应用场景,而kafka和pulsar更适合需要大规模数据处理和高可用性的复杂环境。在实际应用中,应充分了解各种消息队列的优缺点,以便做出最佳选择。
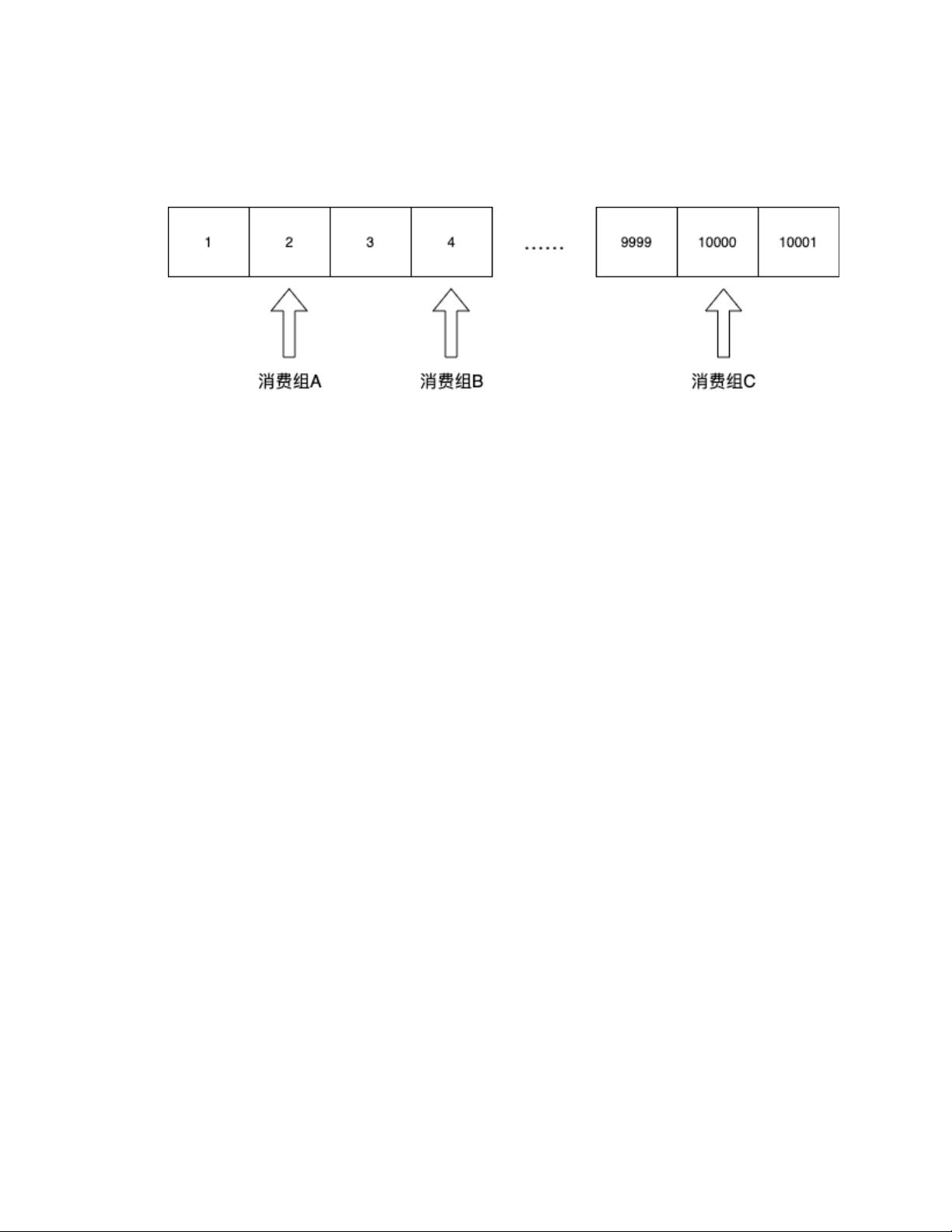
其次是可以支持分组消费:
这里需要引入一个消费组的概念,这个概念格外简约,由于消费组本质上就是一
组游标。对于同一个 topic,不同的消费组有各自的游标。监控组的游标指向其
次条,BI 组的游标指向第 4 条,trace 组指向到了第 10000 ……条 各消费者游
标彼此隔离,互不影响。
通过引入消费组的概念,就可以格外简约地支持多业务方同时消费一个 topic,
也就是说所谓的 1-N “ ”的 广播 ,一条消息广播给 N 个订阅方。
最终,通过游标也很简约实现重新消费。由于游标仅仅就是记录当前消费到哪一
条数据了,要重新消费的话直接修改游标的值就可以了。你可以把游标重置为任
何你想要指定的位置,比如重置到 0 重新开头消费,也可以直接重置到最终,相
当于忽视现有全部数据。
因而你可以看到,kafka 这种数据结构相比于 redis 的双向链表有了一个质的飞
跃,不只是功能上,同时也是功能上,全面的领先。
我们可以来看看 kafka 的一个简约的架构图:
剩余26页未读,继续阅读
2015-01-13 上传
2021-10-14 上传
2021-11-12 上传
2021-12-10 上传
2021-10-14 上传
2021-11-14 上传
2021-10-24 上传
2021-10-24 上传
2021-11-12 上传

bingbingbingduan
- 粉丝: 0
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
