"Flink与Iceberg解决数据入湖挑战"
需积分: 9 185 浏览量
更新于2023-12-26
收藏 12.58MB PDF 举报
数据入湖是指将各种结构化、半结构化和非结构化数据存储到数据湖中的过程。数据湖作为一个存储原始和未加工数据的庞大存储库,有助于组织和管理数据,以满足分析、报告和其他应用程序的需求。然而,数据入湖过程中存在着一系列挑战,包括数据格式管理、数据一致性和查询效率等问题。为了解决这些挑战,业界提出了一些解决方案,其中包括 Apache Flink 和 Apache Iceberg。
Apache Iceberg 是一种开源数据表格式,旨在为数据湖存储提供原生支持。它提供了一种可扩展的表格式,支持事务、元数据管理和快速查询。Iceberg 采用了分层架构,将数据存储在子目录中,并通过元数据管理实现了数据版本控制。这使得 Iceberg 能够有效地管理数据格式、保证数据的一致性和查询效率。
与此同时,Apache Flink 作为一个实时计算引擎,也可以用于实时数据处理和数据湖中的数据管理。Flink 提供了一种灵活、高效的数据处理框架,支持流处理和批处理。同时,Flink 的连接器和集成能力使其能够直接操作数据湖中的数据。
那么,Flink 和 Iceberg 如何解决数据入湖相关的挑战呢?
首先,Iceberg 通过其支持的原生数据表格式,提供了一种统一的数据存储方案。Iceberg 的架构允许用户轻松管理数据表的格式,包括字段定义、分区规则和文件格式。这使得用户能够更加灵活地管理数据,并能够轻松地将数据表导入到数据湖中。Iceberg 还支持数据表的分区和分层存储,能够显著提升查询效率,并支持数据版本控制,以确保数据的一致性。
其次,Flink 作为一个实时计算引擎,提供了流处理和批处理的能力,能够直接操作数据湖中的数据。Flink 支持各种数据源和数据格式,能够快速地读取和写入数据湖中的数据。同时,Flink 的事件时间处理和状态管理能力,能够保证数据的精确处理和一致性。
另外,Flink 和 Iceberg 在社区中得到了广泛的支持和贡献。Flink 社区提供了丰富的连接器和集成能力,能够支持各种数据源和数据格式。Iceberg 也在社区中获得了广泛的认可,得到了包括 Netflix、DoorDash、Airbnb 等知名公司的支持。社区不断地推动着 Flink 和 Iceberg 的发展,不断完善其功能和性能。
总的来说,Flink 和 Iceberg 作为开源的数据处理和数据管理工具,提供了一种有效的解决方案,用于解决数据入湖相关的挑战。Iceberg 通过其原生支持的数据表格式和元数据管理能力,保证了数据的一致性和查询效率。同时,Flink 作为一个实时计算引擎,能够直接操作数据湖中的数据,实现了数据的实时处理和分析。随着社区的不断发展和完善,相信 Flink 和 Iceberg 将会成为更加强大和灵活的数据入湖解决方案。
Data Lake
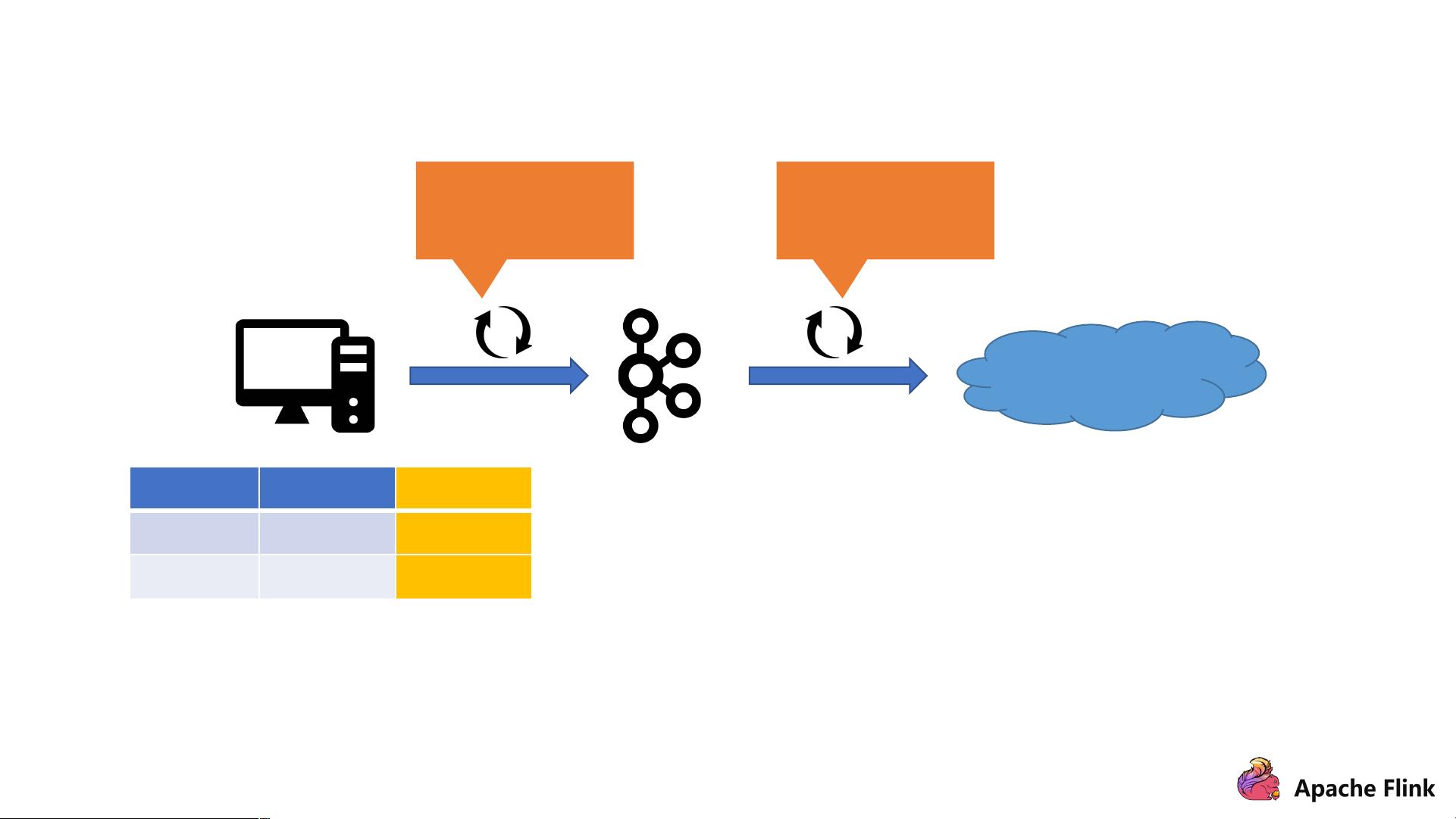
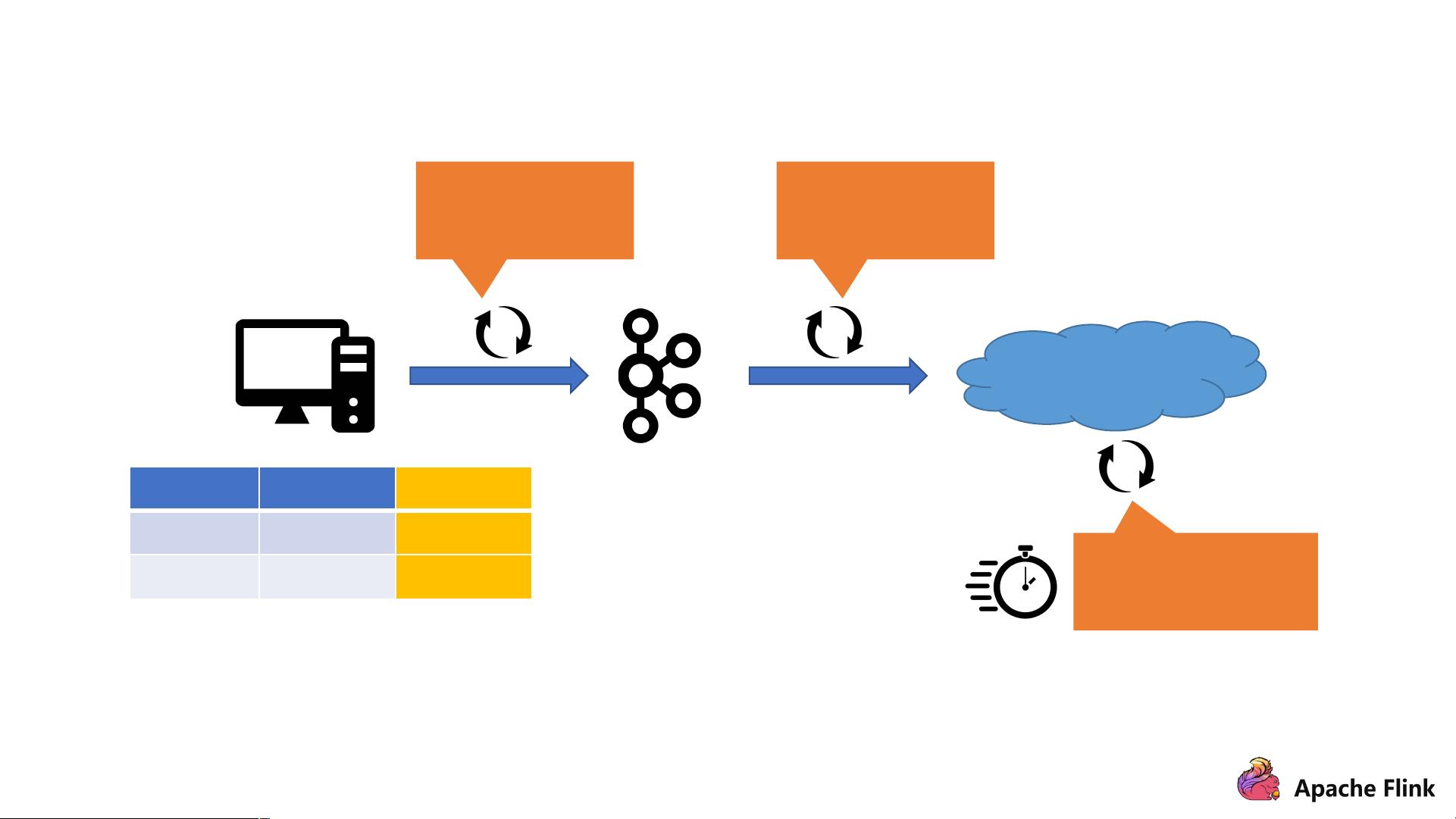
Case #2: 数据变更太痛苦了
ID NAME Address
1001 Alex Beijing
1002 Tom
ShangHai
添加新列,修改
作业并重启。
添加新列,修改
作业并重启。
剩余54页未读,继续阅读
342 浏览量
142 浏览量
268 浏览量
136 浏览量
142 浏览量
342 浏览量

Json_Wang
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







