分布式数据库设计:Top-down与Bottom-up策略
需积分: 20 181 浏览量
更新于2024-07-31
1
收藏 1.28MB PPT 举报
"分布式数据库的设计涉及如何在分布式环境中对数据进行逻辑划分和物理分配。本章节主要探讨了两种设计策略——自顶向下(Top-down)和自底向上(Bottom-up),并详细阐述了数据分片的概念及其应用。"
在分布式数据库系统中,设计的核心是数据的分布策略。数据分片是将数据逻辑上分割成多个部分,这些部分可以分布在不同的节点上。本章主要围绕数据分片展开,以关系数据库为例进行说明。
首先,介绍的是设计策略。自顶向下设计适用于从零开始构建数据库系统,它包括需求分析、概念设计、分布设计、物理设计和性能调优等步骤。这种方法是从全局视角出发,逐步细化到各个局部数据库。而自底向上设计则常用于已有多个独立数据库系统的集成,通过集成现有数据库形成分布式系统。本课程更侧重于自顶向下的设计技术。
接着,详细讲解了数据分片。分片是将数据库中的关系按照特定规则拆分成多个片段,这些片段可以在不同的场地存储。例如,对于一个职工关系表EMP,可以按照地理区域进行水平分片,每个分公司保存自己的员工数据;或者进行垂直分片,根据字段的重要性或访问频率将数据分割。
水平分片通常是根据某个或某些属性值进行划分,所有分片具有相同的属性集合,但每个分片包含不同的行。水平分片的设计要考虑数据的均匀分布和查询效率。
垂直分片则是根据属性进行切割,不同的分片包含关系的不同部分属性。这种设计可以优化访问性能,将频繁一起使用的属性放在同一分片,减少跨节点通信。
分片的表示方法是设计中不可或缺的部分,通常使用分片函数和分片映射来描述数据如何分布。
分配设计则关注数据实际在硬件上的物理位置,要考虑网络延迟、负载均衡和数据冗余等因素。
最后,性能调优是确保分布式数据库高效运行的关键,包括查询优化、数据复制策略和并发控制等。
分布式数据库的设计是一项复杂而重要的任务,需要综合考虑数据的逻辑结构、物理分布、网络环境以及性能需求,以实现高可用性、可扩展性和数据一致性。

§3.2
§3.2
分片的定义
分片的定义
分片设计过程
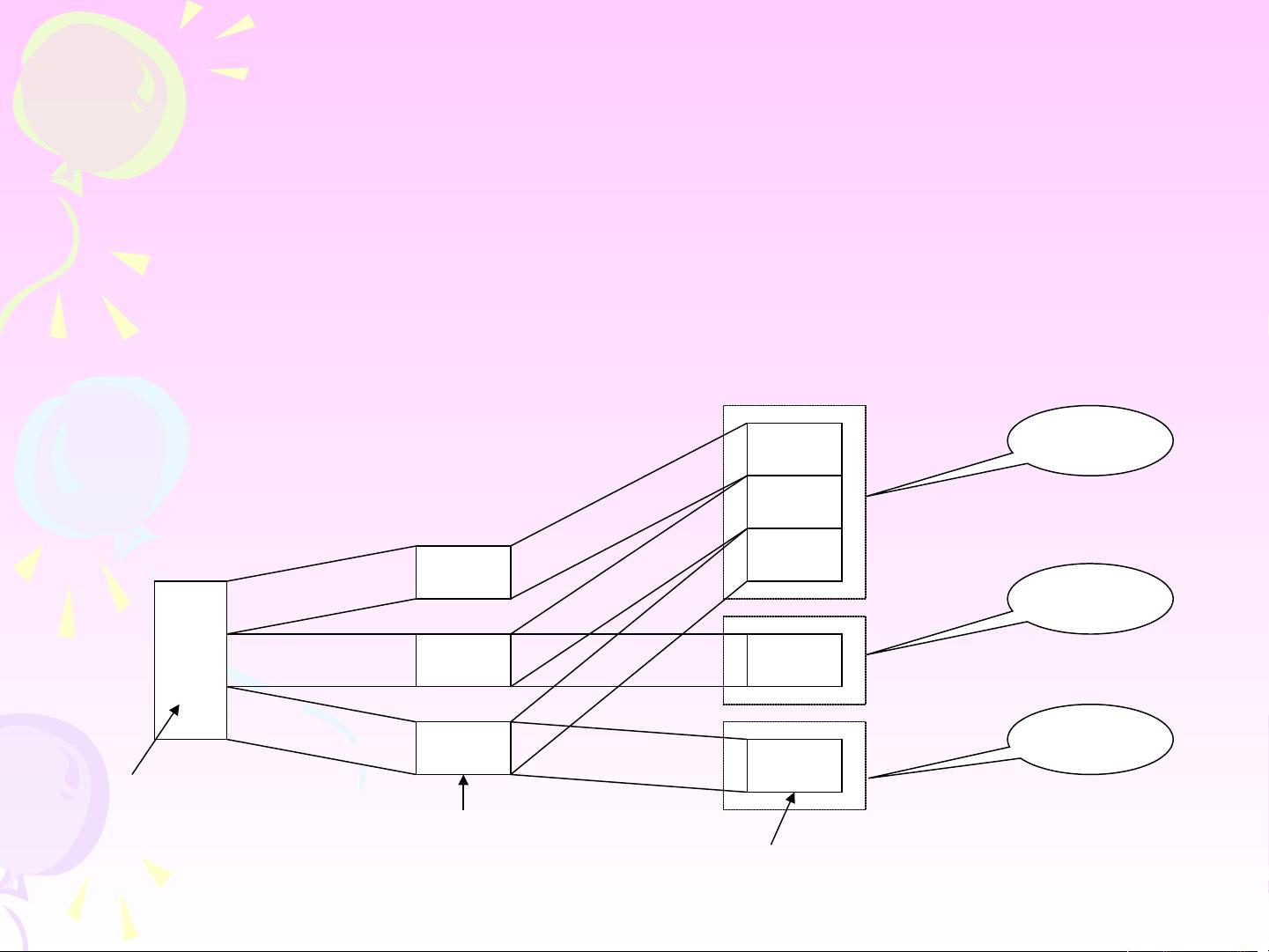
分片过程是将全局数据进行逻辑划分和实际物理分配的过程。
全局数据由分片模式定义分成各个片段数据,各个片段数据
由分配模式定义存储在各场地上。分片过程如图 3.1 所示。
GDB
FDB
PDB
分片模式
分配模式
GDB :全局数据库( G
lobal DB )
FDB :片段数据库( Fr
agmentation DB ) PDB :
物理 数据 库( Physical
DB )

剩余63页未读,继续阅读
2012-11-29 上传
2010-11-17 上传
2010-11-17 上传
2010-12-01 上传
2010-12-01 上传
2023-03-11 上传
2021-10-12 上传
2023-01-08 上传
2019-05-25 上传

creat2008
- 粉丝: 0
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
