Hadoop入门:分布式存储与计算解析
"本文档是对Hadoop的初步学习介绍,涵盖了Hadoop的基本概念、优点以及核心组件HDFS和MapReduce。"
在分布式计算领域,Hadoop是一个不可或缺的名字。它是一个开源的分布式系统基础架构,由Apache基金会开发,允许开发者在不了解分布式系统底层细节的情况下编写分布式程序,从而实现大规模数据的高效处理和存储。Hadoop主要包括两个核心部分:分布式存储系统HDFS(Hadoop Distributed File System)和分布式计算框架MapReduce。
Hadoop的设计理念是可扩展性、经济性和可靠性。它能够轻松地扩展存储容量和计算能力,适应不断增长的数据需求。由于Hadoop能够在普通的PC机上运行,这大大降低了部署成本。通过分布式文件系统的备份恢复机制和MapReduce的任务监控,Hadoop确保了数据处理的高可靠性。
Hadoop系统由Master节点和Slave节点组成。Master节点包含NameNode和JobTracker,负责全局的管理和任务调度。NameNode管理文件系统的命名空间,跟踪文件和目录的位置信息,而DataNode作为Slave节点的一部分,存储实际的数据块并向NameNode发送心跳信息以报告其状态。JobTracker则负责分配和监控作业的执行,TaskTracker在Slave节点上运行,执行由JobTracker分配的Map和Reduce任务。
HDFS是Hadoop的核心存储组件,适合存储超大文件,如几百MB到几百PB的数据。它遵循一次写入、多次读取的原则,优化了数据的批量读取性能,而不追求低延迟访问。HDFS的设计目标是能够在商用硬件上运行,不依赖昂贵的高可用设备。
MapReduce是Hadoop的计算模型,它将复杂的大规模数据处理任务分解为一系列Map任务和Reduce任务,分别在多台机器上并行执行。Map阶段将原始数据拆分成键值对,处理后生成中间结果,Reduce阶段则将这些中间结果进行聚合,最终得到处理后的数据。
Hadoop是应对大数据挑战的重要工具,它的出现使得企业和组织能够以相对较低的成本处理海量数据,挖掘其中的价值。通过深入理解Hadoop的原理和机制,开发者可以构建出高效、可靠的分布式数据处理系统。
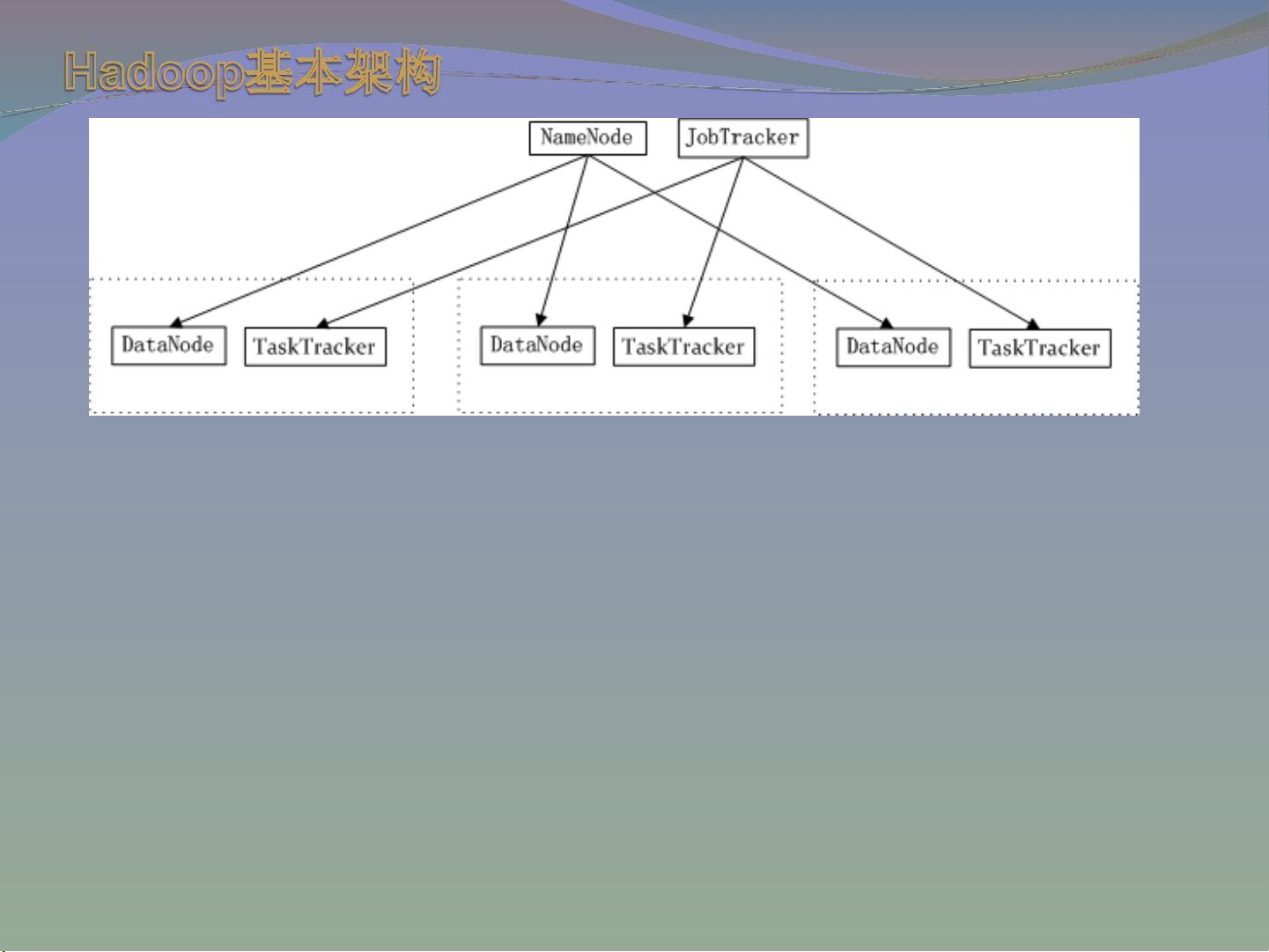
在 Hadoop 的系统中,会有一台 Master ,主要负责
NameNode 的工作以及 JobTracker 的工作。 JobTracker
的主要职责就是启动、跟踪和调度各个 Slave 的任务执行。
还会有多台 Slave ,每一台 Slave 通常具有 DataNode 的功
能并负责 TaskTracker 的工作。 TaskTracker 根据应用要
求来结合本地数据执行 Map 任务以及 Reduce 任务。
名称节点( NameNode ):管理文件系统的命
名空间,记录文件系统树及这个树内所有的文件和
索引目录,同时也记录每个文件的每个块,所在的
数据节点。
数据节点( DataNode ):文件系统的工作者,
存储并提供定位块的服务,并定时向名称节点发送
块的存储列表
JobTracker :协调作业的运行。
TaskTracker :运行作业划分后的任务。
剩余29页未读,继续阅读
2019-02-25 上传
2020-02-18 上传
2013-02-21 上传
2018-09-29 上传
2018-06-27 上传
2012-01-09 上传
2012-08-19 上传

schaha_2015
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







