华为机器学习发展历程:从内部应用到行业通用
需积分: 1 163 浏览量
更新于2024-07-18
收藏 1.7MB PDF 举报
"探索数据的奥义"这篇文章主要聚焦于华为公司在机器学习领域的进展及其在行业内的重要应用。自2011年起,华为逐渐涉足并发展机器学习技术,经历了几个关键阶段,从最初的单机内部应用,如网络故障检测和客户服务优化,到后来采用Python、R等语言和Spark等工具,实现更深层次的数据处理和分析。
在机器学习类型方面,文章将机器学习分为监督学习和无监督学习两大类。监督学习是通过训练数据集进行模式学习,包括常见的分类任务,如用户画像和车辆识别,以及回归任务,如网络质量分析和话务量预测。在这个过程中,数据集包含明确的输入和输出标签,即特征和结果,以帮助模型学习预测规律。
无监督学习则是面对没有明确标签的数据,如聚类和异常检测,它用于发现数据内在结构和潜在模式,如仓储规划和货量预测。华为利用这一技术改进了仓储管理、路径规划等业务流程。
此外,文章还提及了机器学习云服务(MLS),即服务化和弹性伸缩的解决方案,使得华为的机器学习能力不仅服务于内部各业务部门,如终端云、GTS人工智能等,也扩展到了外部客户,涵盖金融、物流、医疗等多个行业。这些外部客户可以通过华为的公有云机器学习服务,解决如金融欺诈检测、智能交通管理等实际业务问题。
这篇文章揭示了华为在机器学习领域的专业实践,从技术发展、应用场景到服务模式,全面展示了机器学习如何帮助企业提升效率,解决复杂问题,并推动行业的数字化转型。同时,它也强调了监督学习和无监督学习作为基础技术的重要性,以及数据驱动的决策在当今商业环境中的核心价值。
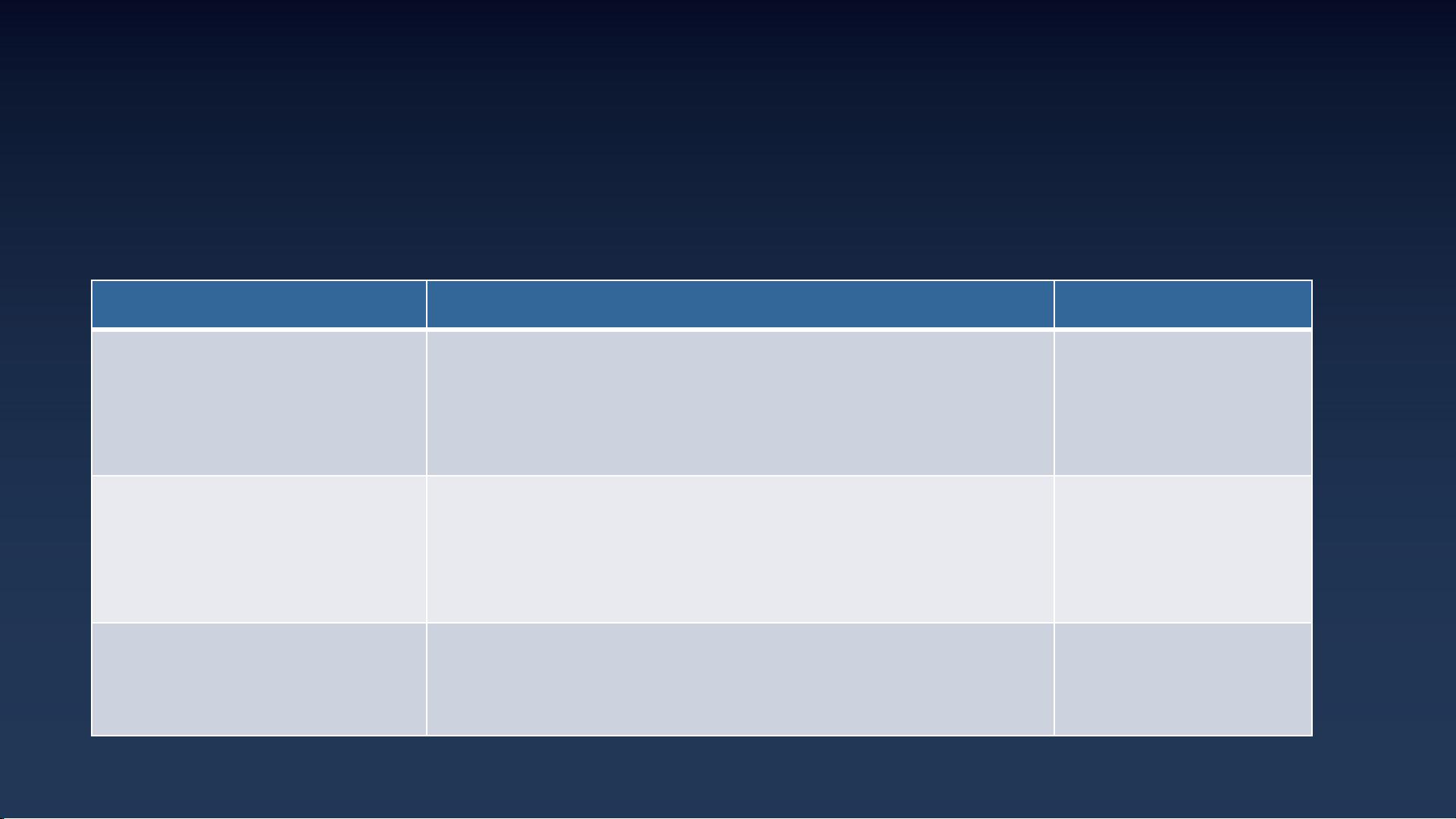
行业通用的机器学习类型
按学习方式分为三大类
说明
解决问题
监督学习
Supervised
learning
从给定的训练数据集(历史数据)中
学习出一个函数,
当新的数据到来时,可以根据这个函数预测结果。监督
学习的训练集需要包括输入和输出,也可以说是特征和
目标
/Label。训练集中的目标是由人标注的。
分类
回归
无监督学习
Unsupervised learning
与监督学习相比,输入的数据
没有人为标注的结果,模
型需要对数据的结构和数值进行归纳。比如根据用户的
基本信息把所有用户划分为不同的用户群,再对不同人
群采取不同的销售策略
聚类(分群)
强化学习
Reinforcement learning
输入数据可以刺激模型并且使模型做出反应。
反馈不仅
从监督学习的学习过程中得到,还从环境中的奖励或惩
罚中得到。
机器人
Alpha GO
剩余16页未读,继续阅读
2010-12-28 上传
2010-10-27 上传
2022-11-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情


CodingPioneer
- 粉丝: 1w+
- 资源: 131
 我的内容管理
展开
我的内容管理
展开







最新资源
- 后端
- pyalgs:软件包pyalgs使用Python在Robert Sedgwick的算法中实现算法
- gDoomsday-开源
- maximize-all-windows:Firefox插件,用于最大化所有浏览器窗口
- PHPCMS的企业黄页模块(技术宅社区修改版) v20130628
- InspectIcon.r7s2c1z9ui.gaSVxHJ
- 简单线性回归
- Mopidy是用Python编写的可扩展音乐服务器-Python开发
- 参考资料-基于RTL8019AS的单片机TCPIP网络通信.zip
- dag:DAG实施中
- Script Menu-crx插件
- HackBulgariaJavaCourseApplication:哈克保加利亚Java课程应用程序的任务
- 适用于Python程序的采样探查器-Python开发
- 参考资料-基于rs485总线的智能家居系统.zip
- 各个版本的oracle dataaccess
- milestone-project-02:这是一个使用HTML 5,CSS和JS创建的旅行网站,我必须在其中添加Google API,Sky Scanner API和电子邮件
