YOLOv8图像识别实战:从入门到精通
 已收录资源合集
已收录资源合集
需积分: 0 163 浏览量
更新于2024-06-18
3
收藏 15.03MB PDF 举报
"YOLOv8是实时目标检测算法,注重高效与准确性,适用于人脸检测、车辆识别等场景。在毕业设计中,基于YOLOv8的图像处理和识别项目有挑战性和应用前景。数据标记是训练YOLOv8的关键步骤,可以通过网站下载或使用CVAT自定义数据集。"
YOLOv8是深度学习领域中的一个重要目标检测模型,全称为You Only Look Once的第八个版本。它的核心特点在于通过单次前向传播预测图像中的边界框和类别概率,实现了高效的实时目标检测。相比传统的检测算法,YOLOv8不仅保持了高精度,还显著提升了处理速度,使得它在实时图像处理应用中备受青睐。
在图像处理和识别领域,YOLOv8利用卷积神经网络对图像进行网格划分,每个网格单元负责预测其内部可能存在的目标。这样的设计使得模型能快速识别多个目标,适应复杂场景。此外,YOLOv8还采用了先进的数据增强技术和多尺度训练策略,增强了模型对不同环境和条件下的适应能力,确保在实际应用中的稳定性和泛化性能。
对于大学生的毕业设计,选择基于YOLOv8的项目具有很高的价值。这不仅可以锻炼学生的实践能力,还能让他们了解并掌握前沿的计算机视觉技术。例如,可以将YOLOv8应用到交通监控中,实现车辆识别,或者在智能家居系统中实现物体识别,提升系统的智能化水平。
数据标记是训练YOLOv8的第一步,通常有两种方法:一是从公开数据集如OpenImages获取已经标记好的数据;二是使用工具如CVAT自定义数据集并进行手动标记。CVAT提供了一个方便的平台,用户可以上传自己的图片,创建项目,添加标签,然后对每张图片进行细致的注释。在CVAT中,用户可以选择合适的标签对图像的不同部分进行标记,完成注释后,保存并准备用于模型训练。
YOLOv8作为一款强大的图像处理工具,对于学习者和开发者来说,提供了丰富的实践机会和创新空间。通过理解和掌握YOLOv8的工作原理,以及如何准备和标记数据,可以进一步提升在机器学习和计算机视觉领域的专业技能。
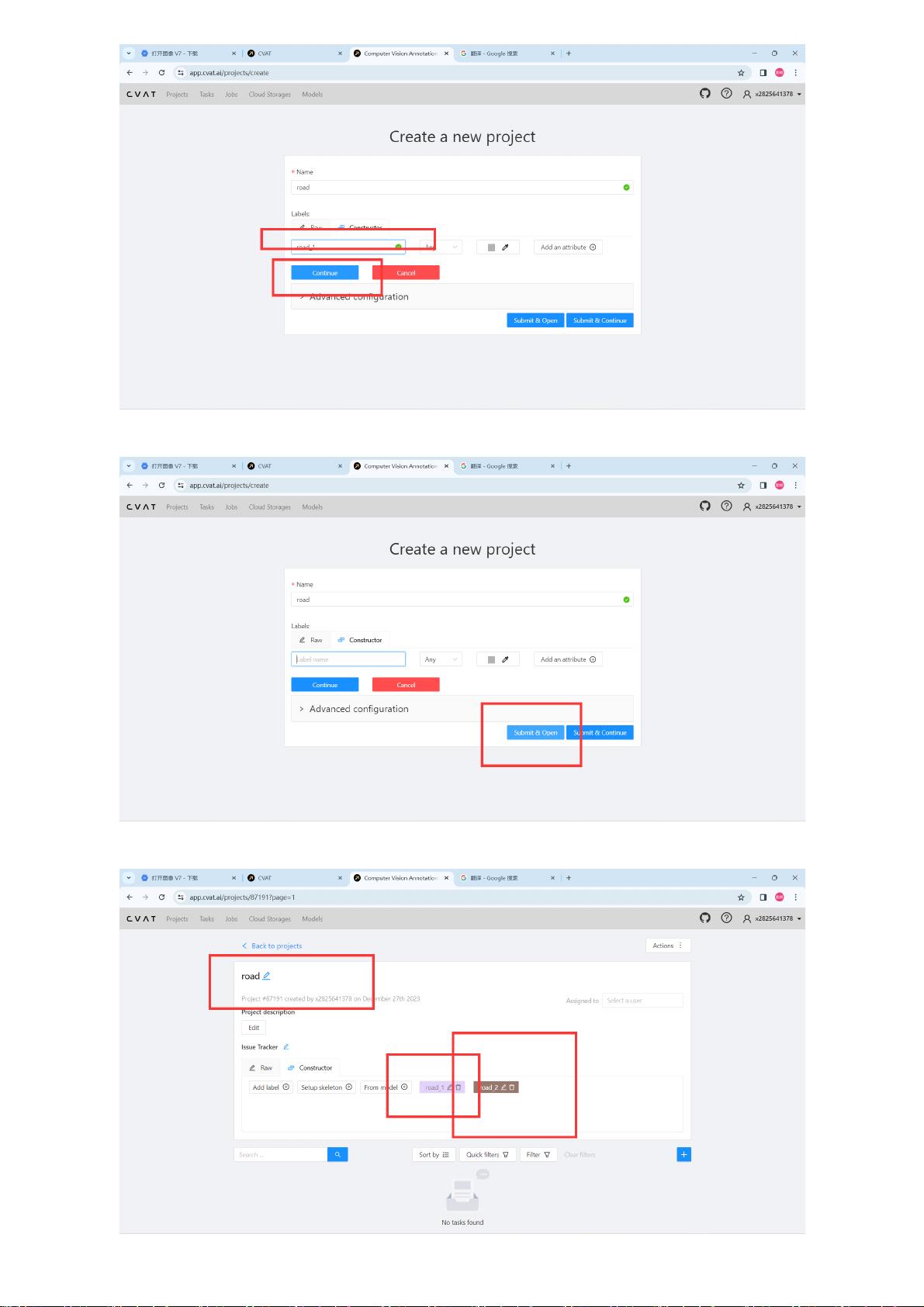
点击submit&open选择保存项目数据集
完成之后可以看到数据集的名称,以及标记的名称和数量
剩余15页未读,继续阅读
397 浏览量
155 浏览量
212 浏览量
140 浏览量
2023-03-29 上传
169 浏览量
164 浏览量
2024-12-06 上传
276 浏览量

笛秋白
- 粉丝: 1922
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 关于路由器技术的基础l理论知识
- Intel 80x86 CPU系列介绍
- CPU 和GPU设计工作原理
- 理解VMware的3种网络模型
- Master Dojo
- pragmatic.programming.erlang.jul.2007.pdf
- java面试题集 pdf格式
- 计算机数字电路中的 组合逻辑电路。设计。方法。答案。。。。。。。。。
- RJ232描述,描述计算机串口通信的基础知识,也包含了一些例程
- 全国计算机四级考试笔试模拟试题2
- MAC地址的原理分析以及相关应用介绍
- vista下MySQL的安装
- java线程与并行(主要讲解java的nio包某些内容)
- ErlangProgramming.pdf
- PKI技术及应用开发指南
- Apress.Pro.EJB.3.Java.Persistence.API.
