DTLBO算法:解决现实Flowshop调度问题
9 浏览量
更新于2024-08-26
收藏 1.1MB PDF 举报
"离散的基于学习的优化算法,用于现实的Flowshop调度问题"
这篇研究论文探讨了在现实工业环境中解决Flowshop调度问题的一种离散教学-学习优化算法(DTLBO)。Flowshop问题是一个经典的优化问题,尤其在多工序生产环境中,涉及到如何有效地安排一系列作业在多台机器上按顺序加工,以达到某些特定的目标,如最小化最大完成时间或提高生产效率。
论文中,作者考虑了五种可能的中断事件,这些事件在实际生产过程中经常发生:
1. 机器故障:机器的意外停机可能导致整个生产流程的中断。
2. 新工作到达:新的生产任务可能需要被及时地纳入现有的调度计划中。
3. 作业取消:由于客户需求变化或其他原因,一些已计划的作业可能需要被取消。
4. 作业处理变异:加工时间的变化可能会影响生产节奏和效率。
5. 作业发布变异:作业的起始时间发生变化,可能会影响到后续作业的安排。
DTLBO算法设计的目标是同时最小化两个主要的优化目标:
1. 最大完成时间(Makespan):这是衡量所有作业完成时间中最长的时间,直接影响到生产周期和客户等待时间。
2. 不稳定性(Instability):指调度计划的频繁变动,这会导致生产效率降低和资源浪费。
该算法借鉴了教学-学习的概念,模拟教师引导学生学习的过程。在优化过程中,"教师"个体指导"学生"个体的学习过程,通过信息交换和策略调整,逐步改进解决方案的质量。离散化的设计使得DTLBO能够适应Flowshop问题中的离散决策变量,如作业顺序和机器分配。
文章详细介绍了算法的步骤,包括初始化、教学阶段、学习阶段以及适应度函数的设计等。通过与其他优化算法的对比实验,展示了DTLBO在应对各种中断事件和多目标优化方面的优势和有效性。
这篇研究论文提出了一种新颖的离散教学-学习优化算法,用于解决Flowshop调度问题中的复杂性和实时性挑战,对于提升制造业的生产效率和灵活性具有重要的理论与实践价值。
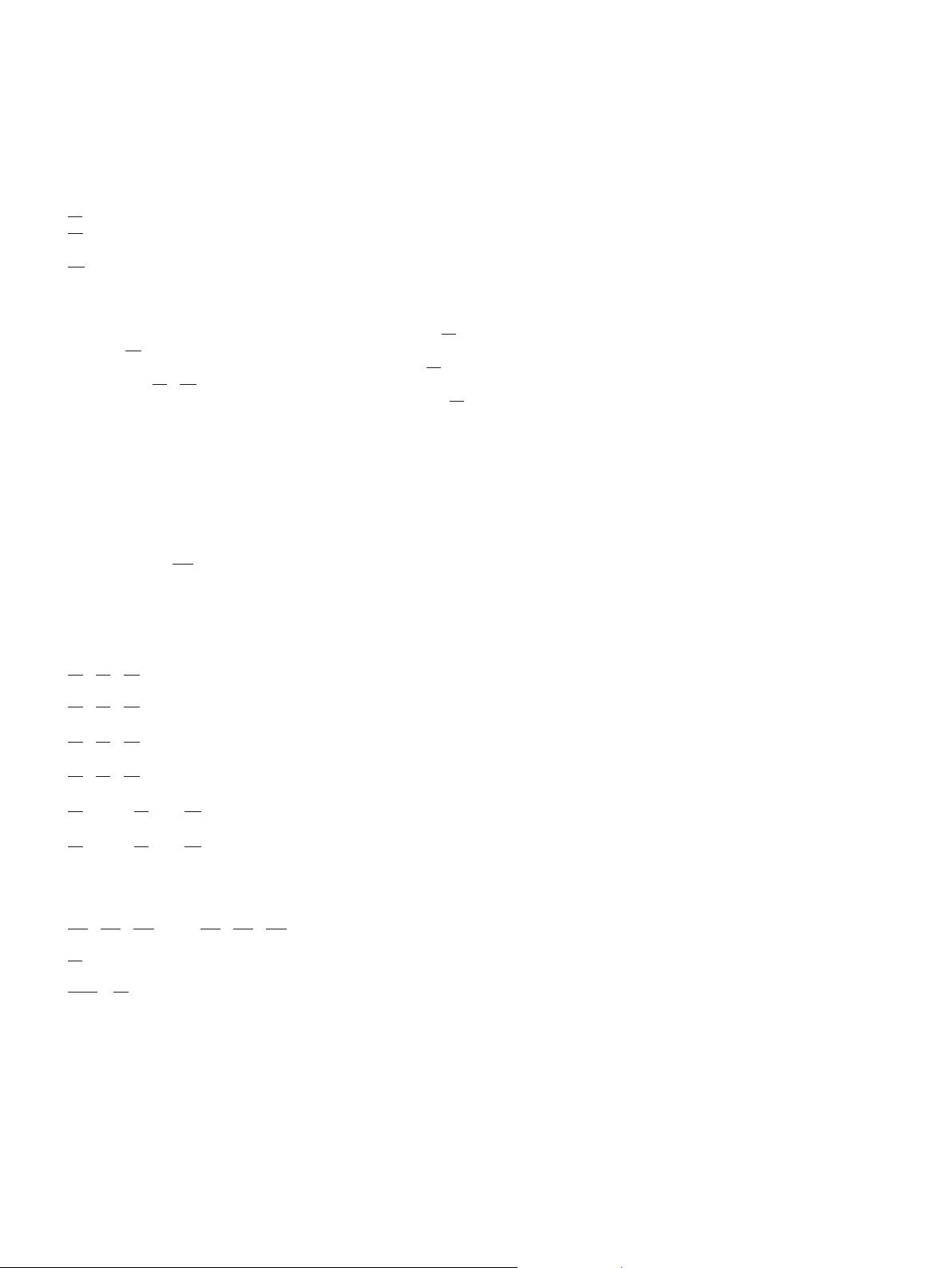
B
j
e
The recovery time point of the machine breakdown
disruption on machine j.
w
1
The penalty coefficient.
M Sufficiently large constant.
Decision variables
s
i;j
The starting time of operation O
ij
in the new schedule.
c
i;j
The completion time of operation O
ij
in the new
schedule.
p
i;j
The processing time of operation O
ij
in the new schedule.
x
ij
A 0/1 variable that is equal to one if and only if operation
O
ij
has a different starting time in the on-going and new
schedules.
y
i;j;1
A 0/1 variable that is equal to one if and only if s
i;j
þ
p
i;j
r B
j
s
.
y
i;j;2
A 0/1 variable that is equal to one if and only if s
i;j
o B
j
s
and s
i;j
þp
i;j
4 B
j
s
.
y
i;j;3
A 0/1 variable that is equal to one if and only if B
j
s
r s
i;j
.
2.2. Mathematical model
With the variables defined above, the mathematical model for
the flowshop rescheduling problem is given as follows:
f ¼ w
1
n
f
1
þð1 w
1
Þ
n
f
2
ð1Þ
f
1
¼ min max
1 r i r n
c
i;m
ð2Þ
f
2
¼ min
∑
n
i ¼ 1
∑
m
j ¼ 1
x
ij
()
ð3Þ
s.t.
c
i;j
s
i;j
p
i;j
þð1 y
i;j;1
ÞM Z 0 ð4Þ
c
i;j
s
i;j
p
i;j
ð1 y
i;j;1
ÞM r 0 ð5Þ
c
i;j
s
i;j
p
i;j
B
j
e
þB
j
s
þð1y
i;j;2
ÞM Z 0 ð6Þ
c
i;j
s
i;j
p
i;j
B
j
e
þB
j
s
ð1y
i;j;2
ÞM r 0 ð7Þ
c
i;j
max fs
i;j
; B
j
e
gp
i;j
þð1y
i;j;3
ÞM Z 0 ð8Þ
c
i;j
max fs
i;j
; B
j
e
gp
i;j
ð1y
i;j;3
ÞM r 0 ð9Þ
∑
3
k ¼ 1
y
i;j;k
¼ 1; iA f1; 2; …; ng; jA f 1; 2; …; mg; kA f1; 2; 3gð10Þ
c
i
1
;j
c
i
2
;j
p
i
1
;j
Z 0orc
i
2
;j
c
i
1
;j
p
i
2
;j
Z 0; 8i
1
a i
2
ð11Þ
s
i;j
Z r
i;j
; i A f1; 2; …; ng; jA f1; 2; …; mgð12Þ
s
i þ 1;j
Z c
i;j
; i A f1; 2; …; n 1g; j A f1; 2; …; mgð13Þ
x
ij
¼ 0; 1fg; i A f1; 2; …; ng; jA f1; 2; …; mgð14Þ
y
ijk
¼ 0; 1fg; iA f1; 2; …; ng; jA f1; 2; …; mg; kA f1; 2; 3gð15Þ
In this mathematical model, the total weight ed objective and the
makespan objective are given in Eqs. (1) and (2), respectiv ely. Eq. (3)
illustrate s the second objective of the problem, i.e., the instability
objective, which is used to minimise the number of tasks whose
starting times have been altered in the new schedule. Thr ee situa-
tions under the machine breakdown disruption are guarant eed by
Constraint s (4) to (9).Thefir st situation that is guar ant eed by
Constraints (4) and (5) is for the operations that hav e completed
their tasks before the machine breakdown. Constraints (6) and (7)
guarant ee the second situa tion, which is for the operations that
over lap with the machine breakdo wn, while Constr aints (8) and (9)
guarantee the third situation, in which the operations begin their
work after the machine breakdown disruption. Constraint (10) shows
that only one case can occur in the problem that is under study.
Constraint (11) shows that multiple jobs canno t be pr ocessed on the
same machine at the same time. Constraint (12) implies that a job
cannot be started until its release event occurs. In Constraint (13),the
operation sequence is realised for the same job; in other wor ds, the
following operation cannot be started until the completion of the
predecessor operation of the same job. Constraints (1 4) and (1 5)
define the value ranges for the decision variables.
3. The canonical TLBO
TLBO mimics the learning process of a teacher and a population
of learners. In the canonical TLBO, several learners construct a
population of activities. The best learner of the current population
is selected as the teacher. All of the learners will perform two
evolving phases, i.e., the teaching phase and the learning phase.
3.1. Teaching phase
In the canonical TLBO, the first part of the algorithm is
the teaching phase, where the learners learn through the teacher
by using the difference between the teacher and the mean result
of the current population. In a problem with n dimension, at
any iteration t, let X
i
t
(i¼ 1,2,…,m) be the ith learner in the
population, let M
t;j
be the mean result of the learners in a
particular subject j (j¼1,2,…,n), and let X
b
t
be the best learner in
the current population, which is also selected as the current
teacher. The detailed implementation of the teaching phase is
given as follows:
Step 1. Compute the difference D
t;j
Let D
t;j
be the difference between the teacher X
b
t
and the mean
result M
t;j
. Formula (16) gives the computation process of D
t;j
.
D
t;j
¼ r
t
ðX
b
t;j
T
F
M
t;j
Þð16Þ
where X
b
t;j
is the result of the teacher in subject j, r
t
is a random
number in the range [0, 1], and T
F
is the teaching factor that decides
thevalueofthemeantobechanged.ThevalueofT
F
can be either
1 or 2, which is again a heuristic step and is decided randomly with
equal probability (Rao et al., 20 1 2).
Step 2. Generate a new learner
Learner X
i
t
updates its state in subject j by combining the
difference D
t;j
and its current state:
X
i
'
t;j
¼ X
i
t;j
þD
t;j
ð17Þ
where X
i
'
t;j
is the updated value of the current i
th
learner X
i
t
in
subject j.
Step 3. If X
i
'
t
is better than X
i
t
, then replace the latter by the
new value.
3.2. Learning phase
In the learning phase, several learners evolve through learning
from each other. The main steps of the learning phase are as follows:
Step 1. For the learner X
i
t
, randomly select another learner X
k
t
.
Step 2. If X
i
t
is better than X
k
t
, then let
X
i
'
t
¼ X
i
t
þr
i
ðX
i
t
X
k
t
Þð18Þ
J.-q. Li et al. / Engineering Applications of Artificial Intelligence 37 (2015) 279–292 281
剩余13页未读,继续阅读
2022-08-04 上传
2021-09-29 上传
2021-03-14 上传
2021-03-10 上传
132 浏览量
126 浏览量
203 浏览量
132 浏览量
点击了解资源详情

weixin_38705723
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
