1-Pass与2-Pass语音识别引擎性能对比:速度与精度的抉择
需积分: 12 60 浏览量
更新于2024-09-08
收藏 609KB PDF 举报
本文主要探讨了两种不同的语音识别引擎策略:1-Pass(单次搜索)和2-Pass(两次搜索)在NCMMSC2015中国天津会议上关于ULVCSR(超大规模词汇量连续语音识别)的性能比较。1-Pass引擎以其快速的识别速度和多线程云计算的优势,在商业应用中展现出吸引力,特别是在处理实时性和并发性要求高的场景。它通常采用高效的算法,如深度神经网络(DNN)、递归神经网络(RNN)和卷积神经网络(CNN),这些技术极大地提升了识别准确度,降低了30%-50%的误识率。
相比之下,2-Pass引擎是更为常见的选择,它分为两个阶段:首先利用低阶语言模型,如三元文法,进行初步筛选,然后结合声学模型和高级语言模型(如4/5元ARPA语言模型)进行二次评分和综合评估,形成词图(Lattice)。这种方法在词汇量庞大的情况下表现出较高的识别率,但可能会牺牲一定的速度。2-Pass引擎适合对准确性和词汇覆盖率有较高要求的场景,例如专业语音识别系统或大型语料库处理。
随着移动互联网的发展和云计算的成熟,语音识别技术在商业应用中的角色日益重要。在移动设备上,1-Pass引擎可能更适合于实时性强、交互频繁的场景,而2-Pass引擎则适用于那些对识别质量要求严苛、词典庞大或者需要深度语言理解的场景。无论是哪种策略,技术的进步,尤其是神经网络在声学模型和语言模型中的应用,都显著推动了语音识别技术的性能提升和商业化应用的普及。
NCMMSC2015 中国天津 2015 年 10 月
1-PASS 与 2-PASS 识别引擎性能评测与分析
贺勇,朱会峰,雍坤,丁沛,郝杰
东芝(中国)有限公司 研究开发中心,北京 100600 中国
文 摘: 超大规模词汇量连续语音识别(ULVCSR)在近几年性能大幅提升,并且在商业领域的应用越发广泛,其
核心引擎可分为 1-Pass 和 2-Pass 两大类型。本文对上述两种识别引擎进行了全面的性能评测。实验结果表明,2-Pass
引擎有较高的识别率,而 1-Pass 引擎识别速度很快,且易于实现多线程云计算模式,更适合于当今的主流商业用途。
关键词:语音识别;识别引擎;识别性能;
中图分类号: TN912.34
随着 3G/4G 无线网络的普及,智能移动终端数
量激增,大量信息交互由个人计算机转向移动设
备。传统的键盘操作在移动设备上有诸多不便,人
们迫切需要一种便捷的方式实现人与机器的自然
交互,语音识别正是符合这种需求的技术。同时,
云计算服务日臻完善,让语音识别技术在实际应用
中也有了颠覆性的变化,当前多采用本地获取语音
而在云端进行识别的方式。不同于以往的嵌入式终
端系统,这种模式下云端可以采用更复杂的算法以
及更大规模的模型。在技术研究方面,神经网络
(NN)的应用让语音识别性能有了革命性的飞跃,
在声学模型(AM)领域使用的 NN 包括深度神经
网络(DNN)
[1][2]
,递归神经网络(RNN)
[3][4]
以及
卷积神经网络(CNN)
[5]
,对识别性能的改善实现
了 30%-50%的误识率降低。同时,语音识别进入了
ULVCSR时代,系统词典的规模扩展到一万词以上,
同时使用了更高阶(4/5 元)的 ARPA 语言模型(LM)
[6]
,极大地提高了识别精度。声学模型和语言模型
的改进使得语音识别性能大幅度提高,进一步提高
了商业使用的可靠性。
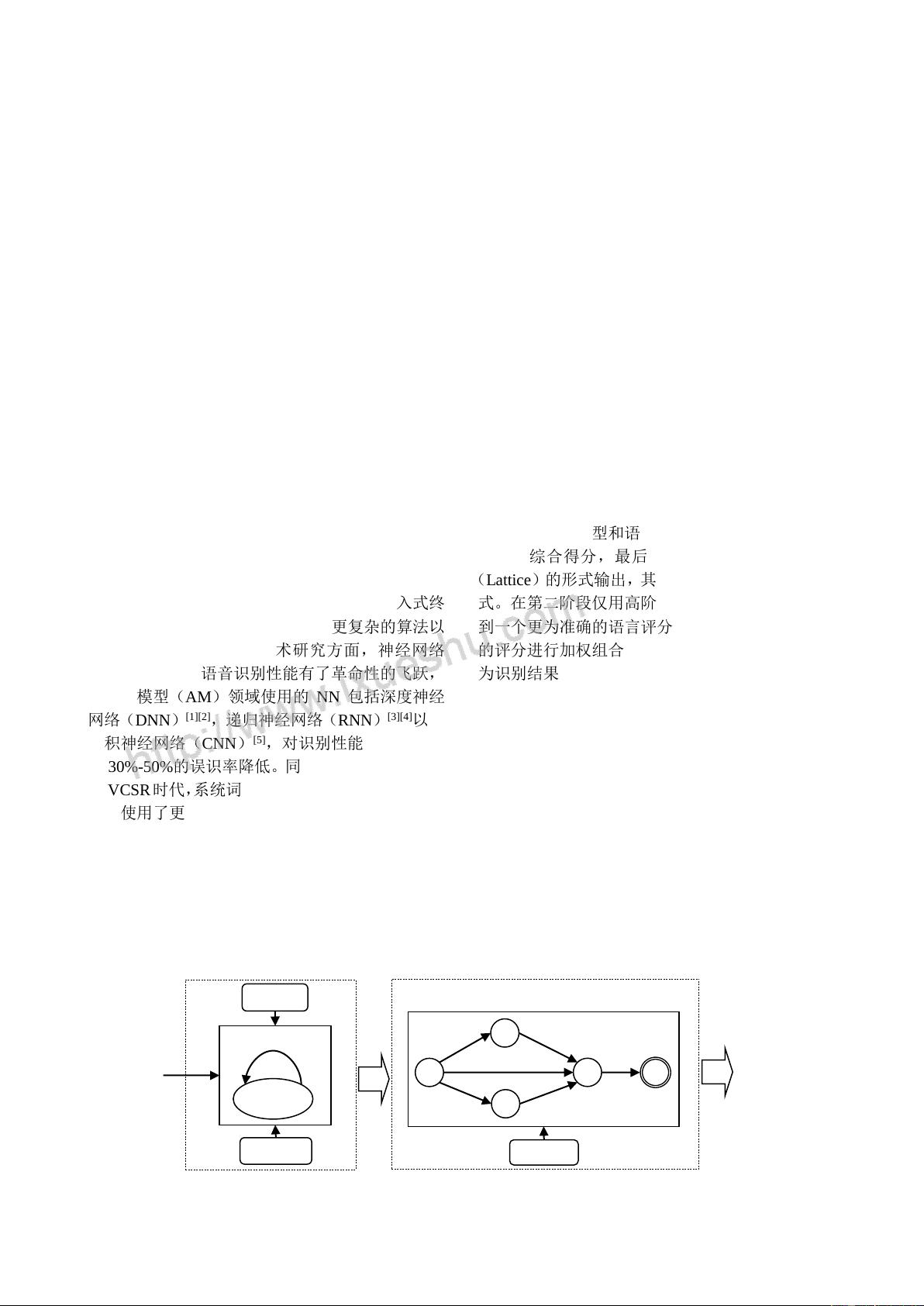
语音识别引擎根据搜索策略可分为 1-Pass(一
遍搜索)和 2-Pass(两遍搜索)
[7]
。2-Pass 是最常
采用的识别引擎,识别过程可以分为两个阶段。由
于搜索空间是由词表(Lexicon)的自由组合而成,
所以词汇量很大时,高阶语言模型构成的搜索空间
巨大,无法直接进行搜索。因此 2-Pass 中第一阶段
使用低阶语言模型进行识别,一般常用三元文法,
识别时用声学模型和语言模型分别进行打分,然后
组合成综合得分,最后将得分较高的结果以词图
(Lattice)的形式输出,其 为多种识别结果组合的模
式。在第二阶段仅用高阶语言模型(如用 4 元)得
到一个更为准确的语言评分,用该评分与第一阶段
的评分进行加权组合,最后给出得分最高的路径作
为识别结果。
近几年出现了 1-Pass 识别技术,其中最具代表
性的是加权有限状态转换器(WFST)引擎
[8]
。1-Pass
是离线的将词表与高阶语言模型预先展开成带有
语言模型得分的识别网络,在进行识别时该网络被
调入内存,识别过程中会沿着该网络进行搜索,并
将声学模型得分和语言模型得分进行相加,最后选
出得分最高的路径作为识别结果。展开成识别网络
图的过程相当于将高阶语言模型应用于 2-Pass 的第
一阶段识别,但是由于计算量太大,故采用了离线
的形式。识别时将展开的结果以识别网络图的形式
调入内存,实质上是一种以大存储换取计算速度的
做法。
图 1 2-Pass 引擎流程
Lexicon
Speech
1-stage
AM
3-gram LM
这
这是
猴
这时候
事后
4-gram LM
词图
2-stage
识别结果
在线展开
0
3
4
2
1
下载后可阅读完整内容,剩余5页未读,立即下载
664 浏览量
2012-02-24 上传
2024-09-28 上传
2024-09-15 上传
2024-10-09 上传
2024-09-24 上传
2024-10-01 上传
2024-09-10 上传
2024-09-23 上传

audiocool
- 粉丝: 323
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高效办公必备:可易文件夹批量生成器
- 吉林大学图形学与人机交互课程作业解析
- 8086与8255打造简易乒乓球游戏机教程
- Win10下C++开发工具包:Bongo Cat Mver、GLEW、GLFW
- Bootstrap前端开发:六页果蔬展示页面
- MacOS兼容版VSCode 1.85.1:最后支持10.13.x版本
- 掌握cpp2uml工具及其使用方法指南
- C51单片机星形流水灯设计与Proteus仿真教程
- 深度远程启动管理器使用教程与工具包
- SAAS云建站平台,一台服务器支持数万独立网站
- Java开发的博客API系统:完整功能与接口文档
- 掌握SecureCRT:打造高效SSH超级终端
- JAVA飞机大战游戏实现与源码分享
- SSM框架开发的在线考试系统设计与实现
- MEMS捷联惯导解算与MATLAB仿真指南
- Java实现的学生考试系统开发实战教程
