提升图像检索精度的层次多维VLAD方法
68 浏览量
更新于2024-08-30
收藏 779KB PDF 举报
本文主要探讨了一种名为"HierarchicalMulti-VLAD"的新型图像检索方法,针对有效图像检索中构建区分度高的特征描述器这一关键问题。Vector of Locally Aggregated Descriptors (VLAD) 是当前最先进的全局描述符,它通过将局部特征(如SIFT)进行量化,用一个视觉词汇(通常为64到512个聚类中心)进行编码,然后对每个聚类中心的量化特征残差求和并拼接成一个全局向量。这种描述符方法在提高搜索精度方面表现出色,但随着词汇表规模的增大(从几百到几万),计算成本也随之显著增加,尤其在采用平面量化时。
HierarchicalMulti-VLAD旨在解决这个问题,提出了一种层次化的策略。它通过将原始的扁平量化过程分解为多级层次,每一级使用较小的词汇表进行局部处理,然后再逐步合并。这样做的好处在于能够保持较高的搜索精度,同时降低计算复杂度。具体来说,该方法可能包含以下几个关键步骤:
1. **分层结构**:将原始图像划分为多个区域或层次,每个层次使用一个相对较小的视觉词汇进行局部特征量化。
2. **局部VLAD**:对每个子区域或层次应用传统的VLAD方法,生成各自的特征向量。
3. **层次融合**:将每个层次的VLAD向量逐级合并,可能是通过加权平均或者深度学习模型(如卷积神经网络)进行特征融合。
4. **计算效率**:由于减少了每个层次的词汇表大小,整体计算需求明显减少,提高了实时性。
5. **性能提升**:通过层次结构,HierarchicalMulti-VLAD能够在保持一定程度的描述符精确度的同时,优化了内存和计算资源的使用。
作者Yitong Wang、Ling-Yu Duan、Jie Lin和Zhe Wang等人来自北京大学和上海合作创新中心,以及新加坡信息通信研究院,他们共同研究并提出了这项创新的图像检索技术。他们的研究邮件地址供读者进一步交流和联系。
总结来说,HierarchicalMulti-VLAD是一种具有高效性和准确性结合的图像检索方法,对于需要在大规模数据和实时性之间找到平衡的场景具有实用价值。未来的研究可能围绕如何进一步优化层次划分策略、改进融合机制,以及探索与其他深度学习架构的集成来提升性能。
HIERARCHICAL MULTI-VLAD FOR IMAGE RETRIEVAL
Yitong Wang
⋆ †
, Ling-Yu Duan
⋆ †∗
, Jie Lin
‡
, Zhe Wang
⋆ †
, Tiejun Huang
⋆ †
⋆
Institute of Digital Media, School of EE&CS, Peking University, Beijing, China
†
Cooperative Medianet Innovation Center, Shanghai, China
‡
Institute for Infocomm Research, Singapore
e-mail:
⋆ †
{wangyitong, lingyu, zwang, tjhuang}@pku.edu.cn,
‡
lin-j@i2r.a-star.edu.sg
ABSTRACT
Constructing discriminative feature descriptors is crucial towards ef-
fective image retrieval. The state-of-the-art powerful global descrip-
tor for this purpose is Vector of Locally Aggregated Descriptors
(VLAD). Given a set of local features (say, SIFT) extracted from
an image, the VLAD is generated by quantizing local features with a
small visual vocabulary (64 to 512 centroids), aggregating the resid-
ual statistics of quantized features for each centroid and concate-
nating the aggregated residual vectors from each centroid. One can
increase the search accuracy by increasing the size of vocabulary
(from hundreds to hundreds of thousands), which, however, it lead-
s to heavy computation cost with flat quantization. In this paper,
we propose a hierarchical multi-VLAD to seek the tradeoff between
descriptor discriminability and computation complexity. We build
up a tree-structured hierarchical quantization (TSHQ) to accelerate
the VLAD computation with a large vocabulary. As quantization
error may propagate from root to leaf node (centroid) with TSHQ,
we introduce multi-VLAD, which constructing a VLAD descriptor
for each level of the vocabulary tree, so as to compensate for the
quantization error at that level. Extensive evaluation over benchmark
datasets has shown that the proposed approach outperforms state-of-
the-art in terms of retrieval accuracy, fast extraction, as well as light
memory cost.
Index Terms— Image Retrieval, Hierarchical Quantization,
Multi-VLAD
1. INTRODUCTION
Image retrieval regards the discovery of images contained within a
large database that depict the same objects/scenes as those depicted
by query images. In general, state-of-the-art image search systems
are built upon a visual vocabulary with an inverted indexing struc-
ture, which quantizes local features (e.g., SIFT [1] or SURF [2]) of
query and database images into centroids. Each database image is
then represented as a Bag-of-Words (BoW) histogram [3] and is in-
vert indexed by quantized centroids of local features in the image.
Recently, the Vector of Locally Aggregated Descriptors (VLAD)
[4][5] and Fisher vectors [6] have extended the BoW by aggregat-
ing higher-order statistics of the distribution of local features. The
VLAD is generated by quantizing the set of local features with a
small vocabulary (64 to 512 centroids), aggregating the residual s-
tatistics of features quantized to each centroid and concatenating the
residual vector from each centroid. Compared to the BoW with a
large vocabulary (e.g., 1 million centroids), the VLAD have achieved
∗
Corresponding author
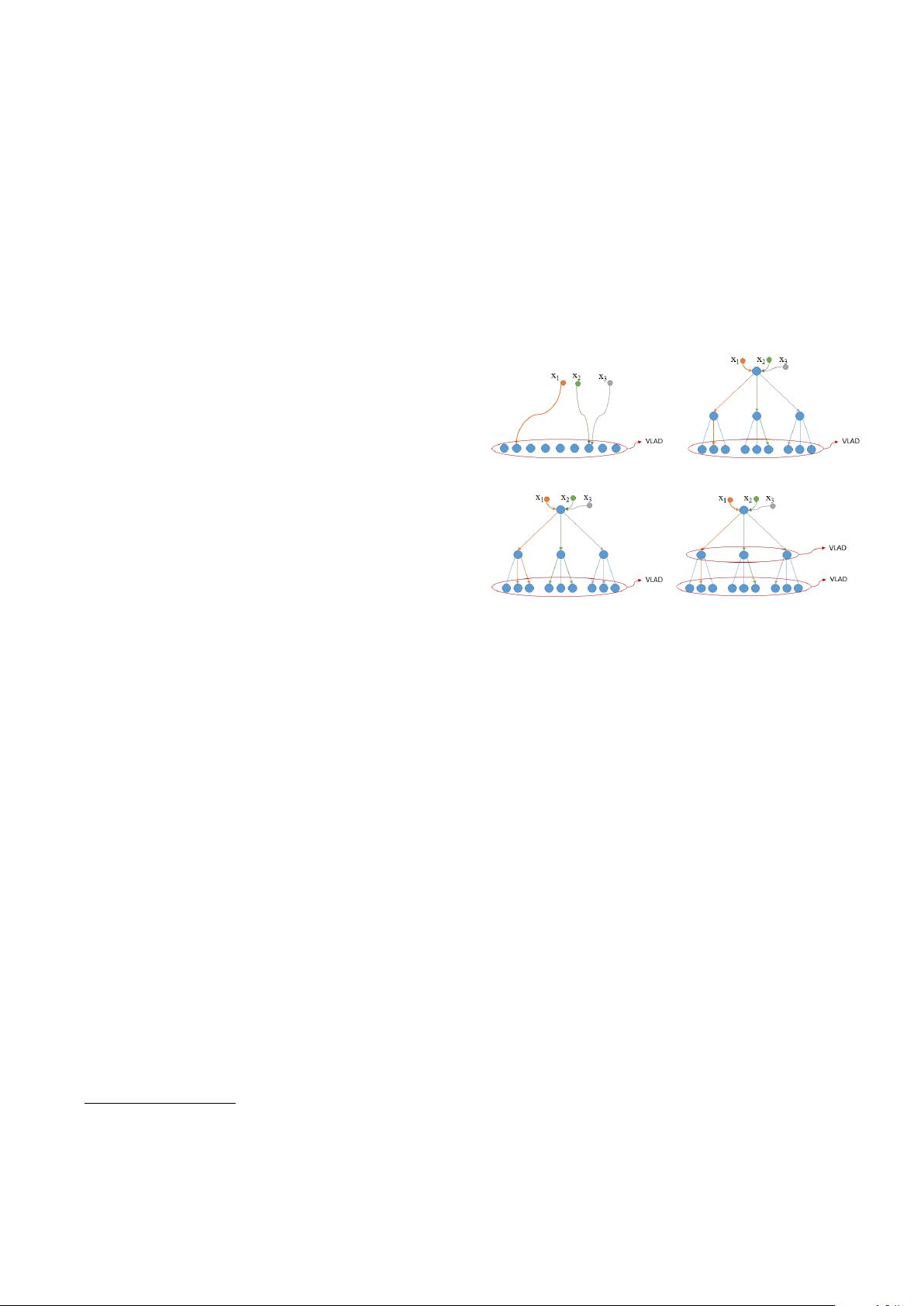
(a) Flat VLAD (b) Hierarchical VLAD
(c) Hierarchical VLAD + MA (d) Hierarchical Multi-VLAD
Fig. 1. Several VLAD schemes. (a) Flat VLAD. (b) Hierarchical
VLAD. (c) Hierarchical VLAD with Multi-assignment. (d) Hierar-
chical Multi-VLAD. x
1
, x
2
, x
3
refer to local features quantized to
centroids.
the state-of-the-art search performance at a much smaller vocabulary
[4][5][7].
Recent works have proposed to improve the VLAD represen-
tation by enhancing the residual statistics in the aggregation stage
after quantizing local features. For example, Tolias et al. [8] intro-
duced an aggregation approach that achieves orientation covariance
of residual statistics. J
´
egou et al. [9] presented democratic aggre-
gation to limit the interaction of unrelated local features in gener-
ating the residual vectors. Arandjelovic et al. [10] proposed intra
normalization of residual vectors to suppress bursty visual elements.
These improved aggregation strategies have shown promising result-
s. However, the descriptor discriminability of VLAD is yet limited
by the coarse quantization due to a small vocabulary.
An alternative solution is to directly increase the vocabulary
size, as a large vocabulary usually provides fine-grained partition
of feature space and improves the discriminability of centroids. For
instance, Tolias et al. [11] formulated image retrieval as a match
kernel framework and used a large vocabulary trained with flat k-
means, leading to state-of-the-art search accuracy. Unfortunately,
the computation cost with flat quantization is linearly increased with
the vocabulary size. This usually leads to slower VLAD extraction.
In this paper, we propose a hierarchical multi-VLAD to address
the problem of image retrieval using the state-of-the-art VLAD de-
scriptor with large vocabulary (see Fig. 1). Firstly, we adopt tree-
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-19 上传
2021-05-06 上传
2021-06-01 上传
2021-01-19 上传
252 浏览量
2013-03-10 上传

weixin_38696877
- 粉丝: 6
- 资源: 929
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
