关系型分布式数据库:演进、最佳实践与选型策略
版权申诉
91 浏览量
更新于2024-07-05
1
收藏 1.92MB PDF 举报
“关系型分布式数据库最佳实践.pdf”讨论了数据库从集中式到分布式的转变,以及在不同场景下选择分布式数据库的策略和技术要点。
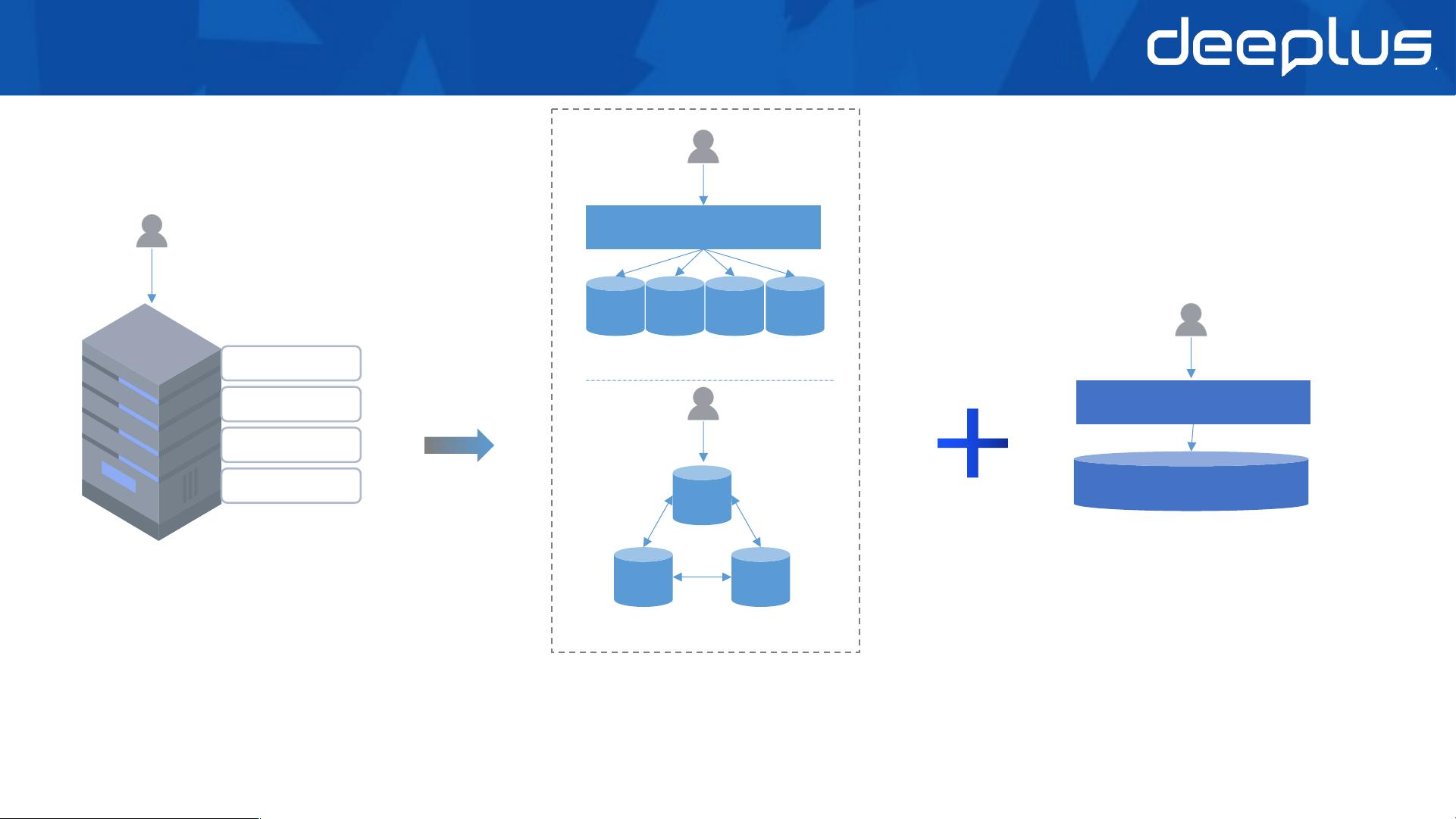
在数据库的发展历程中,从传统的单机数据库演进到分布式数据库,是为了应对高并发查询、事务处理、海量数据存储等挑战。传统的单机数据库在面临数据量增大、性能瓶颈时,会采用虚拟化计算层和云存储层来提升能力,但仍然受限于单机资源。因此,分布式数据库应运而生,分为两种主要类型:分布式数据库中间件和原生分布式数据库。
分布式数据库中间件是将现有数据库通过中间件进行水平扩展,适用于通用性强、特性全的场景,但存在单机资源限制和分布式一致性问题。而原生分布式数据库则设计为分布式架构,能够实现资源的线性扩展,处理高并发更新和海量数据存储,但需要解决分布式事务、一致性问题,且对云平台有较强依赖。
选择分布式数据库的场景通常包括:高并发查询、事务处理、海量在线数据存储、单表数据量大导致性能下降、实时复杂分析查询超时、国产化数据库改造和数据库异地容灾。针对这些场景,有多种解决方案,如只读副本、读写分离、热点缓存、数据垂直拆分、分布式数据库、数据归档、索引优化、流计算和预计算等。
关系型分布式数据库的最佳实践强调了平滑演进的重要性,例如,从单机数据库逐步过渡到分布式数据库,通过合理选择拆分键、保证分布式事务的一致性、支持在线DDL操作以及实现增量数据实时回流。此外,线性平滑扩容是关键,计算层可以通过无状态扩容轻松添加新节点,而存储层的扩容则需要考虑数据迁移,确保服务的连续性和数据的完整性。
在核心技术层面,分布式数据库需要处理的关键问题包括数据分区、负载均衡、分布式事务管理、分布式DDL操作和数据迁移。例如,通过分区策略(如哈希、范围分区)将大表拆分成多个小表,分散到多个节点上,同时保证分布式事务的ACID特性,实现高可用和高性能。
关系型分布式数据库最佳实践旨在提供一套全面的指南,帮助企业或开发者在面对业务增长和数据量爆炸时,能够有效地利用分布式数据库技术,实现系统的高效、稳定和可扩展。这涉及到数据库架构的选择、数据分布策略、事务处理机制、容灾方案等多个方面,是现代云时代数据库系统设计的重要参考。
视图
触发器
存储过程
事务
传统单机数据库
虚拟化计算层
云存储层
云原生数据库
中间件
1. 分布式数据库中间件
2. 原生分布式数据库
• 通用性强,特性全
• 可控数据规模性能优秀
• 受单机资源瓶颈制约
• 资源难以扩展
• 水平拆分场景性能优异
• 资源可线性扩展
• 需解决分布式事务、一致性
• 研发人员入门门槛高
• 计算存储分离
• 资源弹性伸缩
• 单机数据库特性强兼容
• 对云平台强依赖
Proxy
集群化
剩余19页未读,继续阅读
2023-01-08 上传
2022-07-14 上传
2021-08-03 上传
2021-10-10 上传
2021-10-10 上传
2021-08-08 上传

Build前沿
- 粉丝: 791
- 资源: 2125
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
